الذكاء الاصطناعي لتحويل النص إلى فيديو في عام 2026: دليل إخباري كامل لكل أداة ولكل إنجاز

نظرة شاملة على مشهد الذكاء الاصطناعي لتحويل النص إلى فيديو في عام 2026 — من OpenAI Sora إلى Google Veo، وRunway Gen-3 إلى Kling، وكيف تتبع Felo Video نهجاً مختلفاً جذرياً.
إذا كنت تتابع أخبار الذكاء الاصطناعي هذا العام، فقد لاحظت شيئاً واضحاً: مجال تحويل النص إلى فيديو انتقل من مرحلة "الوعد" إلى "الازدحام" في حوالي اثني عشر شهراً فقط.
أخيراً، أطلقت OpenAI أداة Sora للعامة. وأطلقت Google الإصدار الثالث من Veo بجودة سينمائية جعلت نصف الإنترنت يتوقف لمشاهدته. وتواصل Runway إصدار تحديثات Gen-3، كما أن أدوات مثل Kling وLuma Dream Machine وPika وأكثر من عشرة منافسين آخرين دخلوا جميعاً السباق.
لقد تغير السؤال من "هل يستطيع الذكاء الاصطناعي توليد فيديو؟" إلى "أي أداة يمكنني استخدامها فعلاً؟"
لكن هناك سؤالاً ثالثاً لم يطرحه أحد بعد: هل نستخدم نوع الأداة الصحيح لتحويل النص إلى فيديو بحسب حاجتنا الفعلية؟

مشهد الذكاء الاصطناعي لتحويل النص إلى فيديو في عام 2026
إليك أين وصلت الأمور حالياً.
OpenAI Sora
كانت Sora الأداة التي أطلقت الموجة الحالية. بعد أشهر من النسخة التجريبية المغلقة، فتحتها OpenAI للعامة بأسعار متعددة المستويات. الجودة لا يمكن إنكارها — مشاهد واقعية للغاية، شخصيات متسقة، وفيزياء منطقية إلى حد كبير. لكن Sora صُمّمت لغرض واحد: توليد لقطات سينمائية من أوصاف نصية. تكتب مثلاً: "كلب من نوع جولدن ريتريفر يجري في حقل عند غروب الشمس" وستحصل على ذلك بالضبط.
لكن ما لن تحصل عليه هو فيديو لمنتجك أو تقريرك أو تدوينتك. Sora لا "تفهم" محتواك. إنها تولد مشاهد من مطالبات نصية، فقط لا غير.
Google Veo 3
رفعت Google Veo 3 مستوى المنافسة. أُعلن عنها مع توليد صوتي مدمج — فالفيديو لا يبدو حقيقياً فحسب، بل يُسمع أيضاً كأنه حقيقي. الجودة السينمائية ربما هي الأفضل في السوق. وكما هو الحال مع Sora، تعتمد Veo على الأوامر النصية: صف المشهد، وستحصل على الفيديو. الاندماج مع منظومة Google يعني إمكانيات استخدام مع YouTube وWorkspace، لكن المبدأ نفسه — إدخال أمر نصي، والحصول على فيديو سينمائي.
Runway Gen-3 Alpha
كانت Runway هي الأداة الأساسية في مجال الفيديو بالذكاء الاصطناعي منذ فترة طويلة. يقدم Gen-3 Alpha جودة حركة قوية، وتوافقاً جيداً مع المطالبات، وأدوات متنامية تشمل من صورة إلى فيديو ومن فيديو إلى فيديو. إنها أداة يفضلها المبدعون، ويظهر ذلك في دقتها. لكنها تظل أداة توليدية: تصف ما تريد رؤيته، وهي تولده. لا تتعامل مع المحتوى الواقعي للمستخدم.
Kling AI
ظهرت Kling من الصين بجودة حركة مدهشة وخطة مجانية جعلتها تحظى بشعبية فورية. النتائج قوية بصرياً، خصوصاً في تحريك الشخصيات والمشاهد المعقدة. وكغيرها، تعتمد على الأوامر النصية — صف، ولّد، وكرّر.
Luma Dream Machine
تميزت Luma Dream Machine بسرعة التوليد وجودة مناسبة بسعر معقول. إنها واحدة من أسرع الأدوات في السوق، وهو أمر مهم حين تختبر عشرات المطالبات النصية. تتبع النموذج نفسه: من نص إلى فيديو.
Pika
تركز Pika على التحكم الإبداعي — مثل نقل الأنماط، وفرش الحركة، والتحرير الجزئي في مناطق محددة. إنها أكثر الأدوات "شبيهة بالمحررات" بين أدوات التوليد، إذ تمنحك تحكماً دقيقاً بما يتغير في المشهد. لكنها تبقى أداة توليدية، وليست أداة تفسير للمحتوى.
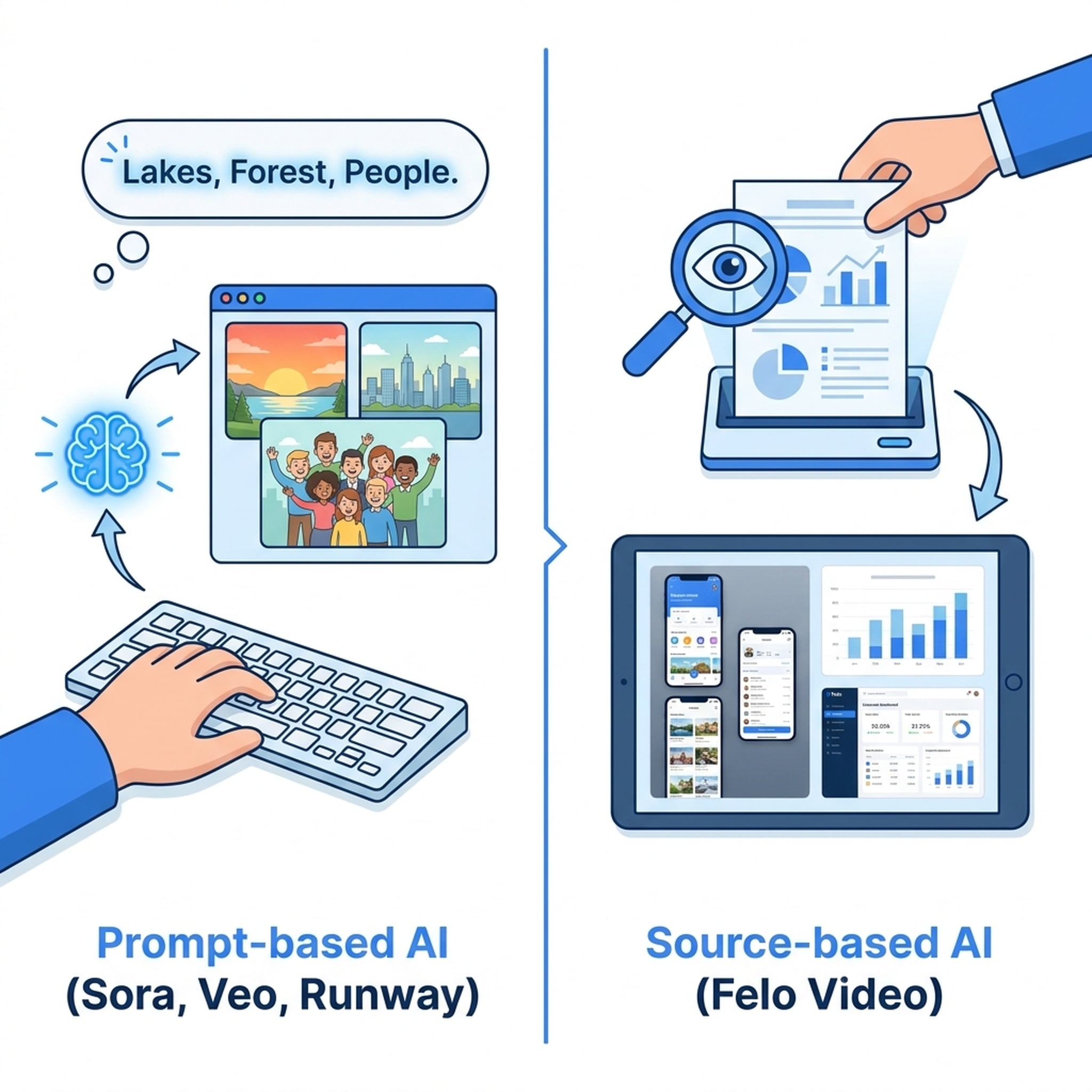
المشكلة التي لا يتحدث عنها أحد
كل أداة رئيسية لتحويل النص إلى فيديو في عام 2026 تتبع النموذج نفسه:
أمر نصي → فيديو توليدي.
تصف ما تريد، والذكاء الاصطناعي "يتخيله". النتيجة مبهرة بصرياً، لكنها مختلقة.
يعمل هذا النهج جيداً للمشاهد الإبداعية أو اللقطات السينمائية، لكنه لا يعمل في الحالات الفعلية التي يحتاج فيها الناس الفيديو لأغراض عملية، مثل:
- تحويل مقالك المنشور إلى فيديو يمكن مشاركته
- تحويل صفحة منتجك إلى إعلان ترويجي
- جعل تقريرك الشهري عرضاً تقديمياً
- تحويل عرض التدريب إلى فيديو تعليمي
- تكييف المستندات التقنية إلى فيديو توضيحي
في هذه الحالات، عنق الزجاجة ليس في توليد الصور، بل في فهم المحتوى الأصلي — المقال أو التقرير أو الصفحة أو الشرائح — وتحويل ذلك إلى فيديو يحافظ على معلوماتك الحقيقية، ورسوماتك البيانية، ولقطات شاشتك.
وهنا يجب أن يتجه النقاش التالي حول الذكاء الاصطناعي لتحويل النص إلى فيديو.
نهج مختلف: البدء من المحتوى وليس من الأوامر النصية
تتبع Felo Video نهجاً مختلفاً جذرياً. بدلاً من مطالبتك بكتابة أمر نصي يصف الفيديو المطلوب، فإنها تقرأ المحتوى الفعلي لديك وتولد الفيديو منه مباشرة.
الاختلاف هيكلي:
| الذكاء الاصطناعي التقليدي للنص إلى فيديو | الذكاء الاصطناعي القائم على المحتوى | |
|---|---|---|
| الإدخال | أمر نصي يصف المشهد | محتوى فعلي: مقالات، تقارير، شرائح، صفحات ويب |
| العملية | توليد صور خيالية | فهم واستخراج المعلومات من المحتوى |
| المشاهد | من إنتاج الذكاء الاصطناعي، أشبه بلقطات جاهزة | لقطاتك الحقيقية، ورسومك البيانية، وواجهتك |
| حالات الاستخدام | المشاهد الإبداعية واللقطات السينمائية | محتوى الأعمال، التعليم، التسويق، التوثيق |
| النتيجة | سينمائي لكنه عام | محدد لمحتواك وعلامتك التجارية |
ليس الهدف هنا استبدال Sora أو Veo — فهما تحلان مشكلة مختلفة. لكن إذا كانت حاجتك الحقيقية هي تحويل المحتوى الموجود لديك إلى فيديو، وليس توليد مشاهد خيالية من أوصاف، فالنموذج القائم على الأوامر النصية لم يكن يوماً الأداة المناسبة لذلك.
لماذا يهم الآن الفيديو القائم على المحتوى
ثلاثة اتجاهات تلتقي حالياً:
1. فائض المحتوى. تنتج الفرق كماً هائلاً من المحتوى المكتوب — مقالات، تقارير، تحديثات منتجات، مواد تدريبية. ومعظمها لا يحصل على نسخة فيديو بسبب التكلفة العالية للإنتاج. الذكاء الاصطناعي القائم على المحتوى يسد هذه الفجوة.
2. التوزيع المعتمد على الفيديو. المنصات الاجتماعية تفضل الفيديو: LinkedIn وTwitter وTikTok وYouTube — الفيديو يحصل على وصول أوسع وتفاعل أكبر. بينما يبقى المحتوى المكتوب دون استخدام إمكاناته الكاملة في الانتشار.
3. الطلب على التعدد اللغوي. تحتاج الفرق العالمية إلى محتوى بلغات متعددة. ترجمة الفيديوهات عادةً تتطلب إعادة إنتاج كامل — أما مع الذكاء الاصطناعي القائم على المحتوى، يمكن توليد الفيديو نفسه بنسخ متعددة تلقائياً بالسرد والترجمة المناسبة.
المقارنة المفيدة فعلاً
عند تقييم أدوات الذكاء الاصطناعي لتحويل النص إلى فيديو في عام 2026، السؤال الأهم ليس "أي أداة تنتج أفضل الصور؟" بل "ما الذي أريد صناعته؟"
إذا كنت تحتاج إلى مشاهد سينمائية — مفاهيم منتجات، لقطات مزاجية، مشاهد إبداعية — استخدم Sora أو Veo 3 أو Runway Gen-3. فهي الأفضل فيما تفعله.
أما إذا كنت تريد تحويل المحتوى الموجود لديك إلى فيديو — مقالات، تقارير، عروض تقديمية، صفحات منتجات — فأنت بحاجة إلى أداة قائمة على المحتوى مثل Felo Video. الأدوات التوليدية لا تستطيع ذلك لأنها لا تقرأ محتواك، بل تولد استناداً إلى أوصاف فقط.
ما الذي تفعله Felo Video بشكل مختلف
لا تطلب منك Felo Video إدخال أمر نصي، بل تطلب محتواك:
- ألصق رابطاً — لمقال مدونتك أو صفحة منتجك أو مقالتك
- ارفع ملفاً — تقارير PDF أو عروض PowerPoint أو Keynote
- أضف نصاً — ملاحظات الإطلاق، أو النصوص المكتوبة، أو منشورات التواصل
تقرأ Felo Video المادة، وتفهم السياق، وتستخرج النقاط الأساسية، ثم تولد فيديو يستخدم أصولك الحقيقية — لقطات الشاشة، الرسوم البيانية، واجهة المنتج، المخططات. يتم توليد السرد والترجمة والحركة والموسيقى تلقائياً، بينما يأتي المحتوى منك.
النسخة الأولى تظهر خلال 10 إلى 20 دقيقة فقط. بعد ذلك يمكنك المراجعة والتعديل والتصدير.
الخلاصة
مجال الذكاء الاصطناعي لتحويل النص إلى فيديو في عام 2026 مذهل حقاً. الأدوات التوليدية تتحسن كل شهر. لكن هناك فئة كاملة من إنشاء الفيديو لم تُصمم هذه الأدوات لحلها: تحويل المحتوى الحقيقي والغني بالمعلومات إلى صيغة فيديو.
وهذا هو الفراغ الذي تملؤه Felo Video — ليس بمنافسة Sora في الجودة السينمائية، بل بحل مشكلة لم تعالجها Sora أو Veo أو Runway أو Kling حتى الآن.
محتواك موجود بالفعل. كل ما يحتاجه هو طريق إلى الفيديو.
تتوفر هذه المقالة أيضًا باللغات التالية: English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, Français, Русский, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Türkçe, Italiano, ไทย, Español, বাংলা and Português.