Felo Web Fetch para Google Antigravity: Extrae información de productos y del sitio web como datos estructurados

Aprende cómo la habilidad Felo Web Fetch brinda a los agentes de Google Antigravity la capacidad de extraer páginas web en Markdown, HTML o texto limpio para investigación de productos, inteligencia competitiva y recopilación de datos estructurados.
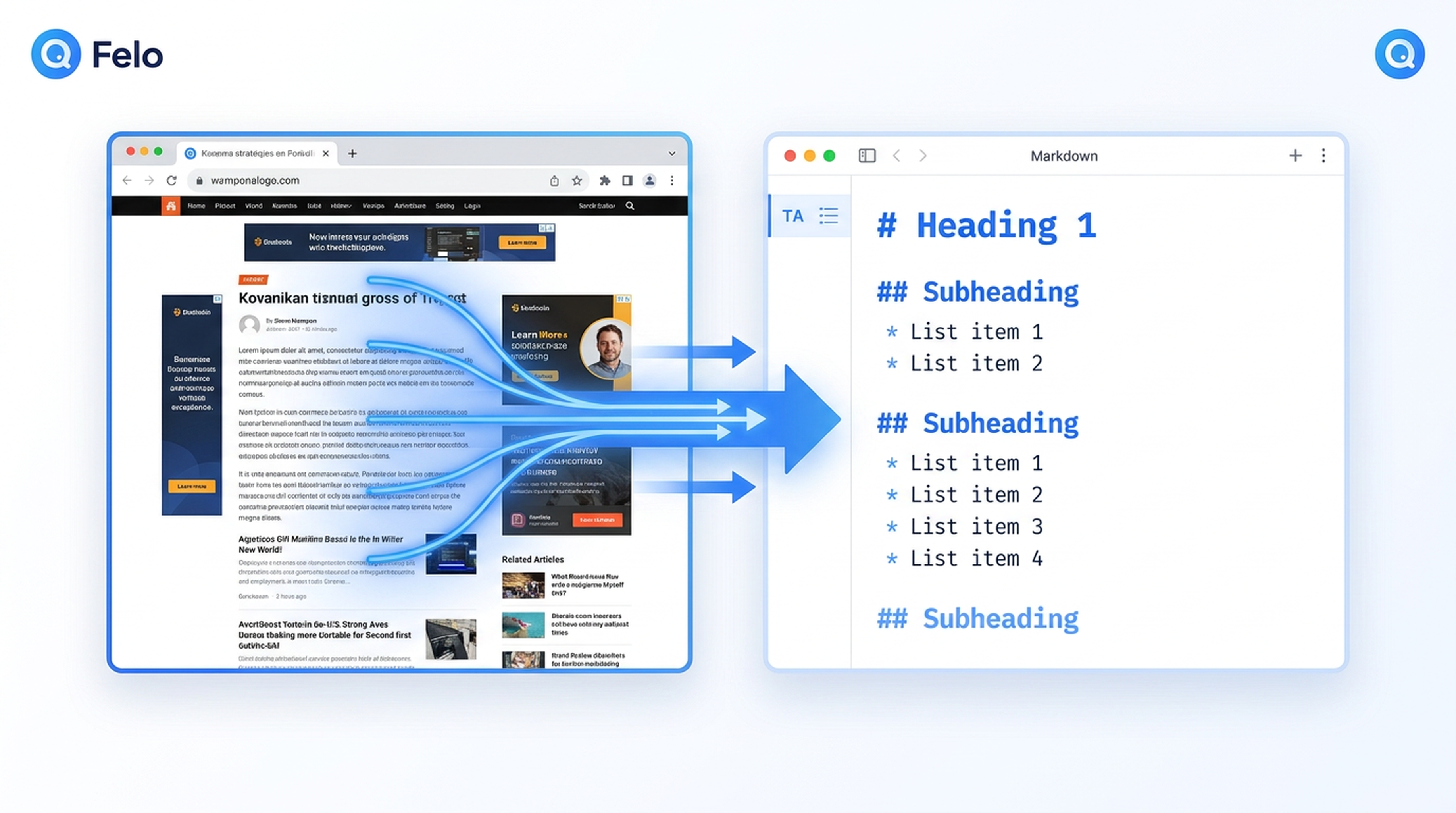
El problema inicial que enfrentan los agentes Antigravity
Le asignas a tu agente de Google Antigravity una tarea de investigación. Tal vez deba comparar precios de SaaS, recopilar listas de funciones de competidores o reunir material de referencia para un informe. El agente planifica bien. Sabe qué necesita. Pero se topa con una barrera: los datos de entrenamiento de Gemini 3 tienen una fecha límite, y el agente no puede acceder por sí mismo a la web en vivo.
Ahí es donde entran en juego las habilidades de Felo. En particular, la habilidad Felo Web Fetch cierra esa brecha de extracción: convierte cualquier página web en Markdown, HTML o texto limpio y estructurado que tu agente Antigravity realmente pueda usar.
¿Qué es Felo Web Fetch?
Felo Web Fetch es una habilidad basada en carpetas que colocas en el directorio .agent/skills/ de tu Google Antigravity. Una vez instalada, se convierte en una capacitación que se activa de forma autónoma: tu agente no necesita que escribas un comando con barra ni que copies y pegues URLs. Cuando una tarea requiere leer una página web, el Administrador de Agentes asocia la tarea con la descripción de la habilidad y la ejecuta automáticamente.
La habilidad usa la API Felo Web Extract (POST /v2/web/extract) para obtener contenido desde cualquier URL y devolverlo en el formato que tu flujo de trabajo necesite:
| Formato de salida | Cuándo usarlo |
|---|---|
| Markdown | Ideal para consumo por IA: estructura limpia con encabezados, listas y enlaces preservados |
| HTML | Cuando necesitas la estructura DOM sin procesar para procesamiento adicional |
| Texto | Extracción de texto plano, útil para un escaneo rápido o procesamiento posterior |
Instálala desde felo.ai/skills/antigravity: simplemente copia la carpeta en
.agent/skills/y haz commit en Git. Cada desarrollador de tu equipo obtendrá la capacidad en el siguiente pull.
Cómo funciona dentro de Antigravity
La ruta de instalación es intencionalmente sencilla:
# Clonar el repositorio de habilidades de Felo
git clone https://github.com/Felo-Inc/felo-skills.git
# Copiar la habilidad web-fetch a tu carpeta de habilidades de Antigravity
cp -r felo-skills/felo-web-fetch ~/.gemini/antigravity/skills/
Una vez que la carpeta felo-web-fetch está en .agent/skills/, el archivo SKILL.md hace el trabajo pesado. Su campo de descripción actúa como un disparador semántico. Cuando tu agente encuentra una tarea como "comparar precios entre estos tres productos SaaS" o "extraer la lista de funciones de esta página de competidor", el Administrador de Agentes carga la habilidad automáticamente, sin necesidad de invocación manual.
Capacidades principales
1. Modo de legibilidad para extracción limpia de artículos
No todas las páginas web están bien estructuradas. Blogs, artículos de noticias y documentación suelen tener barras de navegación, barras laterales, pies de página y anuncios. Felo Web Fetch admite un modo de legibilidad (--with-readability true) que extrae solo el contenido principal del artículo, eliminando todo lo demás.
Esto es especialmente valioso para los agentes Antigravity que realizan investigaciones: en lugar de analizar 200 KB de ruido de página, el agente recibe un cuerpo de artículo enfocado y legible — exactamente el contenido que necesita para su análisis.
2. Segmentación por selectores CSS para extracción precisa
A veces no quieres la página completa. Quieres la tabla de precios dentro de .pricing-section o el registro de cambios en div.changelog. Felo Web Fetch acepta un parámetro --target-selector, lo que te permite extraer solo el elemento DOM que te interesa.
Para flujos de trabajo de inteligencia competitiva, esto significa que tu agente puede obtener datos estructurados de precios, tablas comparativas de funciones o especificaciones de productos sin tener que filtrar contenido irrelevante.
3. Modos de rastreo: rápido vs. fino
| Modo | Ideal para |
|---|---|
fast | Páginas estáticas, documentación, publicaciones de blog — páginas que se renderizan de inmediato |
fine | Páginas con mucho JavaScript, SPAs, o aquellas que necesitan tiempo para renderizar contenido dinámico |
El valor predeterminado del Administrador de Agentes es fast, por eficiencia. Al extraer desde una página de producto basada en React o desde un panel que requiere autenticación, puedes cambiar a fine para asegurarte de que todo el contenido esté cargado antes de la extracción.
4. Compatibilidad con cookies y autenticación
Para páginas detrás de muros de inicio de sesión, Felo Web Fetch admite el paso de cookies (--cookie "session_id=xxx") y cadenas personalizadas de user-agent. Esto permite que tu agente Antigravity extraiga contenido de paneles autenticados, portales de documentación interna o páginas de socios, ampliando el rango de fuentes más allá de las URLs públicas.
5. Resúmenes estructurados: enlaces e imágenes
Además del contenido sin procesar, la habilidad puede incluir:
--with-links-summary true— todos los enlaces extraídos y resumidos--with-images-summary true— todas las imágenes extraídas con metadatos--with-images-readability true— imágenes asociadas con su contexto cercano
Para un agente de investigación que compila una visión general de producto, estos resúmenes se convierten en puntos de datos estructurados: enlaces de referencia para seguimiento, URLs de imágenes para comparación visual y metadatos contextuales que enriquecen el entregable final.
Casos de uso reales
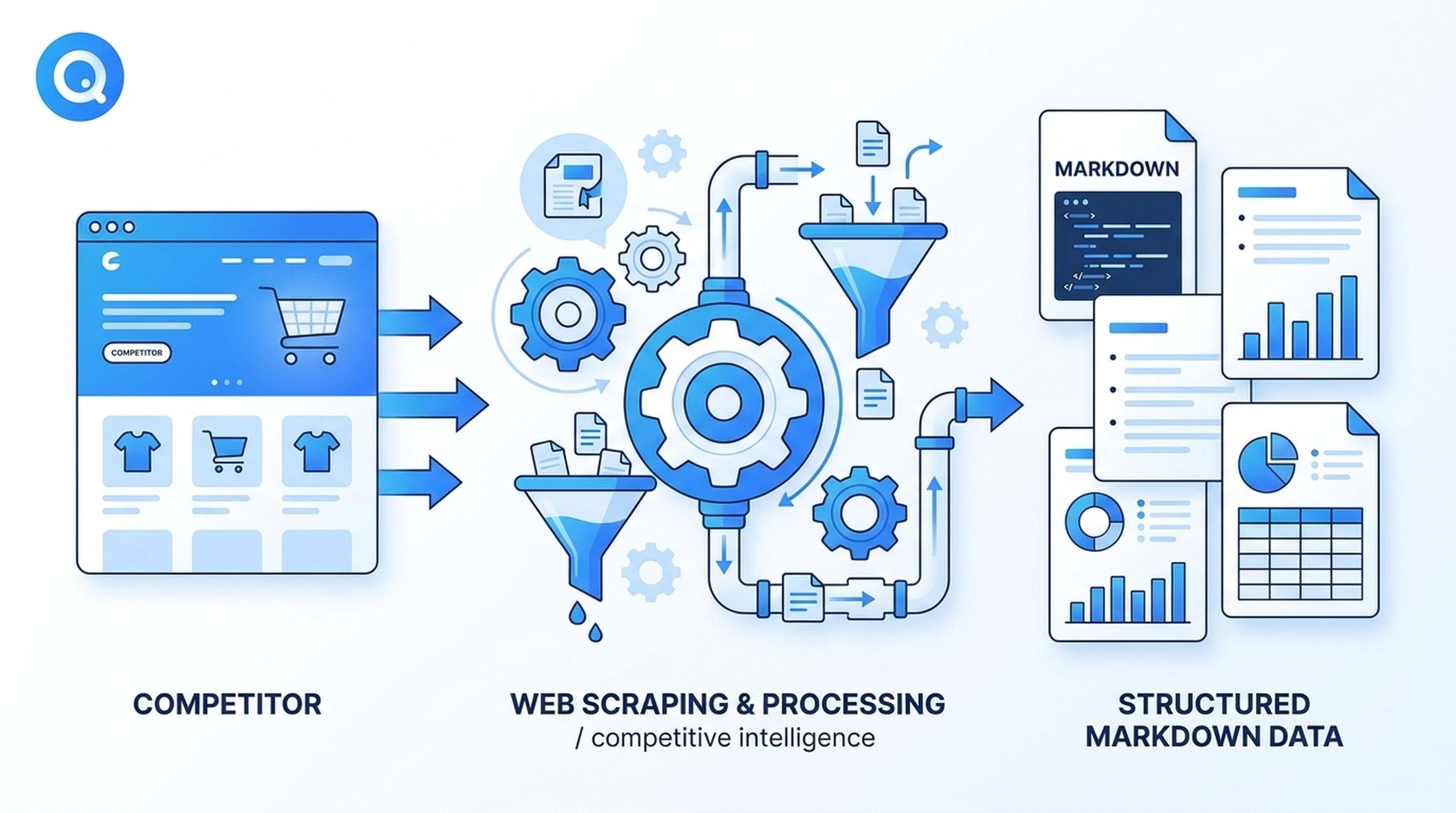
Inteligencia competitiva a escala
Imagina que tu agente Antigravity tiene la tarea de monitorear semanalmente las páginas de productos de tres competidores. Con Felo Web Fetch instalado, el agente:
- Visita automáticamente cada página de precios de los competidores
- Extrae el contenido como Markdown limpio
- Compara funciones, niveles de precios y nuevas adiciones con tu referencia
- Señala cualquier cambio desde la última extracción
El agente no necesita que obtengas las páginas manualmente. La habilidad se activa cuando la tarea coincide, extrae los datos y los devuelve al flujo de razonamiento del agente.
Investigación de productos y decisiones de compra
Cuando una tarea de agente implica evaluar herramientas, servicios o plataformas, Felo Web Fetch le da acceso a páginas de productos actuales, no a datos de entrenamiento obsoletos. El agente extrae especificaciones, precios, listas de integraciones y testimonios de usuarios directamente de la fuente, generando informes de compra basados en información real y actualizada.
Material de referencia para creación de contenido
Los equipos de contenido usan Antigravity para redactar informes, análisis de mercado y estudios de investigación. Felo Web Fetch proporciona al agente material documental proveniente de las páginas originales, asegurando que la producción del agente esté basada en fuentes primarias en lugar de aproximaciones.
Detección de cambios en documentación y APIs
Para los equipos de ingeniería, detectar cambios en la documentación de APIs, referencias de SDK o portales para desarrolladores es crucial. Felo Web Fetch puede extraer las páginas de documentación como Markdown, que el agente luego compara con versiones anteriores para identificar cambios importantes, nuevos endpoints o funcionalidades obsoletas.
Referencia de API para desarrolladores
Si integras Felo Web Fetch de forma programática (fuera de Antigravity), la API es sencilla:
curl -X POST "https://openapi.felo.ai/v2/web/extract" \
-H "Authorization: Bearer $FELO_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"url": "https://example.com/product",
"output_format": "markdown",
"with_readability": true,
"crawl_mode": "fast"
}'
Parámetros clave de la solicitud:
| Parámetro | Tipo | Predeterminado | Descripción |
|---|---|---|---|
url | string | — | URL de la página web a extraer |
output_format | string | html | html, markdown o text |
crawl_mode | string | fast | fast o fine |
with_readability | boolean | — | Extrae solo el contenido principal |
target_selector | string | — | Selector CSS para elementos específicos |
wait_for_selector | string | — | Espera a que el elemento aparezca antes de extraer |
timeout | integer | — | Tiempo máximo en milisegundos |
set_cookies | array | — | Cookies para páginas autenticadas |
Una respuesta exitosa devuelve el contenido extraído en data.content, estructurado según el output_format elegido.
Por qué esto importa para los equipos de Antigravity
El valor de Felo Web Fetch no está solo en la extracción en sí, sino en lo que la extracción habilita dentro del flujo de trabajo de tu agente Antigravity:
1. Los agentes trabajan con datos actuales, no con conocimiento almacenado. Gemini 3 no puede navegar la web. Felo Web Fetch llena ese vacío, dando a los agentes acceso al contenido real de cualquier URL en el momento de la extracción.
2. La salida estructurada significa razonamiento estructurado. Cuando el contenido llega como Markdown limpio, el agente puede analizar encabezados, listas, tablas y bloques de código, produciendo análisis basados en la verdadera estructura de la página.
3. Cero desviación de configuración. Como la habilidad vive en .agent/skills/ y se guarda en Git, cada desarrollador del equipo obtiene la misma capacidad. No hay configuraciones por usuario ni trucos específicos del entorno.
4. Funciona junto con otras habilidades de Felo. Combina Felo Web Fetch con Felo Search para verificación de investigación en vivo, o con Felo Slides para convertir el contenido extraído en presentaciones listas para compartir. El Administrador de Agentes orquesta la transición entre habilidades automáticamente.
Primeros pasos
Integrar Felo Web Fetch en tu flujo de trabajo Antigravity toma solo unos minutos:
- Visita felo.ai y crea una clave de API (Configuración → Claves de API)
- Configura la variable de entorno:
export FELO_API_KEY="your-api-key-here" - Copia la carpeta de la habilidad en tu directorio
.agent/skills/ - Haz commit en Git para que los agentes de tu equipo la obtengan automáticamente
Eso es todo. La próxima tarea del agente que implique leer una página web activará Felo Web Fetch automáticamente, sin intervención manual ni cambio de contexto.
Una mirada más amplia
Felo Web Fetch es una pieza del ecosistema más amplio de Felo Skills para Google Antigravity. Juntas, estas habilidades transforman el Administrador de Agentes de Antigravity de un planificador competente a una herramienta completa de investigación y producción, capaz de cerrar brechas de conocimiento, mantener memoria de equipo persistente y generar entregables terminados.
La capa de extracción que proporciona Felo Web Fetch suele ser la primera habilidad que los equipos instalan, porque resuelve el problema más inmediato: tu agente necesita leer la web, y Gemini 3 no puede hacerlo solo. Una vez que la extracción funciona, agregar búsqueda en vivo, bases de conocimiento persistentes y generación de resultados se vuelve un paso natural.
¿Listo para dar a tus agentes Antigravity la capacidad de extraer, analizar y actuar sobre contenido web real? Comienza con Felo Web Fetch: es gratis, basada en carpetas y lista para equipos desde el primer momento.
Esta publicación también está disponible en English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, Français, العربية, Русский, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Türkçe, Italiano, ไทย, বাংলা and Português.