إصدار Claude Opus 4.8: النموذج الأكثر كفاءة من Anthropic حتى الآن

أطلقت شركة Anthropic للتو Claude Opus 4.8 — أسرع، وأكثر صدقًا، وأفضل في أداء المهام الوكيلة. إليك كل ما هو جديد ولماذا يهم المطورين.

أصدرت شركة Anthropic هذا الأسبوع نموذج Claude Opus 4.8. يُعد هذا النموذج الأكثر كفاءة من بين النماذج المتاحة للعامة، وهو مبني على Opus 4.7 مع تحسينات في البرمجة، والاستدلال، والمهام الوكيلة، والصدق. بقي السعر كما هو: 5 دولارات لكل مليون رمز إدخال، و25 دولارًا لكل مليون رمز إخراج.
إليك ما تغير ولماذا يهمّ المطورين الذين يبنون فوقه.
ما الذي تغيّر منذ Opus 4.7؟
فيما يلي أبرز التغييرات الفعلية:
1. حكم وصدق أفضل
أصبح Opus 4.8 أقل احتمالًا بكثير لطرح ادعاءات غير مدعومة أو تمرير أخطاء في الشيفرة دون ملاحظة. تُظهر تقييمات Anthropic أنه أقل احتمالًا أربع مرات من سابقه للسماح بمرور أخطاء دون الإشارة إليها. هذا النوع من التحسين مهم عندما تعتمد على نموذج للعمل بشكل مستقل.
أفاد المختبرون الأوائل بأنه يطرح الأسئلة الصحيحة، ويكتشف أخطاءه بنفسه، ويعترض عندما لا يبدو الخطة منطقية.
2. أداء أقوى في المهام الوكيلة
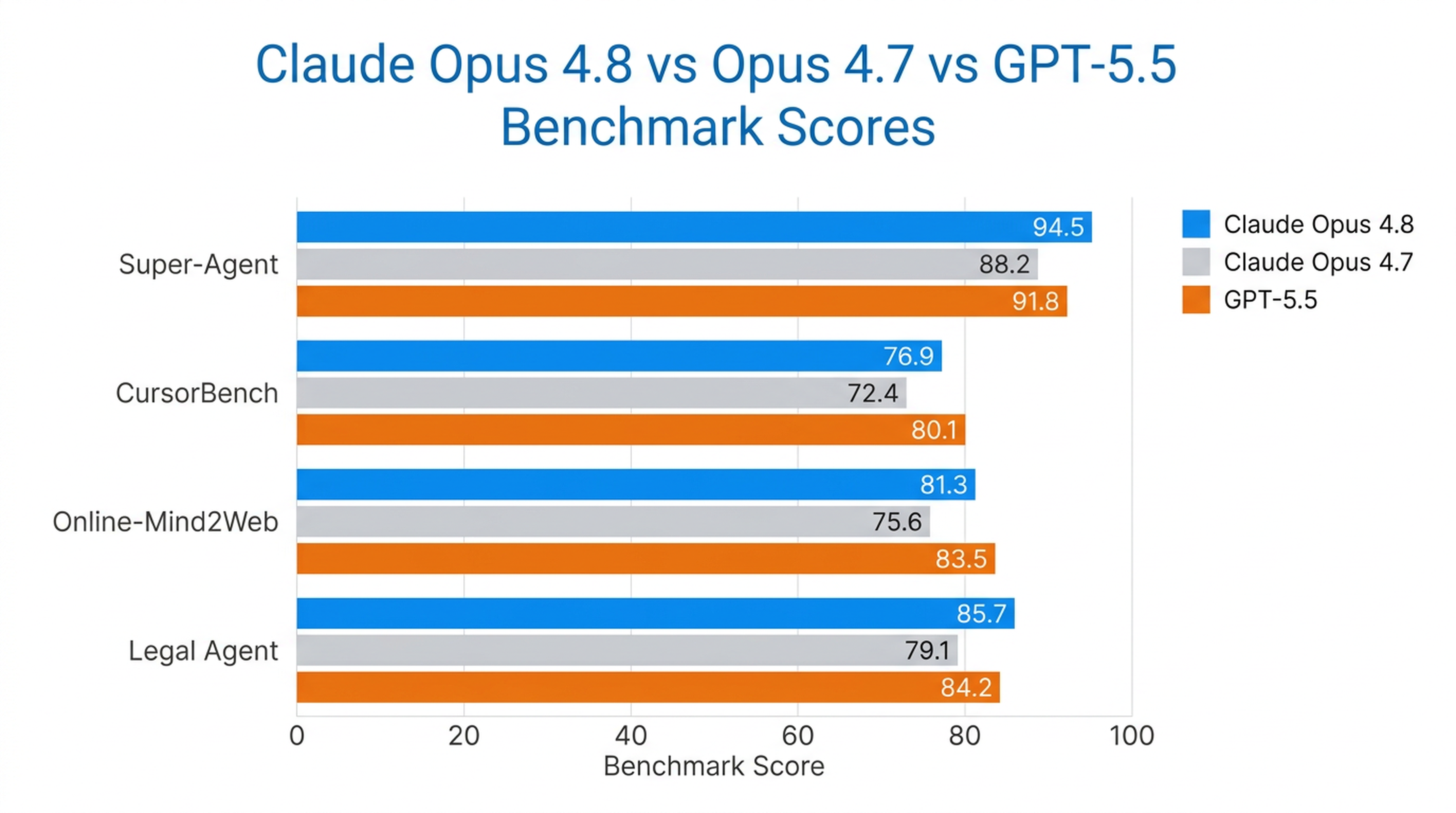
يُعد Opus 4.8 النموذج الوحيد الذي أكمل جميع الحالات بشكل كامل في اختبار Super-Agent الخاص بـ Anthropic، متفوقًا على نماذج Opus السابقة و GPT-5.5 بنفس التكلفة. في اختبار CursorBench، يتفوق على إصدارات Opus السابقة في جميع مستويات الجهد، مع استخدام خطوات أقل لاستدعاء الأدوات لنفس مستوى الذكاء.
كما أنه أقوى نموذج في استخدام الحاسوب ووكلاء المتصفح قامت Anthropic باختباره، حيث سجّل 84٪ في Online-Mind2Web.
3. استدعاء أدوات أسرع وأكثر كفاءة
أصبح النموذج أقل ميلًا لتخطي عملية استدعاء أداة يتطلبها سير المهمة، وهي مشكلة كانت معروفة في Opus 4.7. أيضًا، تظل التتبعات الطويلة في المهام الوكيلة مركّزة على الهدف مع عدد أقل من الانحرافات بعد ضغط السياق.
4. تفكير تكيفي يتكيّف فعليًا
عند تفعيل التفكير التكيفي، يقرر Opus 4.8 في كل خطوة ما إذا كانت الحاجة إلى الاستدلال قائمة. الأسئلة البسيطة تحصل على إجابات مباشرة، والمشكلات المعقدة تحصل على تحليل قبل الإجابة. يؤدي ذلك إلى تقليل الرموز المهدورة مقارنةً بـ Opus 4.7.
ميزات جديدة تستحق المعرفة
التحكم في الجهد — متاح الآن في جميع الخطط
تتيح ميزة جديدة بجانب محدد النموذج للمستخدمين اختيار مقدار الجهد الذي يبذله Claude في الاستجابة. يعتمد Opus 4.8 افتراضيًا على جهد عالٍ، مع خيارات إضافي وأقصى للمهام الأصعب. كما تم رفع حدود المعدل في Claude Code لاستيعاب استخدام الرموز الأعلى.
الوضع السريع — سرعة 2.5× وتكلفة أقل
الوضع السريع متاح الآن لـ Opus 4.8 كتجربة بحثية على واجهة Claude API. يُقدّم ما يصل إلى 2.5× رموز إخراج أكثر في الثانية الواحدة وبتكلفة أقل بثلاث مرات مقارنة بالنماذج السابقة.
رسائل النظام أثناء المحادثة
تقبل واجهة Messages API الآن إدخالات role: "system" داخل مصفوفة الرسائل، بحيث يمكنك تحديث تعليمات Claude أثناء تنفيذ المهمة دون كسر ذاكرة التخزين المؤقت للموجه — مفيدة عند تغيّر الأذونات أو السياق أثناء دورة المهام الوكيلة.
تقليل الحد الأدنى لذاكرة التخزين المؤقت للموجهات
انخفض الحد الأدنى لطول الموجه القابل للتخزين المؤقت إلى 1,024 رمزًا. الموجهات التي كانت قصيرة جدًا للتخزين في Opus 4.7 تنشئ الآن إدخالات تخزين مؤقت دون أي تعديل في الشيفرة.
معايير الأداء في العالم الحقيقي
| المعيار | أداء Opus 4.8 |
|---|---|
| Super-Agent | أكمل جميع الحالات من البداية إلى النهاية (النموذج الوحيد الذي فعل ذلك) |
| CursorBench | يتفوق على جميع نماذج Opus السابقة في كل مستوى جهد |
| Online-Mind2Web | 84٪ (أقوى نموذج تم اختباره) |
| Legal Agent Benchmark | أعلى نتيجة مسجلة؛ أول نموذج يتجاوز 10٪ إجمالًا |

يتفوق Opus 4.8 في المجالات التي تتطلب استقلالية طويلة المدى — وكلاء البرمجة، وكلاء البحث، سير العمل القانوني، وأعمال المعرفة في المؤسسات.
التسعير — لم يتغير عن Opus 4.7
| الوضع | الإدخال | الإخراج |
|---|---|---|
| قياسي | $5 / لكل 1M رمز | $25 / لكل 1M رمز |
| سريع | $10 / لكل 1M رمز | $50 / لكل 1M رمز |
نفس سعر Opus 4.7، مع أداء أفضل. معرف النموذج في واجهة API هو claude-opus-4-8. وهو يدعم نافذة سياق بمقدار 1M رمز وإخراج بحد أقصى 128k رمز.
ما القادم: نماذج فئة Mythos
أشارت Anthropic أيضًا إلى فئة جديدة من النماذج تتمتع بـ "ذكاء أعلى من Opus". تستخدم عدد قليل من المؤسسات حاليًا Claude Mythos Preview لأعمال الأمن السيبراني عبر مشروع Glasswing. تخطط الشركة لإتاحة نماذج فئة Mythos لجميع العملاء خلال الأسابيع القادمة، بمجرد اكتمال إجراءات الأمان.
لماذا تنوّع النماذج مهم
تُطلَق نماذج ذكاء اصطناعي جديدة كل أسبوع تقريبًا. بالنسبة للمطورين الذين يبنون عليها، السؤال الحقيقي ليس أي نموذج هو "الأفضل"، بل أي نموذج أنسب لكل مهمة، وكيف يمكن التبديل بينها بسلاسة.
هذا هو التحدي الذي تتصدى له Felo AI. إلى جانب محرك البحث المعزز بالذكاء الاصطناعي الذي يستخدم نماذج متقدمة لتقديم إجابات فورية، توفر Felo أيضًا ملعب LLM حيث يمكنك استدعاء النماذج واختبارها ومقارنة نتائجها في مكان واحد. لا حاجة لإدارة مفاتيح API أو التنقل بين لوحات تحكم متعددة. فقط اختر نموذجك، شغّل الموجه، وشاهد الأداء.
إذا كنت تقيم النماذج لدمجها في سير عملك، أو تبحث فقط عن استكشاف ما هو متاح، فوجودها كلها في واجهة واحدة يجعل عملية المقارنة أسهل بكثير.
جرّب Felo AI مجانًا → https://felo.ai
تتوفر هذه المقالة أيضًا باللغات التالية: English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, Français, Русский, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Türkçe, Italiano, ไทย, Español, বাংলা and Português.