Claude Opus 4.8 প্রকাশিত: Anthropic-এর এখন পর্যন্ত সবচেয়ে সক্ষম মডেল

Anthropic সদ্য প্রকাশ করেছে Claude Opus 4.8 — দ্রুততর, আরও সৎ, এবং এজেন্টিক কাজগুলোতে আরও উন্নত। এখানে নতুন সব কিছু এবং কেন এটি ডেভেলপারদের জন্য গুরুত্বপূর্ণ তার বিস্তারিত।

এই সপ্তাহে Anthropic প্রকাশ করেছে Claude Opus 4.8। এটি তাদের সর্বাধিক সক্ষম মডেল যা এখন সাধারণ ব্যবহারের জন্য উন্মুক্ত। Opus 4.7-এর উপর ভিত্তি করে এটি কোডিং, বিশ্লেষণ, এজেন্টিক কাজ, এবং সততার ক্ষেত্রে উন্নতি এনেছে। দাম অপরিবর্তিত: প্রতি মিলিয়ন ইনপুট টোকেনে $5, প্রতি মিলিয়ন আউটপুট টোকেনে $25।
এখানে কী পরিবর্তন হয়েছে এবং কীভাবে এটি ডেভেলপারদের জন্য গুরুত্বপূর্ণ তা দেখা যাক।
Opus 4.7 থেকে কী পরিবর্তন হয়েছে?
নিচে পরিবর্তনগুলোর বিস্তারিত দেওয়া হলো:
1. উন্নত বিচারবোধ এবং সততা
Opus 4.8 এখন অনেক কম অযথা দাবি করে এবং কোডের ত্রুটিগুলো অবহেলিত রাখার সম্ভাবনাও কম। Anthropic-এর মূল্যায়নে দেখা গেছে, এটি পূর্ববর্তী সংস্করণের তুলনায় প্রায় চার গুণ কম সম্ভবনা রাখে নিজস্ব কোডের বাগগুলি অদেখা রেখে দেওয়ার। এটি একটি গুরুত্বপূর্ণ উন্নতি, বিশেষ করে যখন আপনি একটি মডেলকে স্বয়ংক্রিয়ভাবে কাজ করার জন্য ভরসা করছেন।
প্রাথমিক পরীক্ষকরা জানিয়েছেন, এটি নিজেই প্রশ্ন করে, নিজের ভুল ধরে, এবং কোনো পরিকল্পনা অসংগত হলে তা নিয়ে আপত্তি জানায়।
2. আরও শক্তিশালী এজেন্টিক পারফরম্যান্স
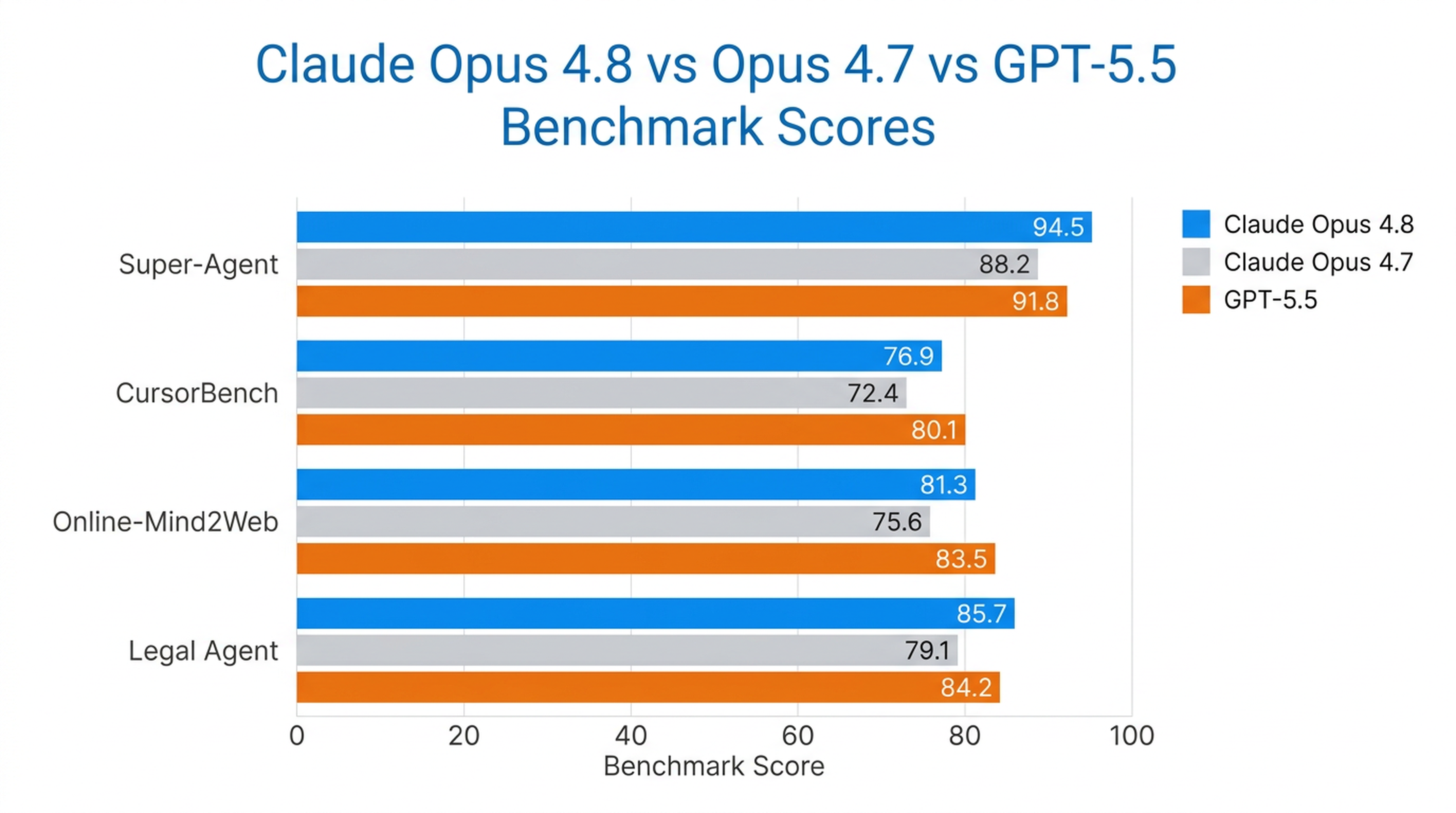
Opus 4.8 একমাত্র মডেল যা Anthropic-এর Super-Agent বেঞ্চমার্কে সব কেস সম্পূর্ণভাবে সম্পন্ন করেছে, পূর্ববর্তী Opus মডেল ও GPT-5.5কে খরচ-সমপরিমাণে ছাড়িয়ে গেছে। CursorBench-এ এটি পূর্ববর্তী Opus সংস্করণের তুলনায় প্রতিটি প্রচেষ্টার স্তরে ভালো করেছে, কম টুল ব্যবহারের ধাপেই একই বুদ্ধিমত্তা প্রদর্শন করেছে।
এটি Anthropic-এ পরীক্ষিত সবচেয়ে শক্তিশালী কম্পিউটার-ইউজ এবং ব্রাউজার-এজেন্ট মডেল, যার Online-Mind2Web স্কোর 84%।
3. দ্রুততর ও আরও কার্যকর টুল কলিং
মডেলটি এখন খুব কম ক্ষেত্রেই কোনো প্রয়োজনীয় টুল কল এড়িয়ে যায় — যা Opus 4.7-এর একটি সমস্যা ছিল। দীর্ঘ এজেন্টিক কাজগুলোও এখন কম বাধাপ্রাপ্ত হয় এবং প্রাসঙ্গিক থাকে।
4. সত্যিকারের অভিযোজ্য চিন্তাধারা
Adaptive thinking সক্রিয় থাকলে, Opus 4.8 প্রতি টার্নে নির্ধারণ করে যে বিশ্লেষণ দরকার কিনা। সহজ অনুসন্ধান সরাসরি উত্তর দেয়, জটিল সমস্যায় বিশ্লেষণ যুক্ত করে। ফলে Opus 4.7-এর তুলনায় কম টোকেন অপচয় হয়।
নতুন বৈশিষ্ট্যসমূহ যা জানার মতো
Effort Control — এখন সব প্ল্যানে
মডেল সিলেক্টরের পাশে এখন একটি নতুন নিয়ন্ত্রণ যুক্ত হয়েছে যা ব্যবহারকারীদের Claude-এর প্রতিক্রিয়ার প্রচেষ্টার মাত্রা নির্ধারণ করতে দেয়। Opus 4.8 ডিফল্টভাবে high এ সেট থাকে, কঠিন কাজের জন্য extra এবং max অপশন যুক্ত হয়েছে। Claude Code-এ রেট লিমিটও বাড়ানো হয়েছে যাতে বেশি টোকেন ব্যবহারে কোনো সমস্যা না হয়।
Fast Mode — ২.৫× গতি, কম খরচ
Fast মোড এখন Claude API-তে গবেষণামূলক প্রিভিউরূপে Opus 4.8-এর জন্য উপলব্ধ। এটি ২.৫× পর্যন্ত দ্রুত আউটপুট টোকেন উৎপাদন করে এবং পূর্ববর্তী মডেলের তুলনায় প্রায় তিনগুণ কম খরচে।
Mid-Conversation System Messages
Messages API এখন role: "system" এন্ট্রি গ্রহণ করে মেসেজ অ্যারে-র ভিতরে। এর ফলে আপনি কোনো টাস্ক চলাকালীন Claude-এর নির্দেশাবলী পরিবর্তন করতে পারবেন ক্যাশ না ভেঙে — যা অনুমতি বা প্রেক্ষাপট পরিবর্তনের সময় খুবই কার্যকর।
Lower Prompt Cache Minimum
সর্বনিম্ন ক্যাশযোগ্য প্রম্পট দৈর্ঘ্য এখন 1,024 টোকেন। যা আগে Opus 4.7-এ খুব ছোট হওয়ায় ক্যাশ করা যেত না, এখন তা কোনো কোড পরিবর্তন ছাড়াই ক্যাশ করা যাবে।
বাস্তবজগতের বেঞ্চমার্কসমূহ
| Benchmark | Opus 4.8 পারফরম্যান্স |
|---|---|
| Super-Agent | সব কেস সম্পূর্ণ (একমাত্র মডেল যা করতে পেরেছে) |
| CursorBench | প্রতিটি স্তরে পূর্ববর্তী সব Opus মডেলকে ছাড়িয়ে গেছে |
| Online-Mind2Web | 84% (সবচেয়ে শক্তিশালী পরীক্ষিত মডেল) |
| Legal Agent Benchmark | সর্বোচ্চ স্কোর; প্রথম মডেল যা 10% সীমা অতিক্রম করেছে |

Opus 4.8 সবচেয়ে শক্তিশালী যেখানে দীর্ঘমেয়াদি স্বায়ত্তশাসন দরকার — কোডিং এজেন্ট, গবেষণা এজেন্ট, আইনগত কাজ, এবং এন্টারপ্রাইজ জ্ঞানভিত্তিক কাজের ক্ষেত্রে।
মূল্য — Opus 4.7 থেকে অপরিবর্তিত
| মোড | ইনপুট | আউটপুট |
|---|---|---|
| Standard | $5 / 1M টোকেন | $25 / 1M টোকেন |
| Fast | $10 / 1M টোকেন | $50 / 1M টোকেন |
মূল্য Opus 4.7-এর মতোই, কিন্তু পারফরম্যান্স উন্নত। API-তে মডেল আইডি হলো claude-opus-4-8। এটি 1M টোকেন কনটেক্সট উইন্ডো এবং 128k সর্বোচ্চ আউটপুট টোকেন সমর্থন করে।
পরবর্তীতে কী আসছে: Mythos-Class মডেল
Anthropic নতুন এক ধরণের মডেলের ইঙ্গিত দিয়েছে যা "Opus-এর চেয়েও বেশি বুদ্ধিমান"। Claude Mythos Preview বর্তমানে অল্প কয়েকটি প্রতিষ্ঠান ব্যবহার করছে সাইবার সিকিউরিটি কাজের জন্য Project Glasswing-এর মাধ্যমে। কোম্পানি পরিকল্পনা করছে দ্রুতই এই Mythos-class মডেলগুলো সব গ্রাহকের কাছে আনতে, প্রয়োজনীয় নিরাপত্তা ব্যবস্থা সম্পূর্ণ হলে।
কেন মডেলের বৈচিত্র্য গুরুত্বপূর্ণ
এখন প্রায় প্রতি সপ্তাহেই নতুন AI মডেল প্রকাশিত হচ্ছে। ডেভেলপারদের জন্য আসল প্রশ্ন হলো — কোন মডেল “সেরা” তা নয়, বরং কোন কাজের জন্য কোন মডেল উপযোগী, এবং কীভাবে তাদের মধ্যে নির্বিঘ্নে পরিবর্তন করা যায়।
এই চ্যালেঞ্জটি Felo AI মোকাবিলা করছে। উন্নত মডেলের সাহায্যে রিয়েল-টাইম উত্তর প্রদানকারী সার্চের পাশাপাশি, Felo অফার করে একটি LLM Playground — যেখানে আপনি এক জায়গায় একাধিক শীর্ষস্থানীয় মডেল চালাতে, পরীক্ষা করতে, এবং তুলনা করতে পারেন। আলাদা API কী বা ড্যাশবোর্ড পরিবর্তনের ঝামেলা নেই। শুধু মডেল বেছে নিন, প্রম্পট চালান, আর দেখুন ফলাফল।
আপনি যদি আপনার ওয়ার্কফ্লোর জন্য সেরা মডেলটি খুঁজছেন, অথবা শুধু জানতে চান কী কী বিকল্প আছে — তাহলে এক ইন্টারফেসে সবকিছু পাওয়া তুলনামূলকভাবে অনেক সহজ করে দেয়।
বিনামূল্যে Felo AI ব্যবহার করে দেখুন → https://felo.ai
এই পোস্টটি নিম্নলিখিত ভাষায়ও উপলব্ধ: English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, Français, العربية, Русский, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Türkçe, Italiano, ไทย, Español and Português।