Felo AI's groundbreaking achievement: SimpleQA benchmark test accuracy of 91.2%, leading a new standard in AI search

Felo AI has made groundbreaking progress in the SimpleQA benchmark test, leading the AI search field with an accuracy of 91.2%. Learn how innovative technologies like cross-language query rewriting enhance the search experience.
Revolutionizing AI Search Engines with Unmatched Accuracy
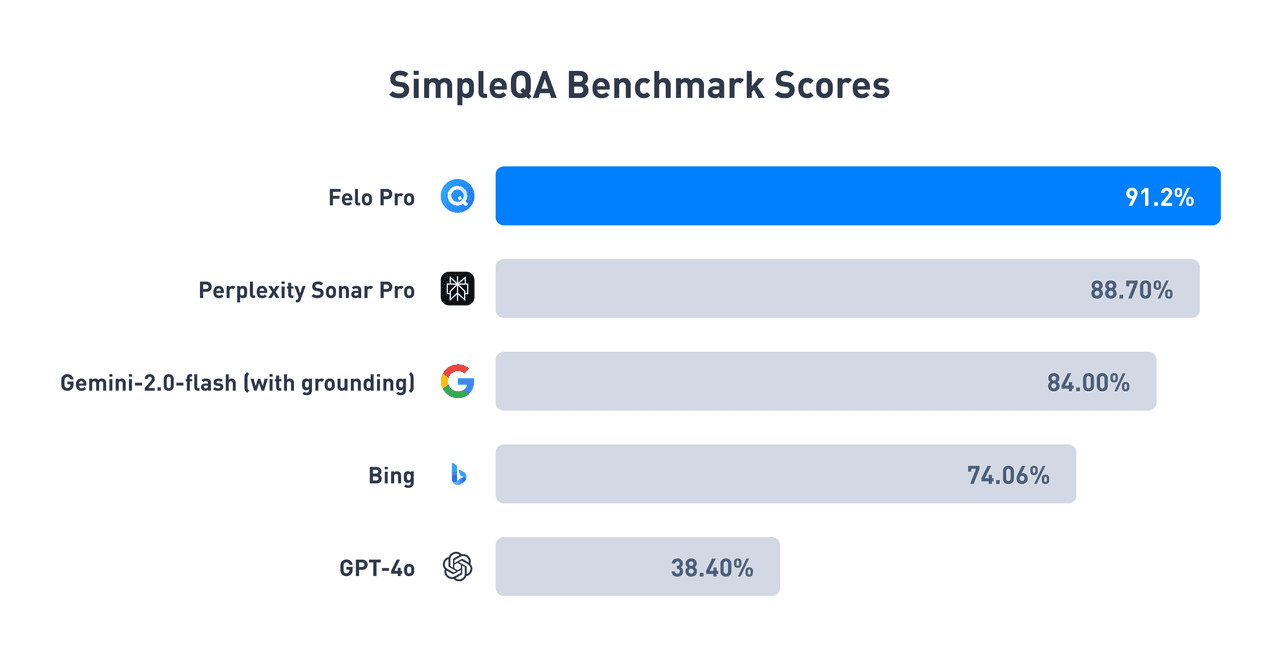
We are excited to announce that Felo has surpassed all competitors in the latest SimpleQA benchmark test. SimpleQA is a key test developed by OpenAI to evaluate the factual accuracy in AI question answering. With an impressive 91.2% accuracy rate, Felo Pro (Fast Mode) sets a new benchmark for AI search engines, significantly outperforming competitors like Perplexity and Gemini.
SimpleQA Benchmark Test: The Touchstone for AI Search Engines
The SimpleQA benchmark test, developed by OpenAI, is designed to measure the effectiveness of AI systems in answering concise factual questions using web data. Unlike traditional search metrics, SimpleQA focuses on reducing hallucination issues in AI systems by emphasizing the precision and reliability of facts—an ongoing challenge in the AI field. Felo's outstanding performance in this benchmark test demonstrates our commitment to providing cutting-edge solutions for AI search engines.
Testing Methodology: A Rigorous Evaluation Framework
Felo's evaluation of the SimpleQA benchmark test employs a standardized framework to ensure fairness and transparency. The methodology includes the following steps:
- Questions: Directly submitting questions from the SimpleQA dataset to Felo.
- Answer Generation: Generating answers using Felo Pro (Fast Mode).
All tests were conducted using the same set of questions and scoring criteria defined in the original SimpleQA protocol, ensuring fair comparisons among all participants.
Test Results: Felo Achieves Industry-Leading Accuracy
The results of the SimpleQA benchmark test highlight Felo's leading position in the field of AI intelligent search:
We have open-sourced Felo's test results, and you can visit here for more details.
What Makes Felo Unique?
The exceptional performance of Felo in the SimpleQA benchmark test is attributed to its innovative architecture and design, with key differentiators including:
- Advanced Cross-Language Query Rewriting Felo intelligently breaks down the original query into more granular sub-queries and even selects the most appropriate language context for retrieval based on user questions, optimizing these sub-queries for traditional search engines and RAG systems. This enables Felo to retrieve more relevant web pages.
- Hybrid Indexing Technology Felo employs a hybrid retrieval technique that combines keyword and semantic search, applying model-aware semantic compression to web content, allowing Felo to remove irrelevant noise while retaining key factual density. This ensures that the LLM (Large Language Model) receives only the most relevant and high-quality information.
- Retrieval-Focused Training Unlike general search engines, Felo specifically tailors its ranking model tuning to the unique way large language models process information, having developed 7 proprietary LLMs to provide more accurate, context-aware search results.