🙆♀️Felo AI bahnbrechende Errungenschaft: SimpleQA-Benchmark-Testgenauigkeit 91,2 %, führt neue Standards für die KI-Suche ein

Felo AI hat im SimpleQA-Benchmark-Test bahnbrechende Fortschritte erzielt und führt mit einer Genauigkeit von 91,2 % im Bereich der KI-Suche. Erfahren Sie, wie innovative Technologien wie die mehrsprachige Abfrageumformulierung das Sucherlebnis verbessern.
Revolutionierung von AI-Suchmaschinen mit unübertroffener Genauigkeit
Wir freuen uns, bekannt zu geben, dass Felo in den neuesten Ergebnissen des SimpleQA-Benchmark-Tests alle Wettbewerber übertroffen hat. SimpleQA ist ein von OpenAI entwickelter Schlüsseltest zur Bewertung der faktischen Genauigkeit in AI-Fragen und -Antworten. Mit einer beeindruckenden 91,2% Genauigkeit setzt Felo Pro (Schnellmodus) einen neuen Maßstab für AI-Suchmaschinen und übertrifft deutlich Wettbewerber wie Perplexity und Gemini.
SimpleQA-Benchmark: Der Prüfstein für AI-Suchmaschinen
SimpleQA wurde von OpenAI entwickelt, um die Effektivität von AI-Systemen bei der Beantwortung prägnanter faktischer Fragen mit Hilfe von Webdaten zu messen. Im Gegensatz zu traditionellen Suchmetriken konzentriert sich SimpleQA darauf, die Genauigkeit und Zuverlässigkeit von Fakten zu betonen und die Illusionsprobleme in AI-Systemen zu reduzieren – eine langanhaltende Herausforderung im Bereich der AI. Felo's herausragende Leistung in diesem Benchmark-Test zeigt unser Engagement, fortschrittliche Lösungen für AI-Suchmaschinen bereitzustellen.
Testmethodik: Strenges Bewertungsrahmenwerk
Felo hat für die Bewertung des SimpleQA-Benchmark-Tests einen standardisierten Rahmen verwendet, um Fairness und Transparenz zu gewährleisten. Die Methode umfasst folgende Schritte:
- Fragen: Die Fragen aus dem SimpleQA-Datensatz werden direkt an Felo übermittelt.
- Antwortgenerierung: Antworten werden mit Felo Pro (Schnellmodus) generiert.
Alle Tests wurden mit demselben Fragenkatalog und denselben Bewertungsstandards durchgeführt, die im ursprünglichen SimpleQA-Protokoll definiert sind, um einen fairen Vergleich zwischen allen Teilnehmern zu gewährleisten.
Testergebnisse: Felo erreicht branchenführende Genauigkeit
Die Ergebnisse des SimpleQA-Benchmark-Tests heben Felo's führende Position im Bereich der AI-intelligenten Suche hervor:
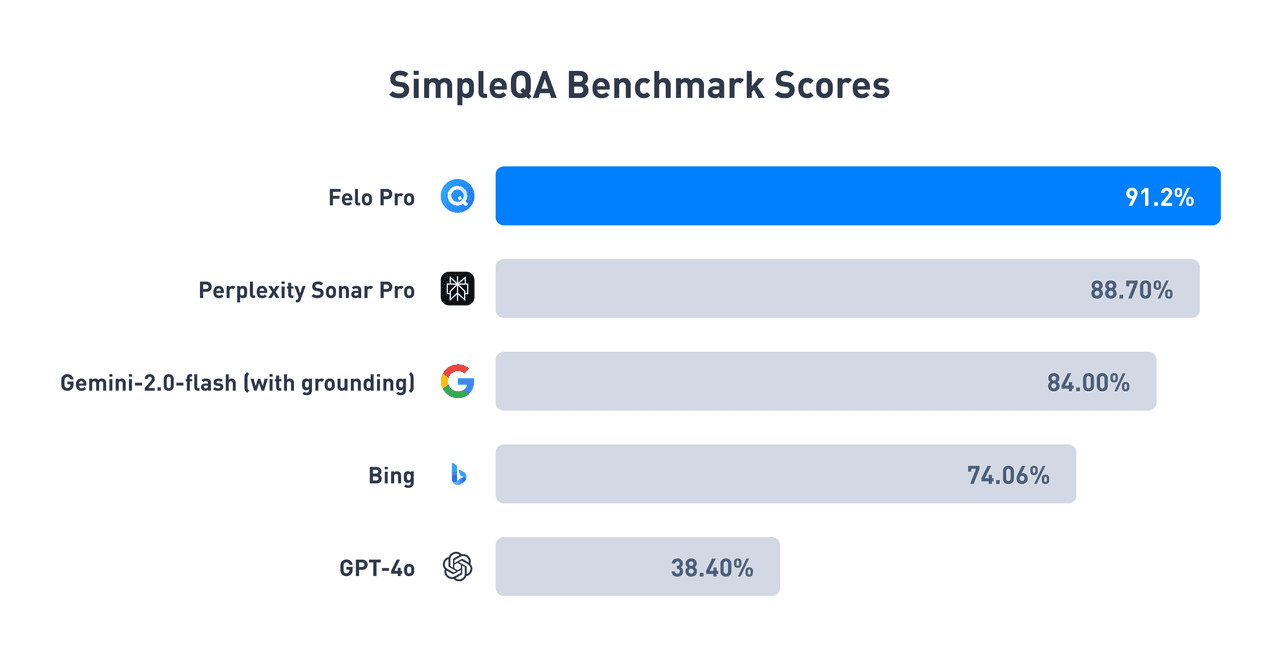
Wir haben die Testergebnisse von Felo open-source veröffentlicht, Sie können hier mehr Details erfahren.
Was macht Felo einzigartig?
Felo verdankt seine herausragende Leistung im SimpleQA-Benchmark-Test seiner innovativen Architektur und seinem Design. Die entscheidenden Unterschiede sind:
- Fortschrittliche mehrsprachige Abfrageumformulierung Felo kann ursprüngliche Abfragen intelligent in feinere Unterabfragen zerlegen und sogar die am besten geeignete Sprachumgebung für die Beantwortung der Benutzerfragen auswählen, wobei diese Unterabfragen für die Abfrage traditioneller Suchmaschinen und RAG-Systeme optimiert sind. Dies ermöglicht es Felo, mehr relevante Webseiten zu erfassen.
- Hybride Indizierungstechnologie Felo verwendet eine hybride Suchtechnologie, die Schlüsselwörter und semantische Suche kombiniert. Durch die Anwendung von modellbewusster semantischer Kompression auf den Webseiteninhalt entfernt Felo irrelevante Störgeräusche und behält gleichzeitig die entscheidende Faktendichte bei. Dies stellt sicher, dass das LLM (Large Language Model) nur die relevantesten und qualitativ hochwertigsten Informationen erhält.
- Fokussiertes Training auf Retrieval Im Gegensatz zu allgemeinen Suchmaschinen hat Felo sein Ranking-Modell speziell auf die einzigartige Art und Weise optimiert, wie große Sprachmodelle Informationen verarbeiten, und hat 7 eigene LLMs entwickelt, um präzisere, kontextbezogene Suchergebnisse zu liefern.