Claude Opus 4.8 Released: Anthropic's Most Capable Model Yet

Anthropic just released Claude Opus 4.8 — faster, more honest, and better at agentic tasks. Here's everything new and why it matters for developers.

Anthropic released Claude Opus 4.8 this week. It's the most capable model they've made generally available, building on Opus 4.7 with improvements across coding, reasoning, agentic tasks, and honesty. The price stays the same: $5 per million input tokens, $25 per million output tokens.
Here's what changed and what matters for developers building on top of it.
What Changed Since Opus 4.7?
Here's what actually changed:
1. Better Judgment and Honesty
Opus 4.8 is significantly less likely to make unsupported claims or let code flaws slip by unremarked. Anthropic's evals show it's roughly four times less likely than its predecessor to allow bugs in its own code to pass without flagging them. That's the kind of improvement that matters when you're trusting a model to work autonomously.
Early testers reported that it asks the right questions, catches its own mistakes, and pushes back when a plan doesn't make sense.
2. Stronger Agentic Performance
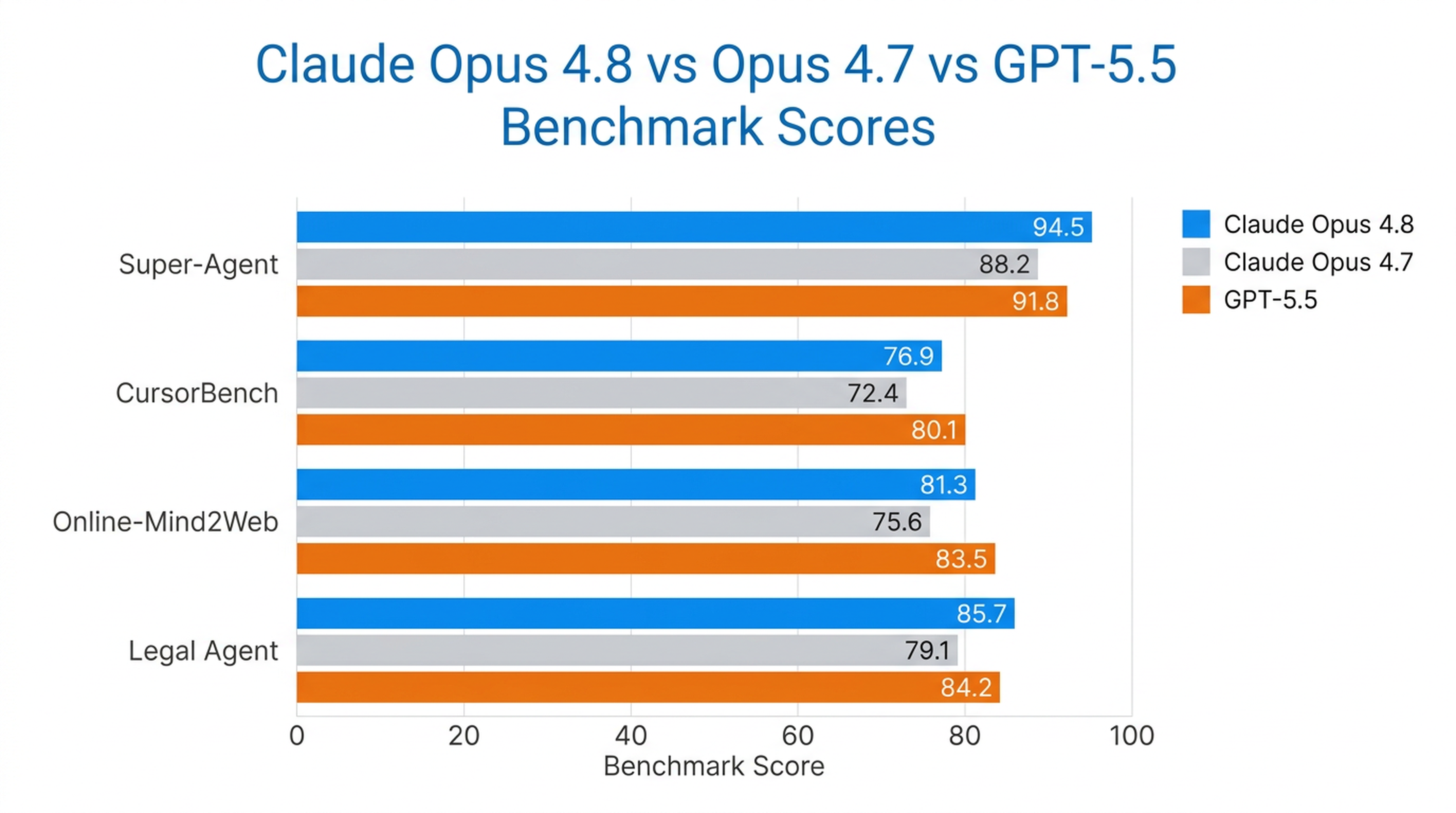
Opus 4.8 is the only model to complete every case end-to-end on Anthropic's Super-Agent benchmark, beating prior Opus models and GPT-5.5 at cost parity. On CursorBench, it exceeds previous Opus versions across every effort level, using fewer tool-calling steps for the same intelligence.
It's also the strongest computer-use and browser-agent model Anthropic has tested, scoring 84% on Online-Mind2Web.
3. Faster, More Efficient Tool Calling
The model is less likely to skip a tool call that a task requires, which was a known pain point with Opus 4.7. Long agentic traces also stay on task with fewer derailments after context compaction.
4. Adaptive Thinking That Actually Adapts
With adaptive thinking enabled, Opus 4.8 decides per turn whether reasoning is needed. Simple lookups get direct answers. Complex problems get reasoning before the answer. Fewer wasted tokens compared to Opus 4.7.
New Features Worth Knowing
Effort Control — Now on All Plans
A new control alongside the model selector lets users choose how much effort Claude puts into a response. Opus 4.8 defaults to high effort, with extra and max options for harder tasks. Rate limits in Claude Code have been increased to handle the higher token usage.
Fast Mode — 2.5x Speed, Lower Cost
Fast mode is now available for Opus 4.8 as a research preview on the Claude API. It delivers up to 2.5× higher output tokens per second at three times cheaper cost than previous models.
Mid-Conversation System Messages
The Messages API now accepts role: "system" entries inside the messages array. You can update Claude's instructions mid-task without breaking the prompt cache — useful when permissions or context change during an agentic loop.
Lower Prompt Cache Minimum
The minimum cacheable prompt length dropped to 1,024 tokens. Prompts that were too short to cache on Opus 4.7 now create cache entries without any code changes.
Real-World Benchmarks
| Benchmark | Opus 4.8 Performance |
|---|---|
| Super-Agent | All cases completed end-to-end (only model to do so) |
| CursorBench | Exceeds all prior Opus models at every effort level |
| Online-Mind2Web | 84% (strongest tested model) |
| Legal Agent Benchmark | Highest score recorded; first model to break 10% overall |

Opus 4.8 is strongest where long-horizon autonomy matters — coding agents, research agents, legal workflows, and enterprise knowledge work.
Pricing — Unchanged from Opus 4.7
| Mode | Input | Output |
|---|---|---|
| Standard | $5 / 1M tokens | $25 / 1M tokens |
| Fast | $10 / 1M tokens | $50 / 1M tokens |
Same price as Opus 4.7, with better performance. The model ID on the API is claude-opus-4-8. It supports the 1M token context window and 128k max output tokens.
What's Next: Mythos-Class Models
Anthropic also hinted at a new class of model with "even higher intelligence than Opus." A small number of organizations are already using Claude Mythos Preview for cybersecurity work through Project Glasswing. The company plans to bring Mythos-class models to all customers in the coming weeks, once safeguards are in place.
Why Model Diversity Matters
New AI models ship every week now. For developers building on top of them, the real question isn't which model is "the best" — it's which model is right for which task, and how to switch between them without friction.
That's the problem Felo AI tackles. Beyond its AI-powered search that pulls from advanced models for real-time answers, Felo offers an LLM Playground where you can call, test, and compare outputs from a wide range of leading models in one place. No juggling API keys, no switching between dashboards. Just pick a model, run your prompt, and see how it performs.
If you're evaluating models for your workflow, or just curious about what's out there, having them all in one interface makes the comparison process a lot less painful.
Try Felo AI for Free → https://felo.ai