Claude Opus 4.8 veröffentlicht: Anthropics bisher leistungsstärkstes Modell

Anthropic hat soeben Claude Opus 4.8 veröffentlicht — schneller, ehrlicher und besser bei agentischen Aufgaben. Hier ist alles Neue und warum es für Entwickler wichtig ist.

Anthropic hat diese Woche Claude Opus 4.8 veröffentlicht. Es ist das leistungsstärkste Modell, das sie bisher allgemein verfügbar gemacht haben, und baut auf Opus 4.7 auf — mit Verbesserungen in den Bereichen Programmierung, logisches Denken, agentische Aufgaben und Ehrlichkeit. Der Preis bleibt gleich: 5 $ pro Million Eingabe-Token, 25 $ pro Million Ausgabe-Token.
Hier ist, was sich geändert hat und warum das für Entwickler, die darauf aufbauen, wichtig ist.
Was hat sich seit Opus 4.7 geändert?
Das hat sich tatsächlich verändert:
1. Bessere Urteilsfähigkeit und Ehrlichkeit
Opus 4.8 ist deutlich weniger anfällig dafür, unbegründete Aussagen zu machen oder Programmfehler unbemerkt durchgehen zu lassen. Laut den Bewertungen von Anthropic ist es etwa viermal weniger wahrscheinlich als sein Vorgänger, Fehler im eigenen Code zu übersehen. Solche Fortschritte sind entscheidend, wenn man einem Modell vertraut, eigenständig zu arbeiten.
Frühe Tester berichteten, dass es die richtigen Fragen stellt, eigene Fehler erkennt und widerspricht, wenn ein Plan keinen Sinn ergibt.
2. Stärkere agentische Leistung
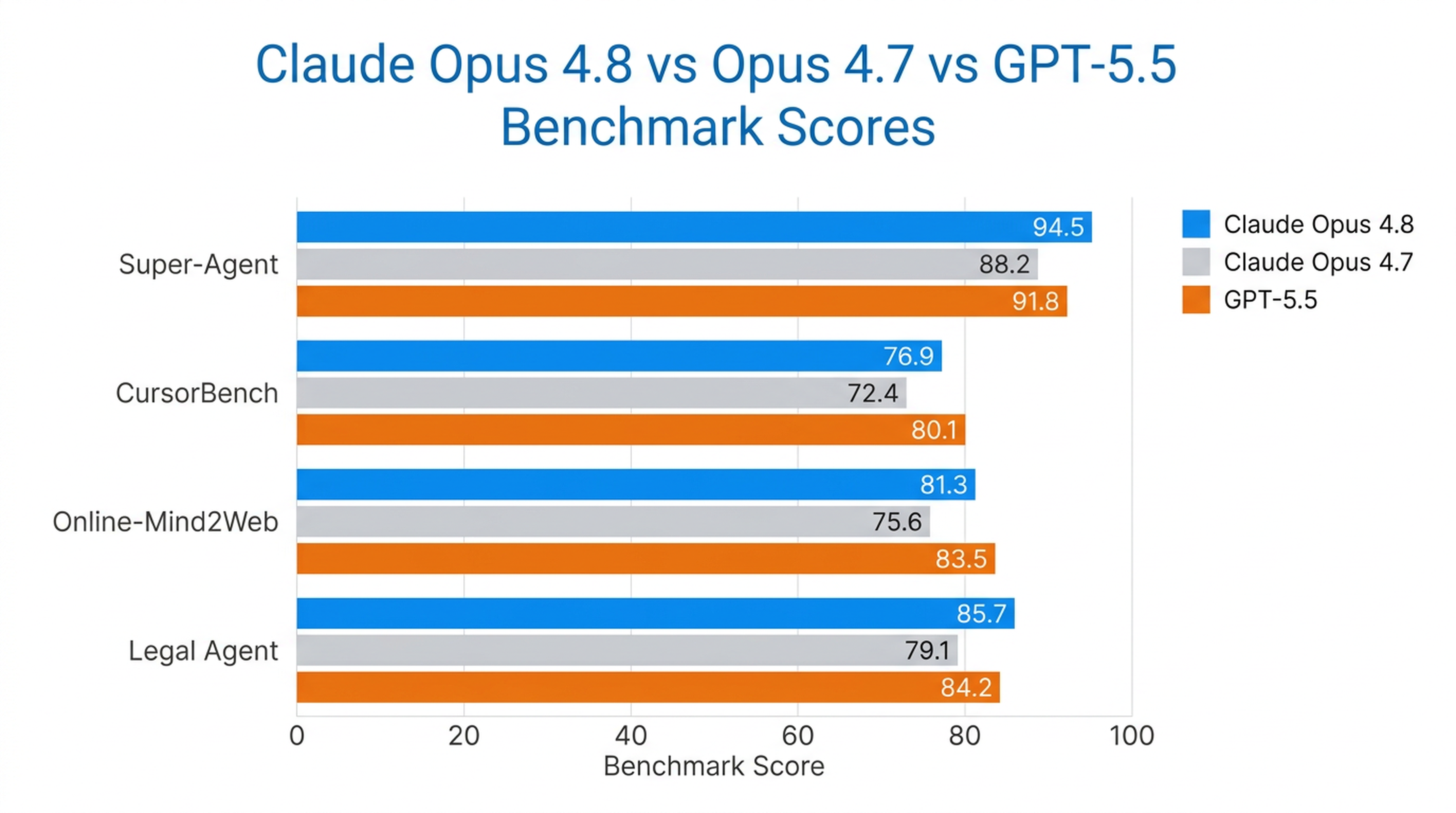
Opus 4.8 ist das einzige Modell, das alle Fälle im Super-Agent-Benchmark von Anthropic vollständig abschließen konnte — besser als frühere Opus-Modelle und GPT-5.5 bei gleichen Kosten. Im CursorBench übertrifft es vorherige Opus-Versionen auf allen Ebenen und benötigt für dieselbe Intelligenz weniger Tool-Aufrufe.
Auch bei Computer- und Browser-Agent-Aufgaben ist es das stärkste von Anthropic getestete Modell, mit 84 % im Online-Mind2Web-Test.
3. Schnellere, effizientere Tool-Aufrufe
Das Modell überspringt seltener einen erforderlichen Tool-Aufruf — ein bekanntes Problem von Opus 4.7. Lange agentische Abläufe bleiben nach Kontextkompression stärker aufgabentreu und entgleisen seltener.
4. Adaptives Denken, das sich tatsächlich anpasst
Mit aktiviertem adaptivem Denken entscheidet Opus 4.8 bei jedem Schritt, ob logisches Denken erforderlich ist. Einfache Suchanfragen erhalten direkte Antworten, komplexe Probleme werden zuerst analysiert. So werden weniger Token verschwendet als bei Opus 4.7.
Neue Funktionen, die Sie kennen sollten
Aufwandsteuerung — Jetzt in allen Tarifen
Ein neues Steuerelement neben der Modellauswahl erlaubt es Nutzern, festzulegen, wie viel Aufwand Claude in eine Antwort steckt. Opus 4.8 verwendet standardmäßig high als Aufwand, mit den Optionen extra und max für schwierigere Aufgaben. In Claude Code wurden die Ratenlimits erhöht, um den höheren Token-Verbrauch auszugleichen.
Schnellmodus — 2,5× Geschwindigkeit, geringere Kosten
Der Schnellmodus ist jetzt im Claude API als Forschungs-Vorschau für Opus 4.8 verfügbar. Er liefert bis zu 2,5× mehr Ausgabe-Token pro Sekunde bei einem dreifach niedrigeren Preis im Vergleich zu früheren Modellen.
Systemnachrichten während der Unterhaltung
Die Messages API akzeptiert jetzt Einträge mit role: "system" innerhalb des Nachrichten-Arrays. So können Sie Claudes Anweisungen mitten im Task anpassen, ohne den Prompt-Cache zu unterbrechen — nützlich, wenn sich Berechtigungen oder der Kontext während einer agentischen Schleife ändern.
Niedrigeres Mindestlimit für den Prompt-Cache
Die minimale Cache-Länge für Prompts wurde auf 1.024 Token gesenkt. Prompts, die bei Opus 4.7 zu kurz zum Caching waren, werden jetzt automatisch zwischengespeichert, ohne Änderungen am Code.
Praxisnahe Benchmarks
| Benchmark | Leistung von Opus 4.8 |
|---|---|
| Super-Agent | Alle Fälle vollständig abgeschlossen (einziges Modell mit vollem Durchlauf) |
| CursorBench | Übertrifft alle früheren Opus-Modelle in jeder Aufwandsstufe |
| Online-Mind2Web | 84 % (stärkstes getestetes Modell) |
| Legal Agent Benchmark | Höchste erzielte Punktzahl; erstes Modell über 10 % insgesamt |

Opus 4.8 glänzt besonders dort, wo langfristige Autonomie wichtig ist — Coding-Agents, Forschungs-Agents, juristische Workflows und wissensbasierte Unternehmensprozesse.
Preise — unverändert gegenüber Opus 4.7
| Modus | Eingabe | Ausgabe |
|---|---|---|
| Standard | 5 $ / 1 M Token | 25 $ / 1 M Token |
| Schnell | 10 $ / 1 M Token | 50 $ / 1 M Token |
Gleicher Preis wie bei Opus 4.7, aber höhere Leistung. Die Modell-ID in der API lautet claude-opus-4-8. Es unterstützt ein Kontextfenster von 1 M Token und bis zu 128 k Ausgabe-Token.
Was als Nächstes kommt: Mythos-Klasse-Modelle
Anthropic hat auch eine neue Modellklasse angekündigt — mit „noch höherer Intelligenz als Opus“. Eine kleine Zahl von Organisationen nutzt bereits Claude Mythos Preview für Cybersicherheitsarbeit im Rahmen von Project Glasswing. In den kommenden Wochen sollen Modelle der Mythos-Klasse allen Kunden zur Verfügung stehen, sobald entsprechende Sicherheitsvorkehrungen implementiert sind.
Warum Modellvielfalt wichtig ist
Neue KI-Modelle erscheinen mittlerweile wöchentlich. Für Entwickler stellt sich weniger die Frage, welches Modell „das beste“ ist, sondern welches für welche Aufgabe geeignet ist — und wie man reibungslos zwischen ihnen wechselt.
Genau dieses Problem adressiert Felo AI. Neben der KI-gestützten Suche, die auf moderne Modelle für Echtzeitergebnisse zugreift, bietet Felo auch einen LLM Playground, in dem Sie Ausgaben vieler führender Modelle an einem Ort testen und vergleichen können. Kein Jonglieren mit API-Schlüsseln, kein Wechsel zwischen Dashboards. Einfach ein Modell auswählen, den Prompt ausführen und die Ergebnisse vergleichen.
Wenn Sie Modelle für Ihren Workflow bewerten möchten oder einfach neugierig sind, erleichtert eine einheitliche Oberfläche den Vergleich deutlich.
Felo AI kostenlos ausprobieren → https://felo.ai
Dieser Beitrag ist auch in folgenden Sprachen verfügbar: English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, Français, العربية, Русский, اردو, Bahasa Indonesia, Tiếng Việt, Türkçe, Italiano, ไทย, Español, বাংলা and Português.