গুগল অ্যান্টিগ্রাভিটির জন্য ফেলো ওয়েব ফেচ: প্রোডাক্ট ও ওয়েব তথ্যকে গঠনকৃত ডেটা হিসেবে এক্সট্র্যাক্ট করুন

জেনে নিন কীভাবে ফেলো ওয়েব ফেচ দক্ষতা গুগল অ্যান্টিগ্রাভিটি এজেন্টদের ওয়েবপেজগুলোকে পরিপাটি মার্কডাউন, এইচটিএমএল বা টেক্সটে রূপান্তরিত করে প্রোডাক্ট রিসার্চ, প্রতিযোগিতামূলক বিশ্লেষণ এবং গঠনকৃত ডেটা সংগ্রহের জন্য।
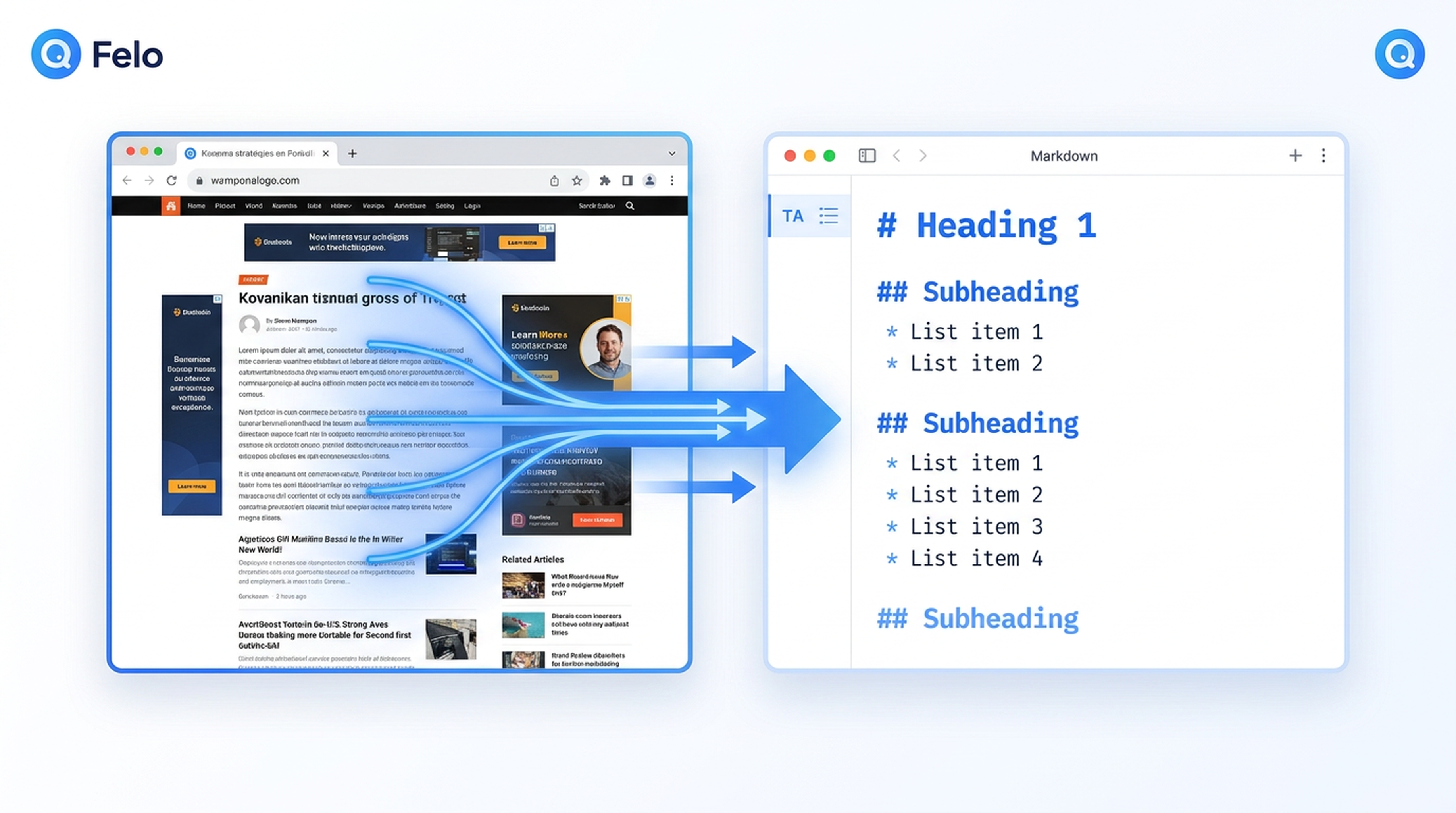
অ্যান্টিগ্রাভিটি এজেন্টদের প্রথম চ্যালেঞ্জ
আপনি আপনার গুগল অ্যান্টিগ্রাভিটি এজেন্টকে একটি গবেষণার কাজ দেন। হয়তো এটি SaaS প্রাইসিং তুলনা করছে, প্রতিযোগীর ফিচার লিস্ট নিচ্ছে, বা কোনো ব্রিফিংয়ের সূত্র সংগ্রহ করছে। এজেন্টটি পরিকল্পনা করে, জানে কি প্রয়োজন। কিন্তু তারপর এটি একটি দেয়ালে ধাক্কা খায়: Gemini 3-এর প্রশিক্ষণ ডেটার একটি কাট-অফ ডেট আছে, এবং এজেন্টটি নিজের উদ্যোগে লাইভ ওয়েব থেকে কিছু আনতে পারে না।
ঠিক এই জায়গায় ফেলো স্কিলস কাজে আসে। বিশেষত, Felo Web Fetch স্কিল এক্সট্র্যাকশন ফাঁক পূরণ করে — যেকোনো ওয়েবপেজকে পরিপাটি, গঠনকৃত মার্কডাউন, এইচটিএমএল বা সাধারণ টেক্সটে রূপান্তরিত করে যা আপনার অ্যান্টিগ্রাভিটি এজেন্ট সত্যিই ব্যবহার করতে পারে।
Felo Web Fetch কী?
Felo Web Fetch একটি ফোল্ডার-ভিত্তিক স্কিল, যা আপনি গুগল অ্যান্টিগ্রাভিটির .agent/skills/ ডিরেক্টরিতে রাখেন। ইনস্টল হয়ে গেলে এটি একটি স্বয়ংক্রিয়ভাবে সক্রিয় ক্ষমতা হিসেবে কাজ করে — আপনার এজেন্টকে কোনো স্ল্যাশ কমান্ড টাইপ করতে বা URL কপি-পেস্ট করতে হয় না। যখন কোনো কাজের জন্য ওয়েবপেজ পড়া প্রয়োজন হয়, তখন এজেন্ট ম্যানেজার কাজটিকে স্কিলের বিবরণের সঙ্গে মেলায় এবং স্বয়ংক্রিয়ভাবে চালায়।
স্কিলটি Felo Web Extract API (POST /v2/web/extract) ব্যবহার করে যেকোনো URL থেকে কন্টেন্ট টেনে আনে এবং আপনার ওয়ার্কফ্লো অনুযায়ী ফরম্যাটে তা ফিরিয়ে দেয়:
| আউটপুট ফরম্যাট | কখন ব্যবহার করবেন |
|---|---|
| Markdown | AI ব্যবহারের জন্য আদর্শ — হেডিং, লিস্ট এবং লিংকসহ পরিপাটি গঠন বজায় থাকে |
| HTML | কাঁচা DOM স্ট্রাকচার প্রয়োজন হলে |
| Text | সাধারণ টেক্সট এক্সট্র্যাকশন, দ্রুত স্ক্যান বা টেক্সট প্রসেসিংয়ের জন্য উপযোগী |
এটি ইনস্টল করুন felo.ai/skills/antigravity থেকে —
.agent/skills/এ ফোল্ডারটি কপি করুন এবং Git-এ কমিট করুন। আপনার টিমের প্রতিটি ডেভেলপার পরবর্তী পুলে এই সক্ষমতা পাবে।
অ্যান্টিগ্রাভিটির ভেতরে এটি কীভাবে কাজ করে
ইনস্টলেশন প্রক্রিয়া ইচ্ছাকৃতভাবে সহজ রাখা হয়েছে:
# Felo skills রিপোজিটরি ক্লোন করুন
git clone https://github.com/Felo-Inc/felo-skills.git
# web-fetch স্কিলটি আপনার Antigravity skills ফোল্ডারে কপি করুন
cp -r felo-skills/felo-web-fetch ~/.gemini/antigravity/skills/
যখন felo-web-fetch ফোল্ডারটি .agent/skills/-এ থাকে, তখন SKILL.md ফাইলটি মূল কাজটি করে। এর description ফিল্ডটি সেমান্টিক ট্রিগার হিসেবে কাজ করে। যখন আপনার এজেন্ট এমন কোনো কাজের মুখোমুখি হয় যেমন "এই তিনটি SaaS প্রোডাক্টের প্রাইসিং তুলনা কর" বা "এই প্রতিযোগীর পেজ থেকে ফিচার লিস্ট বের কর", তখন এজেন্ট ম্যানেজার স্বয়ংক্রিয়ভাবে স্কিলটি লোড করে — কোনো ম্যানুয়াল কমান্ড লাগে না।
মূল ক্ষমতাসমূহ
1. পরিচ্ছন্ন আর্টিকেল এক্সট্র্যাকশনের জন্য রিডেবিলিটি মোড
প্রতিটি ওয়েবপেজ সুগঠিত নয়। ব্লগ, সংবাদ বা ডকুমেন্টেশন পেজগুলোতে প্রায়ই ন্যাভিগেশন বার, সাইডবার, ফুটার এবং বিজ্ঞাপনের বিশৃঙ্খলা থাকে। Felo Web Fetch একটি রিডেবিলিটি মোড (--with-readability true) সমর্থন করে যা শুধুমাত্র মূল আর্টিকেল কন্টেন্টটি এক্সট্র্যাক্ট করে, বাকিটা বাদ দেয়।
গবেষণামূলক অ্যান্টিগ্রাভিটি এজেন্টদের জন্য এটি বিশেষভাবে উপকারী — ২০০KB অপ্রয়োজনীয় কন্টেন্ট পড়ার বদলে এজেন্ট সরাসরি ফোকাসড, পড়ার উপযোগী আর্টিকেল পায় — ঠিক সেই তথ্য যা বিশ্লেষণের জন্য দরকার।
2. নির্ভুল এক্সট্র্যাকশনের জন্য CSS সিলেক্টর টার্গেটিং
কখনও আপনি পুরো পেজ চান না। আপনি কেবল .pricing-section এর ভেতরের প্রাইসিং টেবিল বা div.changelog এর মধ্যে পরিবর্তনের তালিকা চান। Felo Web Fetch --target-selector প্যারামিটার সমর্থন করে, যা আপনাকে নির্দিষ্ট DOM উপাদান এক্সট্র্যাক্ট করার সুযোগ দেয়।
প্রতিযোগিতামূলক বিশ্লেষণ ওয়ার্কফ্লোতে এটি মানে আপনার এজেন্ট কেবল প্রাসঙ্গিক প্রাইসিং ডেটা, ফিচার তুলনা টেবিল বা প্রোডাক্ট স্পেসিফিকেশন সংগ্রহ করবে — অপ্রয়োজনীয় কন্টেন্ট বাদ দিয়ে।
3. ক্রল মোড: দ্রুত বনাম সূক্ষ্ম
| মোড | ব্যবহারের ক্ষেত্র |
|---|---|
fast | স্ট্যাটিক পেজ, ডকুমেন্টেশন, ব্লগপোস্ট — যা সঙ্গে সঙ্গে রেন্ডার হয় |
fine | জাভাস্ক্রিপ্ট-নির্ভর পেজ, SPA, বা ডায়নামিক কন্টেন্ট রেন্ডারের জন্য সময় প্রয়োজন এমন পেজ |
এজেন্ট ম্যানেজারের ডিফল্ট মোড হলো দক্ষতার জন্য fast। যখন রিঅ্যাক্ট-নির্ভর প্রোডাক্ট পেজ থেকে এক্সট্র্যাকশন করা হয় বা লগইনের পেছনের ড্যাশবোর্ড থেকে ডেটা আনা হয়, তখন আপনি fine মোডে পরিবর্তন করবেন যাতে সম্পূর্ণ কন্টেন্ট লোড হয়।
4. কুকি ও অথেন্টিকেশন সমর্থন
লগইন প্রয়োজন এমন পেজগুলোর জন্য Felo Web Fetch কুকি (--cookie "session_id=xxx") এবং কাস্টম ইউজার-এজেন্ট স্ট্রিং পাস করতে পারে। এর ফলে আপনার অ্যান্টিগ্রাভিটি এজেন্ট অথেনটিকেটেড ড্যাশবোর্ড, ইন্টারনাল ডকুমেন্টেশন পোর্টাল বা পার্টনার পেজ থেকেও কন্টেন্ট এক্সট্র্যাক্ট করতে পারে — ফলে সোর্স ম্যাটেরিয়ালের পরিসর ব্যাপকভাবে বেড়ে যায়।
5. গঠনকৃত সারাংশ: লিংক ও ইমেজ
কাঁচা কন্টেন্ট ছাড়াও স্কিলটি অন্তর্ভুক্ত করতে পারে:
--with-links-summary true— সব লিংক সংগ্রহ ও সারসংক্ষেপ করা--with-images-summary true— সব ছবি মেটাডাটাসহ সংগ্রহ করা--with-images-readability true— ছবি প্রাসঙ্গিক টেক্সটসহ যুক্ত করা
যখন কোনো গবেষণা এজেন্ট কোনো প্রোডাক্ট ওভারভিউ তৈরি করছে, তখন এসব সারাংশগুলো গঠনকৃত ডেটা পয়েন্টে পরিণত হয় — ফলোআপের জন্য রেফারেন্স লিংক, ভিজুয়াল তুলনার জন্য ইমেজ URL এবং প্রসঙ্গগত মেটাডাটা যা চূড়ান্ত রিপোর্টকে সমৃদ্ধ করে।
বাস্তব ব্যবহার ক্ষেত্র
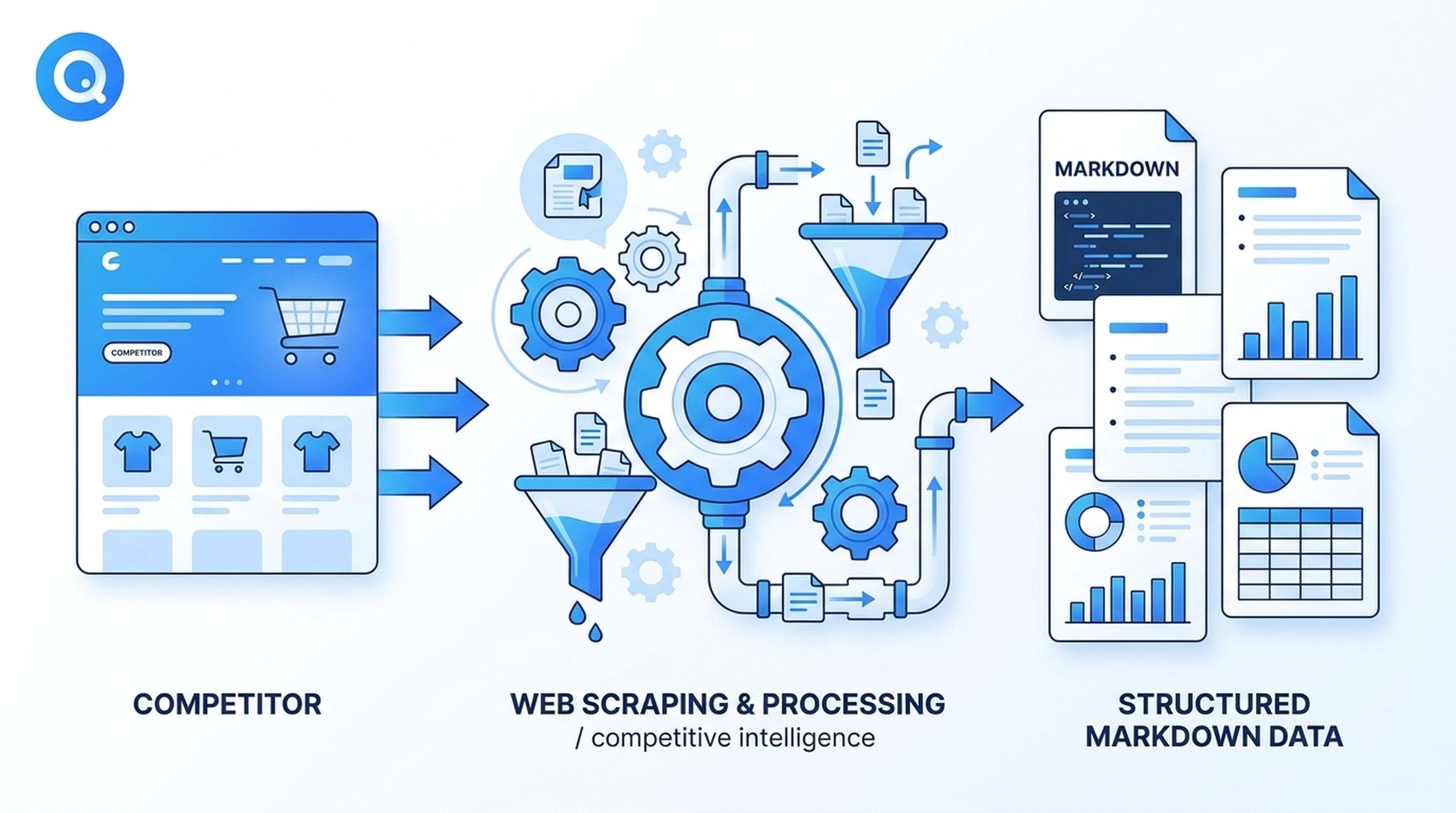
ব্যাপক পরিসরে প্রতিযোগিতামূলক বিশ্লেষণ
ভাবুন আপনার অ্যান্টিগ্রাভিটি এজেন্টের কাজ হলো সাপ্তাহিকভাবে তিনটি প্রতিযোগীর প্রোডাক্ট পৃষ্ঠা পর্যবেক্ষণ করা। Felo Web Fetch ইনস্টল করা হলে এজেন্টটি:
- স্বয়ংক্রিয়ভাবে প্রতিটি প্রতিযোগীর প্রাইসিং পেজে যায়
- কন্টেন্টকে পরিপাটি মার্কডাউন হিসেবে এক্সট্র্যাক্ট করে
- ফিচার, প্রাইসিং টিয়ার এবং নতুন সংযোজন আপনার মূল ডেটার সঙ্গে তুলনা করে
- আগের এক্সট্র্যাকশন থেকে পরিবর্তন থাকলে তা ফ্ল্যাগ করে
এজেন্টকে আর পেজগুলো ম্যানুয়ালি আনতে হয় না। যখন কাজ স্কিলের সঙ্গে মিলে যায়, এটি স্বয়ংক্রিয়ভাবে ডেটা বের করে ও এজেন্টের বিশ্লেষণ পাইপলাইনে সরবরাহ করে।
প্রোডাক্ট রিসার্চ ও কেনার সিদ্ধান্ত
যখন কোনো এজেন্টের কাজ টুল, সার্ভিস বা প্ল্যাটফর্ম মূল্যায়নের হয়, Felo Web Fetch তাকে বর্তমান প্রোডাক্ট পেজে অ্যাক্সেস দেয় — পুরনো ট্রেনিং ডেটা নয়। এজেন্ট সরাসরি সোর্স থেকে স্পেসিফিকেশন, প্রাইসিং, ইন্টিগ্রেশন লিস্ট ও গ্রাহক প্রশংসাপত্র সংগ্রহ করে, বাস্তব ও হালনাগাদ তথ্যভিত্তিক রিপোর্ট তৈরি করে।
কনটেন্ট তৈরির উৎস হিসেবে
কনটেন্ট টিমগুলো অ্যান্টিগ্রাভিটি ব্যবহার করে ব্রিফিং, মার্কেট অ্যানালাইসিস ও গবেষণাপত্র তৈরি করতে। Felo Web Fetch মূল ওয়েবসোর্স থেকে নির্ভরযোগ্য তথ্য সংগ্রহ করে এজেন্টকে খাওয়ায় — ফলে চূড়ান্ত আউটপুট অনুমান নয়, বরং প্রাথমিক উৎস-নির্ভর হয়।
ডকুমেন্টেশন ও API পরিবর্তন শনাক্তকরণ
ইঞ্জিনিয়ারিং টিমের জন্য API ডকুমেন্টেশন, SDK রেফারেন্স বা ডেভেলপার পোর্টালের পরিবর্তন শনাক্ত করা অত্যন্ত জরুরি। Felo Web Fetch ডকুমেন্টেশন পেজগুলো মার্কডাউন আকারে এক্সট্র্যাক্ট করতে পারে, যা এজেন্ট পূর্ববর্তী সংস্করণের সঙ্গে তুলনা করে ব্রেকিং পরিবর্তন, নতুন এন্ডপয়েন্ট বা বাদ পড়া ফিচার শনাক্ত করতে পারে।
ডেভেলপারদের জন্য API রেফারেন্স
যদি আপনি Felo Web Fetch প্রোগ্রামেটিকভাবে (অ্যান্টিগ্রাভিটির বাইরে) ব্যবহার করেন, APIটি সহজ:
curl -X POST "https://openapi.felo.ai/v2/web/extract" \
-H "Authorization: Bearer $FELO_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"url": "https://example.com/product",
"output_format": "markdown",
"with_readability": true,
"crawl_mode": "fast"
}'
মূল রিকোয়েস্ট প্যারামিটারসমূহ:
| প্যারামিটার | টাইপ | ডিফল্ট | বর্ণনা |
|---|---|---|---|
url | string | — | এক্সট্র্যাক্ট করার ওয়েবপেজের URL |
output_format | string | html | html, markdown, বা text |
crawl_mode | string | fast | fast বা fine |
with_readability | boolean | — | শুধুমাত্র মূল কন্টেন্ট এক্সট্র্যাক্ট করা |
target_selector | string | — | নির্দিষ্ট উপাদানের জন্য CSS সিলেক্টর |
wait_for_selector | string | — | এক্সট্র্যাকশনের আগে নির্দিষ্ট উপাদান অপেক্ষা করা |
timeout | integer | — | মিলিসেকেন্ডে টাইমআউট |
set_cookies | array | — | অথেনটিকেটেড পেজের জন্য কুকি এন্ট্রি |
সফল রেসপন্সে data.content-এ এক্সট্র্যাক্টেড কন্টেন্ট ফেরত আসে, আপনার পছন্দের output_format অনুযায়ী গঠনকৃতভাবে।
কেন এটি অ্যান্টিগ্রাভিটি টিমের জন্য গুরুত্বপূর্ণ
Felo Web Fetch-এর মূল্য কেবল এক্সট্র্যাকশনে নয় — বরং এটি অ্যান্টিগ্রাভিটি ওয়ার্কফ্লোকে যা সক্ষম করে তাতেই:
1. এজেন্ট এখনকার ডেটা ব্যবহার করতে পারে, পুরনো স্মৃতি নয়। Gemini 3 ওয়েবে ব্রাউজ করতে পারে না। Felo Web Fetch সেই ঘাটতি পূরণ করে, এজেন্টকে যেকোনো URL থেকে বাস্তব কন্টেন্টে অ্যাক্সেস দেয়।
2. গঠনকৃত আউটপুট মানে গঠনকৃত বিশ্লেষণ। যখন কন্টেন্ট পরিপাটি মার্কডাউনে আসে, এজেন্ট সহজেই হেডিং, লিস্ট, টেবিল ও কোড ব্লক বিশ্লেষণ করতে পারে — ফলে তার বিশ্লেষণও বাস্তব স্ট্রাকচারে ভিত্তি করে।
3. শূন্য কনফিগারেশন পার্থক্য। কারণ স্কিলটি .agent/skills/-এ থাকে এবং Git-এ কমিট হয়, টিমের প্রতিটি ডেভেলপার একই সক্ষমতা পায়। কোনো ব্যবহারকারীভেদে সেটআপ লাগে না, কোনো নির্দিষ্ট পরিবেশের হ্যাক নয়।
4. এটি অন্যান্য ফেলো স্কিলের সঙ্গে একত্রে কাজ করে। Felo Search-এর সঙ্গে একত্রে লাইভ গবেষণা যাচাইয়ের জন্য বা Felo Slides-এর সঙ্গে এক্সট্র্যাক্ট করা কন্টেন্টকে প্রেজেন্টেশন ডেকে রূপান্তর করার জন্য এটি ব্যবহার করা যায়। এজেন্ট ম্যানেজার স্বয়ংক্রিয়ভাবে স্কিলগুলোর মধ্যে কাজ সমন্বয় করে।
শুরু করুন
Felo Web Fetch-কে আপনার অ্যান্টিগ্রাভিটি ওয়ার্কফ্লোতে আনতে মাত্র কিছু মিনিট লাগে:
- felo.ai-এ যান এবং একটি API কী তৈরি করুন (Settings → API Keys)
- এনভায়রনমেন্ট ভ্যারিয়েবল সেট করুন:
export FELO_API_KEY="your-api-key-here" - স্কিল ফোল্ডারটি কপি করুন আপনার
.agent/skills/ডিরেক্টরিতে - Git-এ কমিট করুন যাতে টিমের এজেন্টরা স্বয়ংক্রিয়ভাবে এটি পায়
এটাই সব। এরপর আপনার পরবর্তী এজেন্ট টাস্ক যা ওয়েবপেজ পড়া জড়িত, সেটি স্বয়ংক্রিয়ভাবে Felo Web Fetch ট্রিগার করবে — কোনো ম্যানুয়াল হস্তক্ষেপ নয়, কোনো প্রসঙ্গ পরিবর্তন নয়।
বড় ছবি
Felo Web Fetch হলো Google Antigravity-এর জন্য Felo Skills ইকোসিস্টেমের একটি অংশ। একসঙ্গে, এই স্কিলগুলো অ্যান্টিগ্রাভিটি এজেন্ট ম্যানেজারকে একটি সক্ষম পরিকল্পনাকারী থেকে সম্পূর্ণ গবেষণা ও প্রোডাকশন টুলে রূপান্তরিত করে — যা জ্ঞানগত ফাঁক পূরণ করে, টিম মেমরি ধরে রাখে, এবং কর্মফল সরবরাহ করে।
Felo Web Fetch-এর এক্সট্র্যাকশন স্তরটি প্রায়শই টিমগুলো প্রথমেই ইনস্টল করে, কারণ এটি সবচেয়ে অবিলম্বেই জরুরি সমস্যার সমাধান দেয়: আপনার এজেন্টকে ওয়েব পড়তে হবে, কিন্তু Gemini 3 একা তা পারে না। একবার এক্সট্র্যাকশন কাজ করলে, লাইভ সার্চ, স্থায়ী জ্ঞানভান্ডার ও আউটপুট প্রজন্ম যোগ করা একটি স্বাভাবিক অগ্রগতি হয়ে যায়।
আপনার অ্যান্টিগ্রাভিটি এজেন্টদের বাস্তব ওয়েব কন্টেন্ট এক্সট্র্যাক্ট, বিশ্লেষণ ও প্রয়োগের ক্ষমতা দিতে প্রস্তুত? শুরু করুন Felo Web Fetch দিয়ে — এটি বিনামূল্যে, ফোল্ডার-ভিত্তিক এবং টিম ব্যবহারের জন্য প্রস্তুত।
এই পোস্টটি নিম্নলিখিত ভাষায়ও উপলব্ধ: English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, Français, العربية, Русский, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Türkçe, Italiano, ไทย, Español and Português।