Wie man die OpenAI-Reasoning-Modelle verwendet: o1-preview/o1-Mini-Modelle - Kostenloser KI-Chat

Felo AI Chat unterstützt jetzt die kostenlose Nutzung des O1-Reasoning-Modells
In der sich schnell entwickelnden Landschaft der künstlichen Intelligenz hat OpenAI eine bahnbrechende Reihe von großen Sprachmodellen eingeführt, die als o1-Serie bekannt sind. Diese Modelle sind darauf ausgelegt, komplexe Denkaufgaben zu erfüllen, was sie zu einem leistungsstarken Werkzeug für Entwickler und Forscher gleichermaßen macht. In diesem Blogbeitrag werden wir untersuchen, wie man die Denkmodelle von OpenAI effektiv nutzen kann, wobei wir uns auf ihre Fähigkeiten, Einschränkungen und bewährte Praktiken für die Implementierung konzentrieren.
Felo AI Chat unterstützt jetzt die kostenlose Nutzung des O1-Denkmodells. Probieren Sie es aus!


Verstehen der OpenAI o1-Serie Modelle
Die o1-Serie Modelle unterscheiden sich von früheren Iterationen der Sprachmodelle von OpenAI aufgrund ihrer einzigartigen Trainingsmethodik. Sie nutzen verstärkendes Lernen, um ihre Denkfähigkeiten zu verbessern, was es ihnen ermöglicht, kritisch zu denken, bevor sie Antworten generieren. Dieser interne Denkprozess ermöglicht es den Modellen, eine lange Kette von Überlegungen zu produzieren, was besonders vorteilhaft ist, um komplexe Probleme anzugehen.
Hauptmerkmale der OpenAI o1-Modelle
1. **Fortgeschrittenes Denken**: Die o1-Modelle zeichnen sich durch wissenschaftliches Denken aus und erzielen beeindruckende Ergebnisse in wettbewerbsorientiertem Programmieren und akademischen Benchmarks. Zum Beispiel rangieren sie im 89. Perzentil auf Codeforces und haben eine Genauigkeit auf Doktoratsniveau in Fächern wie Physik, Biologie und Chemie gezeigt.
2. **Zwei Varianten**: OpenAI bietet zwei Versionen der o1-Modelle über ihre API an:
- **o1-preview**: Dies ist eine frühe Version, die für die Lösung schwieriger Probleme mit breitem Allgemeinwissen konzipiert ist.
- **o1-mini**: Eine schnellere und kostengünstigere Variante, die besonders für Programmier-, Mathematik- und Wissenschaftsaufgaben geeignet ist, die kein umfangreiches Allgemeinwissen erfordern.
3. **Kontextfenster**: Die o1-Modelle verfügen über ein erhebliches Kontextfenster von 128.000 Tokens, das umfangreiche Eingaben und Überlegungen ermöglicht. Es ist jedoch entscheidend, dieses Kontextfenster effektiv zu verwalten, um Token-Grenzen zu vermeiden.
Erste Schritte mit den OpenAI o1-Modellen
Um die o1-Modelle zu verwenden, können Entwickler über den Chat-Vervollständigungs-Endpunkt der OpenAI API darauf zugreifen.
Sind Sie bereit, Ihr KI-Interaktionserlebnis zu verbessern? Felo AI Chat bietet jetzt die Möglichkeit, das hochmoderne O1-Denkmodell kostenlos zu erkunden!
Probieren Sie das o1-Denkmodell kostenlos aus.
Beta-Einschränkungen der OpenAI o1-Modelle
Es ist wichtig zu beachten, dass sich die o1-Modelle derzeit in der Beta-Phase befinden, was bedeutet, dass es einige Einschränkungen gibt, die zu beachten sind:
Während der Beta-Phase sind viele Parameter der Chat-Vervollständigungs-API noch nicht verfügbar. Besonders bemerkenswert:
- Modalitäten: nur Text, Bilder werden nicht unterstützt.
- Nachrichtentypen: nur Benutzer- und Assistentennachrichten, Systemnachrichten werden nicht unterstützt.
- Streaming: nicht unterstützt.
- Tools: Tools, Funktionsaufrufe und Parameter für das Antwortformat werden nicht unterstützt.
- Logprobs: nicht unterstützt.
- Sonstiges:
temperature,top_pundnsind auf1festgelegt, währendpresence_penaltyundfrequency_penaltyauf0festgelegt sind. - Assistenten und Batch: Diese Modelle werden in der Assistenten-API oder der Batch-API nicht unterstützt.
**Verwaltung des Kontextfensters**:
Mit einem Kontextfenster von 128.000 Tokens ist es wichtig, den Raum effektiv zu verwalten. Jede Vervollständigung hat ein maximales Ausgabe-Token-Limit, das sowohl Denk- als auch sichtbare Vervollständigungs-Tokens umfasst. Zum Beispiel:
- **o1-preview**: Bis zu 32.768 Tokens
- **o1-mini**: Bis zu 65.536 Tokens
Geschwindigkeit der OpenAI o1-Modelle
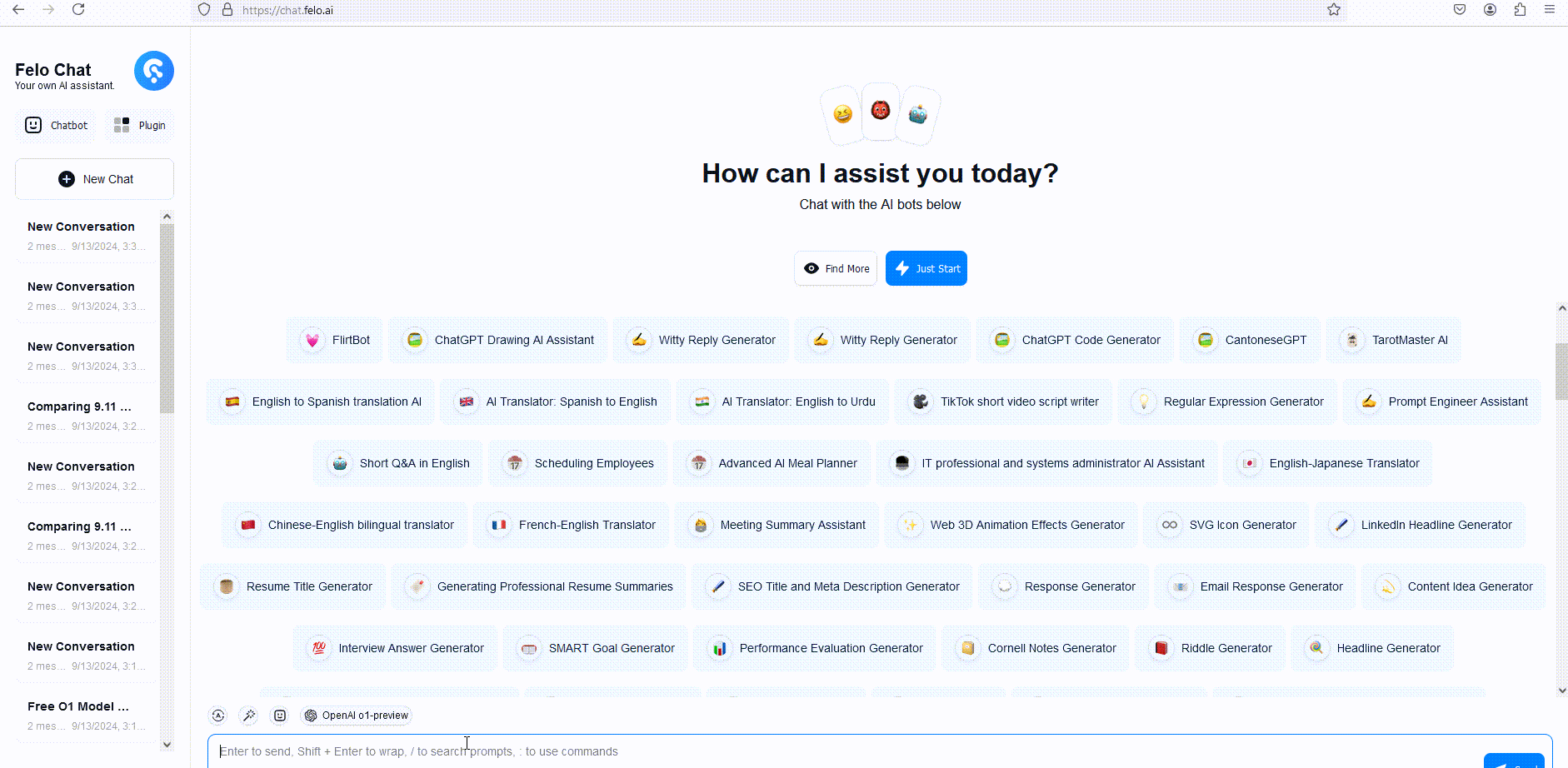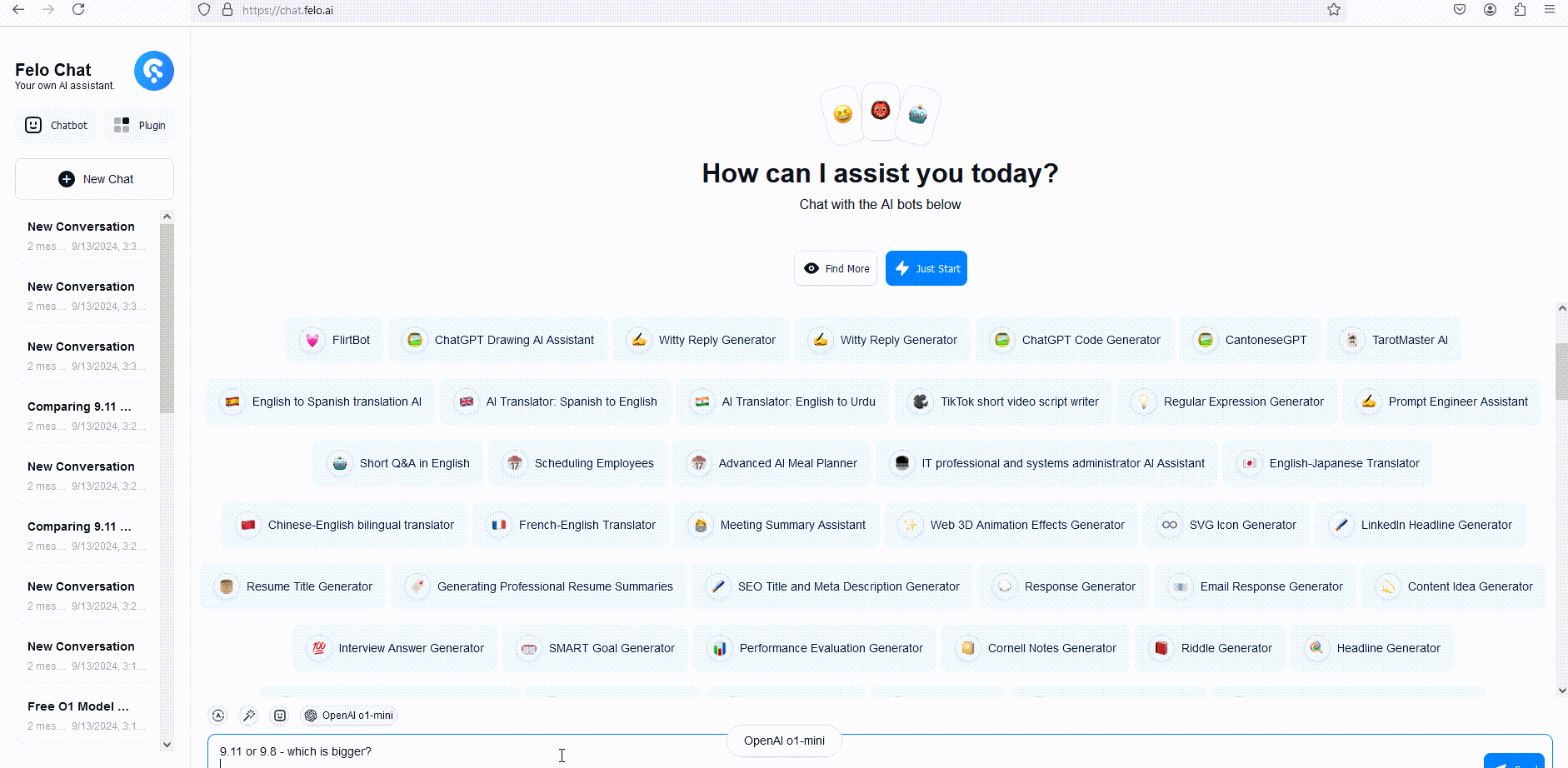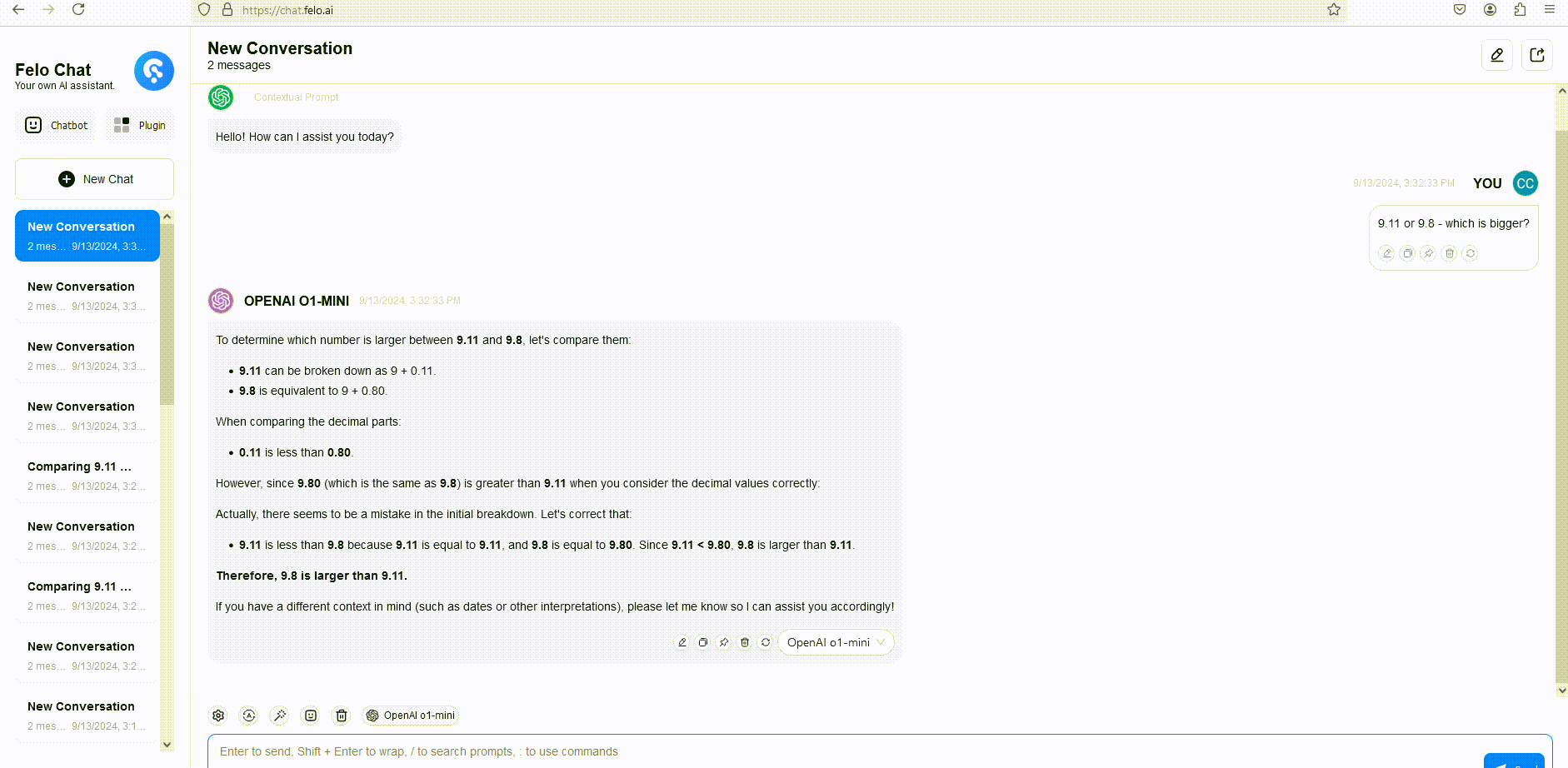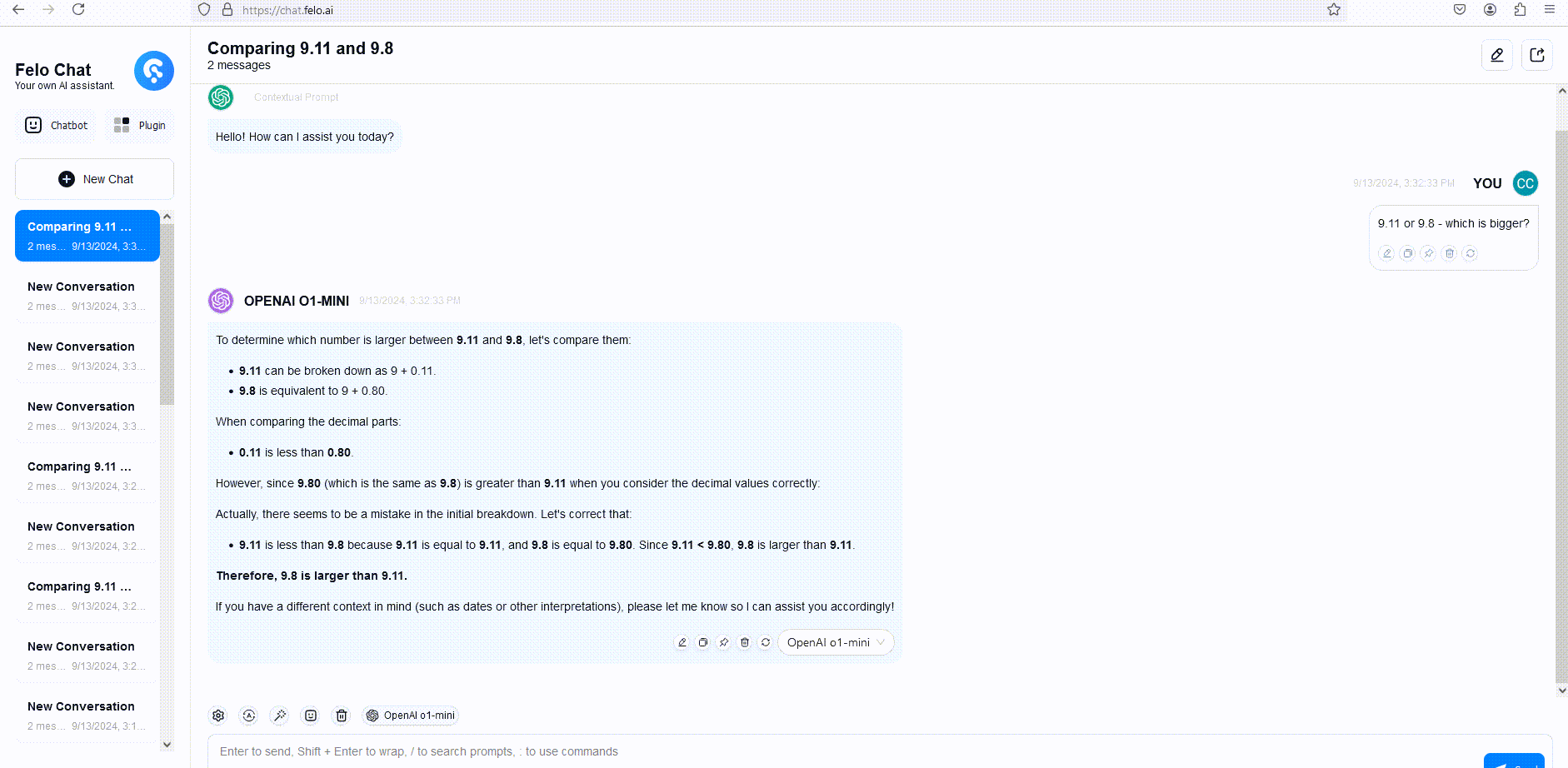
Um dies zu veranschaulichen, haben wir die Antworten von GPT-4o, o1-mini und o1-preview auf eine Wortdenkfrage verglichen. Obwohl GPT-4o eine falsche Antwort gab, antworteten sowohl o1-mini als auch o1-preview korrekt, wobei o1-mini die richtige Antwort etwa 3-5 Mal schneller fand.

Wie wählt man zwischen den Modellen GPT-4o, O1 Mini und O1 Preview?
**O1 Preview**: Dies ist eine frühe Version des OpenAI O1-Modells, das darauf ausgelegt ist, umfangreiches Allgemeinwissen für das Denken durch komplexe Probleme zu nutzen.
**O1 Mini**: Eine schnellere und erschwinglichere Version von O1, die besonders gut für Programmier-, Mathematik- und Wissenschaftsaufgaben geeignet ist, ideal für Situationen, die kein breites Allgemeinwissen erfordern.
Die O1-Modelle bieten erhebliche Verbesserungen im Denken, sind jedoch nicht dazu gedacht, GPT-4o in allen Anwendungsfällen zu ersetzen.
Für Anwendungen, die Bildinput, Funktionsaufrufe oder konsequent schnelle Antwortzeiten benötigen, sind die GPT-4o und GPT-4o Mini-Modelle nach wie vor die besten Optionen. Wenn Sie jedoch Anwendungen entwickeln, die tiefes Denken erfordern und längere Antwortzeiten in Kauf nehmen können, könnten die O1-Modelle eine großartige Wahl sein.
Tipps für effektives Prompting der O1 Mini- und O1 Preview-Modelle
Die OpenAI o1-Modelle arbeiten am besten mit klaren und einfachen Eingabeaufforderungen. Einige Techniken, wie z.B. Few-Shot-Prompting oder das Bitten des Modells, "Schritt für Schritt zu denken", könnten die Leistung nicht verbessern und sie sogar behindern. Hier sind einige bewährte Praktiken:
1. **Halten Sie Eingabeaufforderungen einfach und direkt**: Die Modelle sind am effektivsten, wenn sie kurze, klare Anweisungen erhalten, ohne dass umfangreiche Erläuterungen erforderlich sind.
2. **Vermeiden Sie Ketten von Gedankenaufforderungen**: Da diese Modelle das Denken intern handhaben, ist es nicht notwendig, sie zu bitten, "Schritt für Schritt zu denken" oder "Ihre Überlegungen zu erklären".
3. **Verwenden Sie Trennzeichen zur Klarheit**: Verwenden Sie Trennzeichen wie dreifache Anführungszeichen, XML-Tags oder Abschnittsüberschriften, um verschiedene Teile der Eingabe klar zu definieren, was dem Modell hilft, jeden Abschnitt korrekt zu interpretieren.
4. **Begrenzen Sie zusätzlichen Kontext in der Retrieval-Augmented Generation (RAG)**: Wenn Sie zusätzlichen Kontext oder Dokumente bereitstellen, fügen Sie nur die relevantesten Informationen hinzu, um die Antwort des Modells nicht zu komplizieren.
Preise für die o1 Mini- und 1 Preview-Modelle.
Die Kostenberechnung für die o1 Mini- und 1 Preview-Modelle unterscheidet sich von anderen Modellen, da sie zusätzliche Kosten für Denk-Tokens umfasst.
o1-mini Preisgestaltung
$3.00 / 1M Eingabe-Tokens
$12.00 / 1M Ausgabe-Tokens
o1-preview Preisgestaltung
$15.00 / 1M Eingabe-Tokens
$60.00 / 1M Ausgabe-Tokens
Verwaltung der Kosten für das o1-preview/o1-mini-Modell
Um die Ausgaben mit den o1-Serie-Modellen zu kontrollieren, können Sie den Parameter `max_completion_tokens` verwenden, um ein Limit für die Gesamtzahl der Tokens festzulegen, die das Modell generiert, einschließlich sowohl Denk- als auch Vervollständigungs-Tokens.
In früheren Modellen verwaltete der Parameter `max_tokens` sowohl die Anzahl der generierten Tokens als auch die Anzahl der für den Benutzer sichtbaren Tokens, die immer gleich waren. Mit der o1-Serie kann jedoch die Gesamtzahl der generierten Tokens die Anzahl der dem Benutzer angezeigten Tokens überschreiten, aufgrund interner Denk-Tokens.
Da einige Anwendungen darauf angewiesen sind, dass `max_tokens` mit der Anzahl der vom API empfangenen Tokens übereinstimmt, führt die o1-Serie `max_completion_tokens` ein, um speziell die Gesamtzahl der vom Modell produzierten Tokens zu steuern, einschließlich sowohl Denk- als auch sichtbarer Vervollständigungs-Tokens. Diese explizite Opt-in-Option stellt sicher, dass bestehende Anwendungen mit den neuen Modellen kompatibel bleiben. Der Parameter `max_tokens` funktioniert weiterhin wie bei allen vorherigen Modellen.
Fazit
Die o1-Serie von OpenAI stellt einen bedeutenden Fortschritt im Bereich der künstlichen Intelligenz dar, insbesondere in ihrer Fähigkeit, komplexe Denkaufgaben zu erfüllen. Durch das Verständnis ihrer Fähigkeiten, Einschränkungen und bewährten Praktiken für die Nutzung können Entwickler die Leistung dieser Modelle nutzen, um innovative Anwendungen zu erstellen. Während OpenAI weiterhin die o1-Serie verfeinert und erweitert, können wir noch aufregendere Entwicklungen im Bereich der KI-gesteuerten Denkprozesse erwarten. Egal, ob Sie ein erfahrener Entwickler oder ein Neuling sind, die o1-Modelle bieten eine einzigartige Gelegenheit, die Zukunft intelligenter Systeme zu erkunden. Viel Spaß beim Programmieren!
Felo AI Chat bietet Ihnen immer ein kostenloses Erlebnis mit fortschrittlichen KI-Modellen aus der ganzen Welt. Klicken Sie hier, um es auszuprobieren!