Lanzamiento de Claude Opus 4.8: El modelo más capaz de Anthropic hasta ahora

Anthropic acaba de lanzar Claude Opus 4.8: más rápido, más honesto y mejor en tareas agentivas. Aquí tienes todo lo nuevo y por qué importa para los desarrolladores.

Anthropic lanzó Claude Opus 4.8 esta semana. Es el modelo más capaz que han puesto a disposición general, basado en Opus 4.7 y con mejoras en codificación, razonamiento, tareas agentivas y honestidad. El precio se mantiene igual: 5 $ por millón de tokens de entrada, 25 $ por millón de tokens de salida.
Esto es lo que ha cambiado y por qué importa para los desarrolladores que trabajan sobre él.
¿Qué ha cambiado desde Opus 4.7?
Esto es lo que realmente ha cambiado:
1. Mejor juicio y honestidad
Opus 4.8 tiene una probabilidad significativamente menor de hacer afirmaciones sin fundamento o de dejar pasar errores de código sin mencionarlos. Las evaluaciones de Anthropic muestran que es aproximadamente cuatro veces menos propenso que su predecesor a permitir que fallos en su propio código pasen sin señalarlos. Ese tipo de mejora importa cuando confías en que un modelo trabaje de forma autónoma.
Los primeros evaluadores informaron que hace las preguntas correctas, detecta sus propios errores y cuestiona los planes cuando no tienen sentido.
2. Rendimiento agentivo más sólido
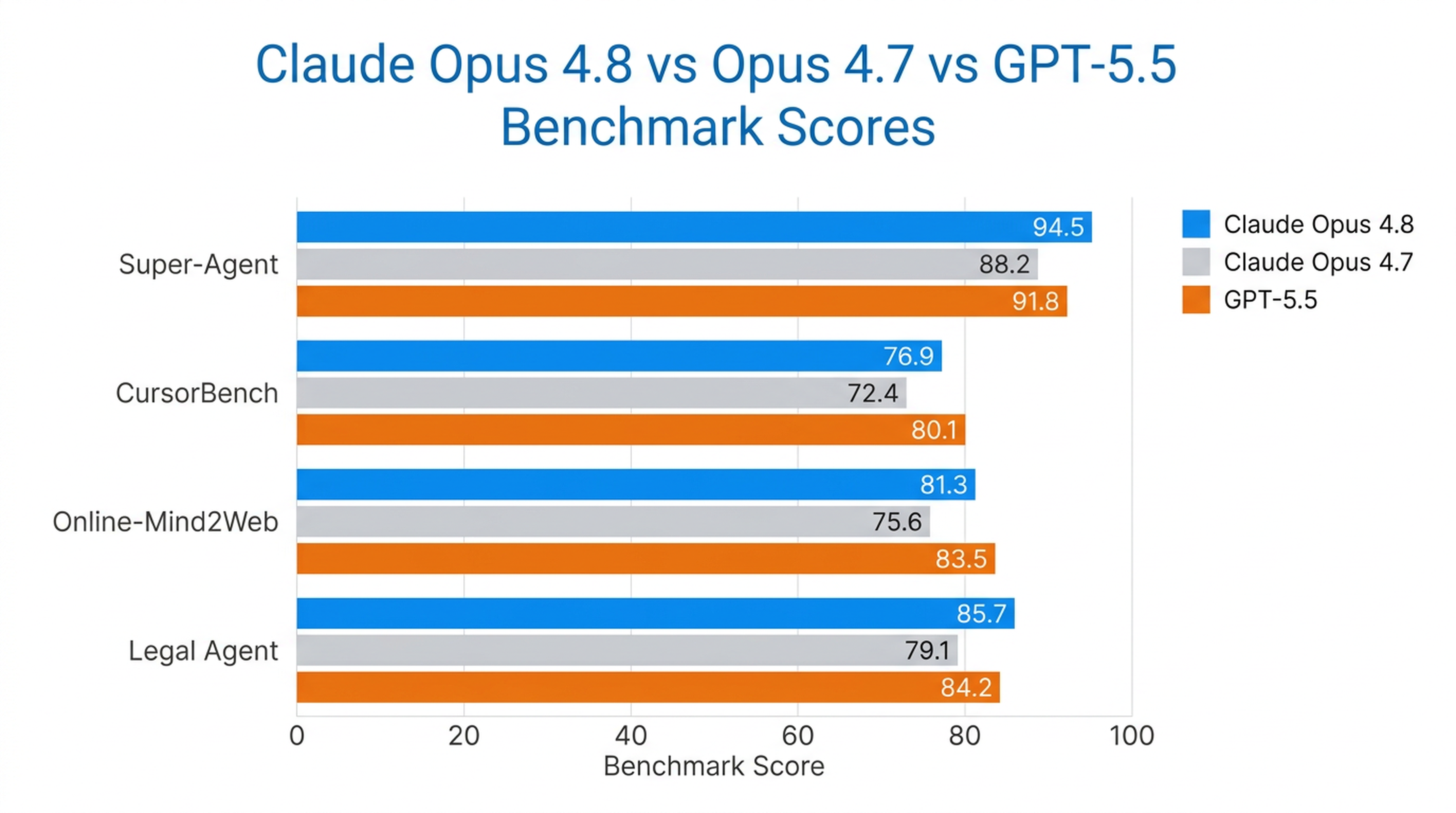
Opus 4.8 es el único modelo que completa todos los casos de principio a fin en el benchmark Super-Agent de Anthropic, superando a los modelos Opus anteriores y a GPT-5.5 con el mismo costo. En CursorBench, supera a las versiones previas de Opus en todos los niveles de esfuerzo, usando menos pasos de llamadas a herramientas para lograr la misma inteligencia.
También es el modelo más fuerte en tareas de uso del ordenador y agentes de navegador que Anthropic ha probado, con una puntuación del 84 % en Online-Mind2Web.
3. Llamadas a herramientas más rápidas y eficientes
El modelo es menos propenso a omitir una llamada a herramienta necesaria para una tarea, un problema conocido en Opus 4.7. Además, las trazas agentivas largas se mantienen enfocadas con menos desviaciones después de la compactación de contexto.
4. Pensamiento adaptativo que realmente se adapta
Con el pensamiento adaptativo activado, Opus 4.8 decide en cada turno si el razonamiento es necesario. Las consultas simples obtienen respuestas directas. Los problemas complejos reciben razonamiento antes de la respuesta. Menos tokens desperdiciados en comparación con Opus 4.7.
Nuevas funciones que vale la pena conocer
Control de esfuerzo — Ahora en todos los planes
Un nuevo control junto al selector de modelo permite a los usuarios elegir cuánto esfuerzo pone Claude en una respuesta. Opus 4.8 usa por defecto el nivel de esfuerzo high, con opciones extra y max para tareas más difíciles. Los límites de tasa en Claude Code se han incrementado para manejar el mayor uso de tokens.
Modo rápido — 2.5x más velocidad y menor costo
El modo rápido ya está disponible para Opus 4.8 como vista previa de investigación en la API de Claude. Ofrece hasta 2,5× más tokens de salida por segundo a un costo tres veces menor que los modelos anteriores.
Mensajes de sistema en mitad de conversación
La API de Mensajes ahora acepta entradas role: "system" dentro del arreglo de mensajes. Puedes actualizar las instrucciones de Claude durante la tarea sin romper la caché del prompt: útil cuando cambian los permisos o el contexto durante un ciclo agentivo.
Reducción del mínimo de caché de prompts
La longitud mínima de prompt almacenable en caché se redujo a 1 024 tokens. Los prompts que antes eran demasiado cortos para almacenarse en Opus 4.7 ahora crean entradas de caché sin necesidad de cambios de código.
Referencias del mundo real
| Benchmark | Rendimiento de Opus 4.8 |
|---|---|
| Super-Agent | Todos los casos completados de principio a fin (único modelo que lo logra) |
| CursorBench | Supera a todos los modelos Opus anteriores en todos los niveles de esfuerzo |
| Online-Mind2Web | 84 % (modelo más sólido probado) |
| Legal Agent Benchmark | Puntuación más alta registrada; primer modelo en superar el 10 % global |

Opus 4.8 destaca especialmente donde la autonomía a largo plazo es importante: agentes de programación, de investigación, flujos de trabajo legales y trabajo de conocimiento empresarial.
Precios — Sin cambios respecto a Opus 4.7
| Modo | Entrada | Salida |
|---|---|---|
| Estándar | 5 $ / 1 M tokens | 25 $ / 1 M tokens |
| Rápido | 10 $ / 1 M tokens | 50 $ / 1 M tokens |
Mismo precio que Opus 4.7, con mejor rendimiento. El ID del modelo en la API es claude-opus-4-8. Admite una ventana de contexto de 1 M de tokens y un máximo de salida de 128 k tokens.
Qué viene después: modelos de clase Mythos
Anthropic también insinuó una nueva clase de modelo con “una inteligencia aún mayor que la de Opus”. Un pequeño número de organizaciones ya utiliza Claude Mythos Preview para trabajos de ciberseguridad a través del Proyecto Glasswing. La empresa planea poner los modelos de clase Mythos a disposición de todos los clientes en las próximas semanas, una vez implementadas las medidas de seguridad.
Por qué importa la diversidad de modelos
Nuevos modelos de IA se lanzan cada semana. Para los desarrolladores que trabajan sobre ellos, la verdadera pregunta no es cuál es “el mejor” modelo, sino cuál es el adecuado para cada tarea y cómo cambiar entre ellos sin fricción.
Ese es el problema que aborda Felo AI. Más allá de su búsqueda potenciada por IA que obtiene respuestas en tiempo real de modelos avanzados, Felo ofrece un LLM Playground donde puedes invocar, probar y comparar resultados de una amplia gama de modelos líderes en un solo lugar. Sin necesidad de gestionar claves de API, sin cambiar entre paneles. Solo elige un modelo, ejecuta tu prompt y observa su rendimiento.
Si estás evaluando modelos para tu flujo de trabajo o simplemente tienes curiosidad por lo que hay disponible, tenerlos todos en una sola interfaz hace que el proceso de comparación sea mucho menos tedioso.
Prueba Felo AI gratis → https://felo.ai
Esta publicación también está disponible en English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, Français, العربية, Русский, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Türkçe, Italiano, ไทย, বাংলা and Português.