AI Search Engine Fuzzy Question Evaluation Report (v1.3)

This article evaluates the performance of several AI search engines in handling "fuzzy query questions." Felo AI performed the best with an accuracy rate of 80%, followed by Perplexity Pro. The article analyzes the strengths and weaknesses of each product and provides specific case studies for illustration. The evaluation data and results have been made open source, offering valuable insights for the development of AI search engines.
I. Conclusion
In today's information-saturated era, as user queries become more complex, the performance gap between AI Search systems becomes increasingly apparent. This is especially true when dealing with software configurations, multiple data sources, information not readily available online, or date-related queries. We refer to these challenging queries as "ambiguous question searches." In this evaluation, we comprehensively tested several popular AI Search engines, including Perplexity Basic, Perplexity Pro, GenSpark, Felo AI, iAsk, and You.com, focusing on this type of query.
After a series of rigorous tests, we concluded:
- Felo AI emerged as the standout performer, demonstrating exceptional ability in handling ambiguous queries. It led the pack with an impressive 80% accuracy rate, efficiently processing multi-source data and providing detailed, reliable answers to complex queries, much like an experienced expert.
- Perplexity Pro secured second place with a 70% score, showing resilience in tackling some complex questions.
- iAsk performed adequately, achieving a 60% accuracy rate and occasionally providing effective answers to ambiguous questions.
- Perplexity Basic, GenSpark, and You.com underperformed in this evaluation. Their language models showed clear weaknesses in understanding and processing ambiguous queries, achieving accuracy rates of 55%, 45%, and 35% respectively, which were less than satisfactory.
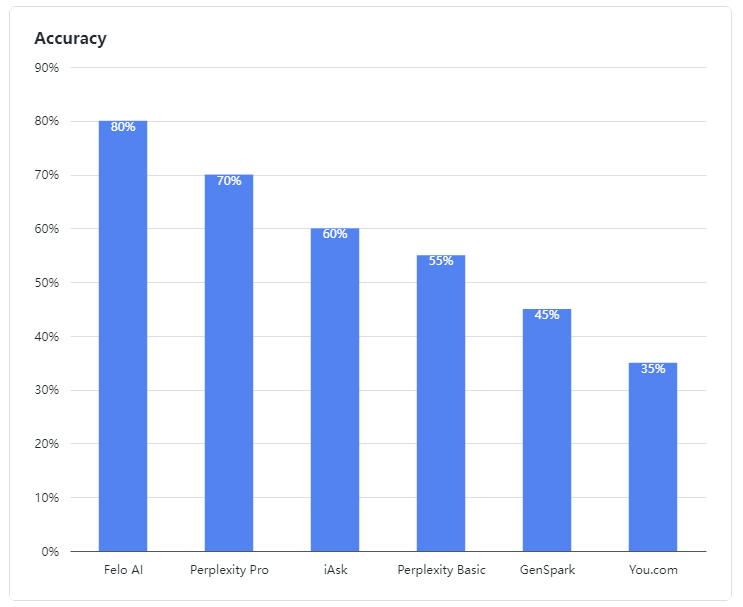
Figure 1: Accuracy rates of evaluated products
II. Evaluation Data
In our assessment, ambiguous questions were defined as those involving software configurations, multiple data sources, information not available online, or date-related information. LLMs often piece together content from multiple sources to answer such questions.
Our ambiguous question test cases are open-source:
👉 Test cases: https://github.com/sparticleinc/ASEED/blob/main/datasets/ambiguity_search.csv
👉 Test results: https://github.com/sparticleinc/ASEED/tree/main/evaluations/promptfoo/ambiguity_search
III. Case Analysis
👉 Question: Where will the next Olympic Games be held?
Ground truth: The 2028 Summer Olympic Games, also known as the Games of the XXXIV Olympiad, will be held in Los Angeles, USA.
Comment: Due to the abundance of online information stating that the next Olympics will be held in Paris, France in 2024, all products except Felo AI answered incorrectly.

