AI-Suchmaschinen Fuzzy-Fragenbewertungsbericht (v1.3)

Dieser Artikel bewertet die Leistung mehrerer KI-Suchmaschinen im Umgang mit "fuzzy query questions". Felo AI erzielte die beste Leistung mit einer Genauigkeitsrate von 80%, gefolgt von Perplexity Pro. Der Artikel analysiert die Stärken und Schwächen jedes Produkts und bietet spezifische Fallstudien zur Veranschaulichung. Die Bewertungsdaten und Ergebnisse wurden als Open Source veröffentlicht, was wertvolle Einblicke in die Entwicklung von KI-Suchmaschinen bietet.
I. Fazit
In der heutigen informationsgesättigten Ära, in der die Anfragen der Benutzer komplexer werden, wird die Leistungsdifferenz zwischen KI-Suchsystemen zunehmend offensichtlich. Dies gilt insbesondere bei der Behandlung von Softwarekonfigurationen, mehreren Datenquellen, Informationen, die nicht online verfügbar sind, oder datumsbezogenen Anfragen. Wir bezeichnen diese herausfordernden Anfragen als "mehrdeutige Fragen-Suchen." In dieser Bewertung haben wir mehrere beliebte KI-Suchmaschinen umfassend getestet, darunter Perplexity Basic, Perplexity Pro, GenSpark, Felo AI, iAsk und You.com, wobei wir uns auf diese Art von Anfragen konzentrierten.
Nach einer Reihe strenger Tests kamen wir zu dem Schluss:
- Felo AI erwies sich als der herausragende Performer und zeigte außergewöhnliche Fähigkeiten im Umgang mit mehrdeutigen Anfragen. Es führte die Gruppe mit einer beeindruckenden Genauigkeitsrate von 80 %, verarbeitete effizient Daten aus mehreren Quellen und lieferte detaillierte, zuverlässige Antworten auf komplexe Anfragen, ähnlich wie ein erfahrener Experte.
- Perplexity Pro sicherte sich den zweiten Platz mit einer Punktzahl von 70 % und zeigte Widerstandsfähigkeit bei der Bewältigung einiger komplexer Fragen.
- iAsk schnitt angemessen ab und erreichte eine Genauigkeitsrate von 60 % und lieferte gelegentlich effektive Antworten auf mehrdeutige Fragen.
- Perplexity Basic, GenSpark und You.com schnitten in dieser Bewertung schlecht ab. Ihre Sprachmodelle zeigten deutliche Schwächen im Verständnis und in der Verarbeitung mehrdeutiger Anfragen, mit Genauigkeitsraten von 55 %, 45 % und 35 %, was weniger als zufriedenstellend war.
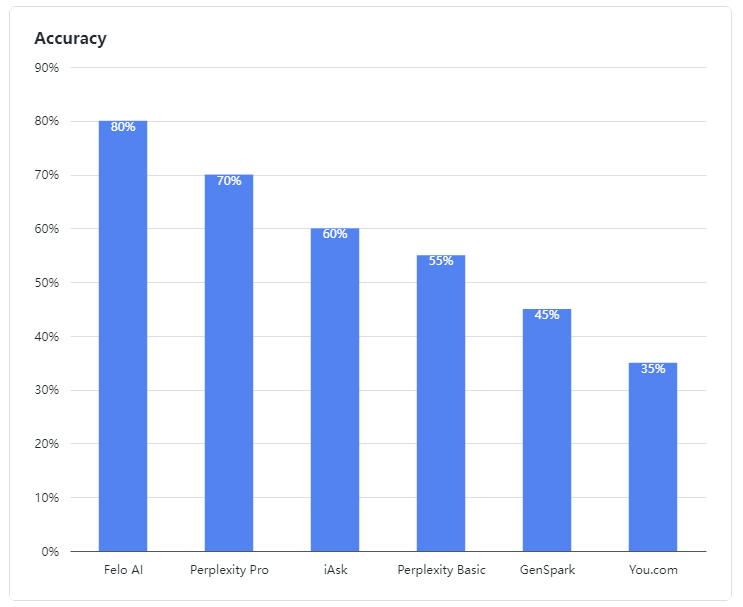
Abbildung 1: Genauigkeitsraten der bewerteten Produkte
II. Bewertungsdaten
In unserer Bewertung wurden mehrdeutige Fragen als solche definiert, die Softwarekonfigurationen, mehrere Datenquellen, Informationen, die nicht online verfügbar sind, oder datumsbezogene Informationen betreffen. LLMs setzen häufig Inhalte aus mehreren Quellen zusammen, um solche Fragen zu beantworten.
Unsere Testfälle für mehrdeutige Fragen sind Open Source:
👉 Testfälle: https://github.com/sparticleinc/ASEED/blob/main/datasets/ambiguity_search.csv
👉 Testergebnisse: https://github.com/sparticleinc/ASEED/tree/main/evaluations/promptfoo/ambiguity_search
III. Fallanalyse
👉 Frage: Wo werden die nächsten Olympischen Spiele stattfinden?
Wahrheitsgehalt: Die Olympischen Sommerspiele 2028, auch bekannt als die Spiele der XXXIV. Olympiade, werden in Los Angeles, USA, stattfinden.
Kommentar: Aufgrund der Fülle an Online-Informationen, die besagen, dass die nächsten Olympischen Spiele 2024 in Paris, Frankreich, stattfinden werden, antworteten alle Produkte außer Felo AI falsch.

