Try DeepSeek V4 Free on Felo LLM Playground

Felo LLM Playground adds DeepSeek V4-Pro and V4-Flash on launch day. Chat with the trillion-parameter open-source model for free — no API key needed.
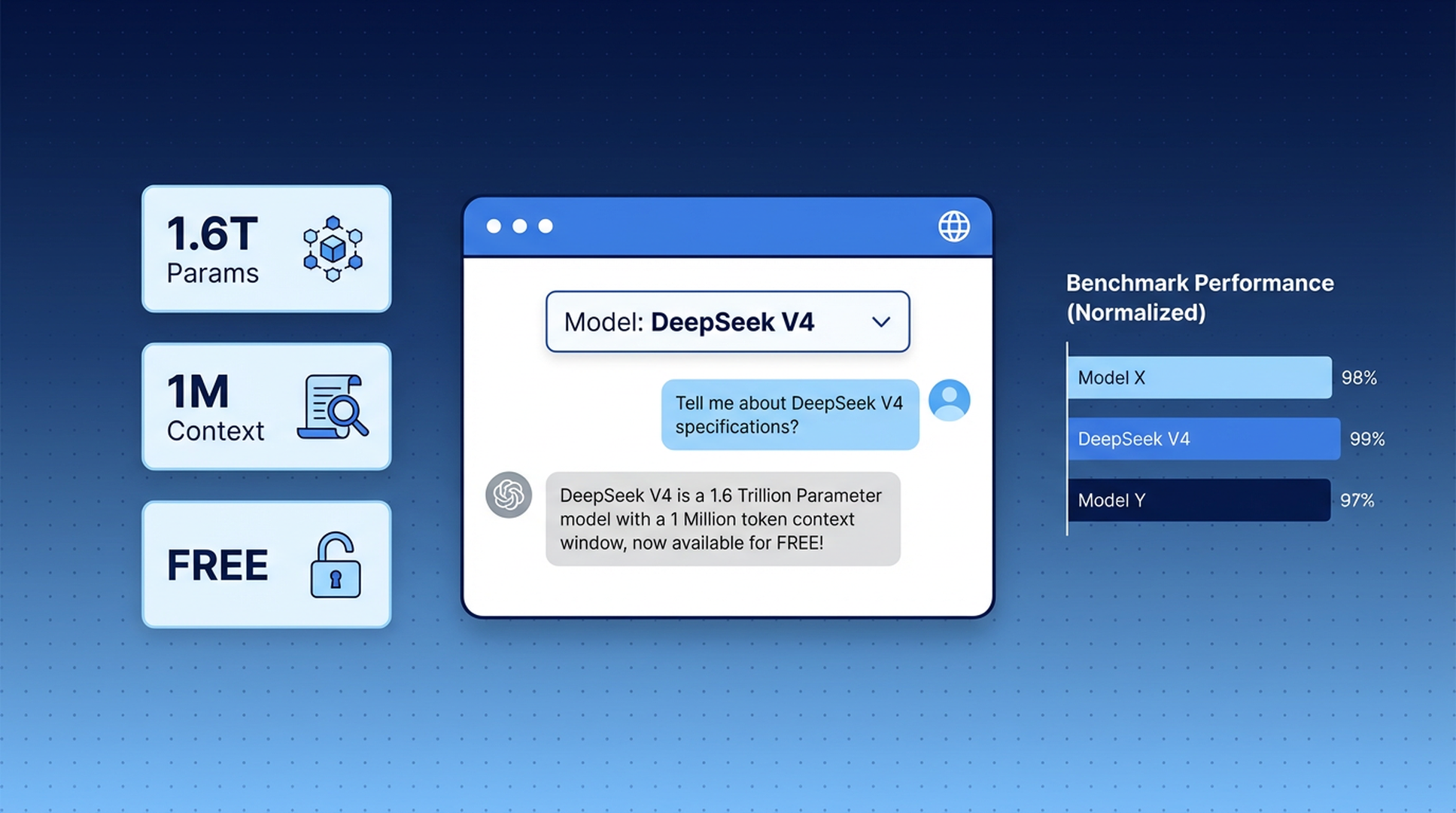
DeepSeek V4 launched this week — a trillion-parameter open-source model that matches GPT-5.4 and Claude Opus 4.6 on most benchmarks. It's the strongest open-weight model released to date.
You can chat with it right now on Felo LLM Playground, for free. No API key, no credits, no account required. Just pick the model and start talking.
What is Felo LLM Playground?
Felo LLM Playground is a free, browser-based chat interface where you can talk to the world's leading AI models side by side. Think of it as a test kitchen for LLMs — you bring the questions, and you get to choose which model answers them.
The Playground currently supports models from OpenAI, Anthropic, Google, and now DeepSeek. You can switch between models mid-conversation, compare responses, and figure out which one works best for your specific task — all without signing up for separate API accounts or managing billing.
It's built for anyone who wants to try the latest models without friction. Developers evaluating models for a project. Researchers comparing reasoning quality. Students who need a capable AI assistant but don't want to pay $20/month for each provider. Or anyone who's just curious about what a trillion-parameter model actually feels like to use.
DeepSeek V4: what you're getting access to
DeepSeek V4 ships in two variants, and both are available on the Playground:
DeepSeek V4-Pro is the full-size model. 1.6 trillion total parameters, 49 billion active per query, trained on 32 trillion tokens. It handles complex reasoning, coding, math, and long-document analysis at a level that competes directly with the best closed models.
DeepSeek V4-Flash is the fast version. 284 billion total parameters, 13 billion active. It gives you quick, capable responses for everyday questions without the latency of the larger model.
Both share a one-million-token context window — enough to process an entire codebase, a book-length document, or months of meeting notes in a single conversation.
How it stacks up
Here's where V4-Pro lands against the current heavyweights:
| Benchmark | DeepSeek V4-Pro | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|---|
| MMLU | 90.1% | ~91% | ~89% |
| HumanEval | 76.8% | ~78% | ~77% |
| SWE-bench Verified | 80.6% | ~82% | ~80% |
| Codeforces Rating | 3,206 | ~3,100 | ~2,900 |
| MATH | 64.5% | ~66% | ~63% |
V4-Pro leads on competitive programming and matches or beats GPT-5.4 on several coding tasks. The extended reasoning mode (V4-Pro-Max) scored 93.5% on LiveCodeBench and 89.8% on IMOAnswerBench.
The gap between open-source and closed models has never been this small. On some tasks, it's gone entirely.
How to use DeepSeek V4 on the Playground
It takes about five seconds:
1. Open the Playground.
Go to playground.felo.ai in your browser. No login needed.
2. Pick DeepSeek V4 from the model selector.
You'll see a dropdown with all available models. Choose V4-Pro for complex tasks or V4-Flash for quick answers.
3. Start chatting.
Type your question naturally. The model responds in real time, just like any chat interface you've used before.
That's the whole setup. No API key configuration, no token budgets, no billing page.
A few things worth trying
If you're not sure where to start, here are some prompts that show off what V4 can do:
- Paste in a long code file and ask V4-Pro to find bugs or suggest refactors
- Give it a math problem — competition-level if you want to push it
- Ask it to explain a technical concept in a specific way ("explain transformers like I'm a database engineer")
- Drop in a research paper abstract and ask for a critical analysis
- Try the same prompt on V4-Pro and GPT-5.4 side by side — the Playground makes this easy
When to pick V4-Pro vs. V4-Flash
Both models are on the Playground, and choosing between them is straightforward.
V4-Pro is the one to use when the question is hard. Research synthesis, debugging tricky code, mathematical proofs, analyzing long documents, anything that benefits from deep reasoning. It's slower, but it thinks harder.
V4-Flash is for everything else. Quick factual lookups, drafting text, brainstorming, translations, summaries. It responds faster and handles routine tasks just as well as the larger model. If you're running through a lot of questions in a session, V4-Flash keeps things moving.
A good rule of thumb: start with V4-Flash. If the answer feels shallow or the task is clearly complex, switch to V4-Pro. The Playground lets you change models mid-conversation, so there's no penalty for experimenting.
Why the Playground matters for trying new models
Every time a new model drops, the same problem comes up: how do you actually try it?
The official API requires signing up, adding a credit card, writing code to make requests, and managing token costs. That's fine if you're integrating the model into a product. It's overkill if you just want to ask it a few questions and see how it thinks.
Felo LLM Playground removes that entire process. New model launches, you open a browser tab, you're using it. No setup, no cost, no commitment.
This matters more than it sounds. The difference between "I should try that new model" and actually trying it is usually 20 minutes of account setup and API configuration. The Playground cuts that to zero.
It also makes model comparison practical. Want to know if DeepSeek V4 handles your use case better than Claude or GPT? Ask the same question to each model in adjacent tabs. You'll learn more in five minutes of hands-on testing than from reading benchmark tables.
What makes DeepSeek V4 worth trying
Beyond the benchmark numbers, V4 has a few things that are genuinely interesting to experience firsthand:
Three reasoning modes. V4 offers Non-Think (fast, direct answers), Think High (step-by-step analysis), and Think Max (maximum reasoning effort). You can feel the difference — Think Max on a hard math problem produces noticeably more thorough work than the default mode. On the Playground, this means you can adjust how much compute the model throws at your question. A quick factual check doesn't need Think Max. A tricky proof does.
Strong multilingual performance. V4 was trained with heavy emphasis on multilingual data. If you work across languages — English and Chinese, Japanese and Korean, or any combination — V4 handles code-switching and cross-language questions well. Ask a question in English about a Chinese-language source, and it won't skip a beat.
Coding ability. With a Codeforces rating of 3,206 and 80.6% on SWE-bench, V4-Pro is one of the strongest coding models you can use today. Ask it to write a function, review a pull request, or explain why your regex isn't matching — it's consistently good. The Playground is a fast way to test this: paste in a snippet, ask for a review, and compare V4's feedback against Claude or GPT.
The million-token context. Most models cap out at 128K or 200K tokens. V4 handles a million. That's roughly 750,000 words — about 10 full-length novels, or a mid-sized company's entire internal documentation. You can paste in an entire project's codebase and ask questions about it without chunking or summarizing first. Previous models forced you to break that work into pieces. V4 takes it whole.
Practical use cases on the Playground
Here are a few ways people are already using DeepSeek V4 on the Playground:
Developers paste in code and ask V4-Pro to review it, suggest optimizations, or explain unfamiliar patterns. The million-token context means you can drop in an entire module — not just a single function — and get feedback that accounts for the full picture. Some developers use V4-Flash for quick syntax questions and V4-Pro for architecture-level discussions.
Students use V4-Pro-Max for math and science problem sets. The Think Max reasoning mode walks through proofs step by step, which makes it useful not just for getting answers but for understanding the approach. It's also strong at explaining concepts at different levels — ask it to explain gradient descent for a first-year student versus a PhD candidate and you'll get meaningfully different responses.
Researchers feed V4 paper abstracts or full sections and ask for critical analysis, methodology gaps, or connections to related work. The multilingual training is useful here too — V4 can work with sources in Chinese, Japanese, or Korean and discuss them in English without losing nuance.
Writers and marketers use V4-Flash for brainstorming, drafting, and editing. It's fast enough for iterative work — write a draft, get feedback, revise, repeat — without the latency that makes larger models frustrating for back-and-forth sessions.
Comparing DeepSeek V4 to other models on the Playground
The Playground gives you access to models from multiple providers. Here's how V4 fits in:
On coding tasks, V4-Pro is among the best available. It outperforms Claude Opus 4.6 on Codeforces and SWE-bench, and trades leads with GPT-5.4 depending on the specific task.
On writing and instruction-following, Claude still has an edge. If you need nuanced prose or careful adherence to complex formatting instructions, Claude models tend to be more reliable.
On general knowledge and reasoning, V4-Pro, GPT-5.4, and Gemini 3.1 Pro are all within a few percentage points of each other. The practical difference is hard to notice on most questions.
On speed for routine tasks, V4-Flash is hard to beat. It's responsive and capable enough for the vast majority of everyday questions.
The real advantage of the Playground is that you don't have to take anyone's word for it. Run your own comparison. The models are all right there.
Frequently asked questions
Is DeepSeek V4 really free on Felo Playground?
Yes. Both V4-Pro and V4-Flash are available at no cost. You don't need to create an account or enter payment information.
Do I need to install anything?
No. Felo LLM Playground runs entirely in the browser at playground.felo.ai. Works on desktop and mobile.
Can I use DeepSeek V4 in languages other than English?
Yes. V4 performs well across English, Chinese, Japanese, Korean, and many other languages. It was trained with a strong multilingual focus.
What's the difference between Felo Playground and Felo Search?
Felo Search combines AI models with real-time web search to give you answers grounded in current information, with citations. The Playground is a direct chat interface — no web search, just you and the model. Use Search when you need up-to-date facts; use the Playground when you want to reason, code, write, or explore ideas.
Is there a usage limit?
The Playground is free to use. Specific rate limits may apply during high-traffic periods, but there are no token budgets or daily caps for normal use.
Try DeepSeek V4 now
DeepSeek V4 is live on Felo LLM Playground. Open a tab, pick the model, and see what a trillion-parameter open-source model can do for your work.