Prueba DeepSeek V4 gratis en Felo LLM Playground

Felo LLM Playground agrega DeepSeek V4-Pro y V4-Flash el día del lanzamiento. Chatea con el modelo de código abierto de un billón de parámetros gratis — no se necesita clave API.
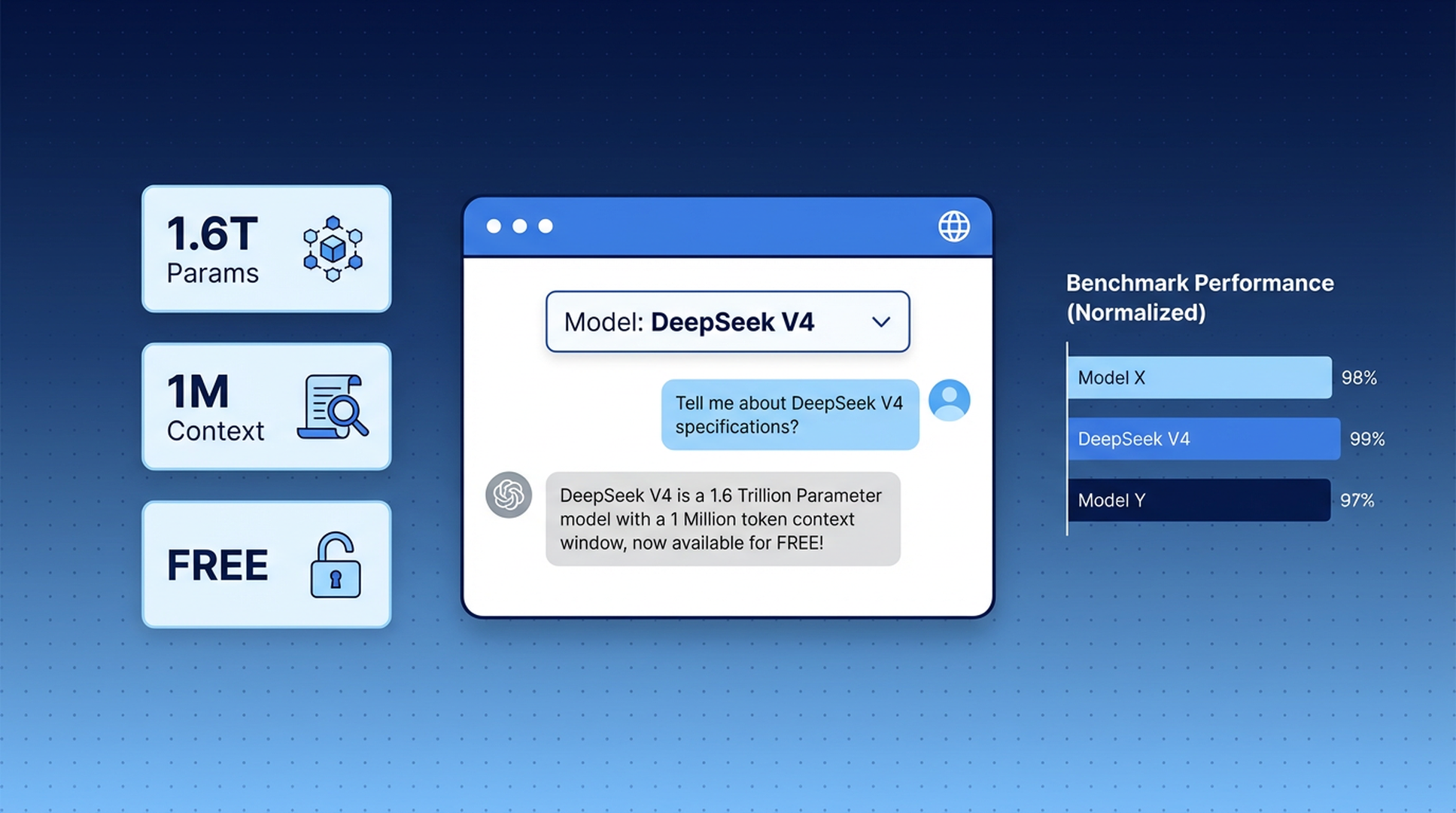
DeepSeek V4 se lanzó esta semana: un modelo de código abierto con un billón de parámetros que iguala a GPT-5.4 y Claude Opus 4.6 en la mayoría de los indicadores de referencia. Es el modelo de pesos abiertos más potente publicado hasta la fecha.
Puedes hablar con él ahora mismo en Felo LLM Playground, de forma gratuita. Sin clave API, sin créditos, sin necesidad de cuenta. Solo elige el modelo y empieza a conversar.
¿Qué es Felo LLM Playground?
Felo LLM Playground es una interfaz de chat gratuita basada en el navegador donde puedes hablar con los principales modelos de IA del mundo uno al lado del otro. Piénsalo como una cocina de pruebas para LLMs: tú aportas las preguntas y eliges qué modelo las responde.
Actualmente, el Playground admite modelos de OpenAI, Anthropic, Google y ahora DeepSeek. Puedes cambiar entre modelos en medio de una conversación, comparar respuestas y descubrir cuál funciona mejor para tu tarea específica, todo sin registrarte en cuentas API separadas ni gestionar facturación.
Está diseñado para cualquiera que quiera probar los modelos más recientes sin fricciones. Desarrolladores que evalúan modelos para un proyecto. Investigadores que comparan la calidad del razonamiento. Estudiantes que necesitan un asistente de IA competente pero no quieren pagar 20 $ al mes por cada proveedor. O cualquier persona que sienta curiosidad por experimentar cómo se siente usar un modelo con un billón de parámetros.
DeepSeek V4: a qué estás obteniendo acceso
DeepSeek V4 se presenta en dos variantes, y ambas están disponibles en el Playground:
DeepSeek V4-Pro es el modelo de tamaño completo. 1,6 billones de parámetros totales, 49 mil millones activos por consulta, entrenado con 32 billones de tokens. Maneja razonamiento complejo, programación, matemáticas y análisis de documentos extensos a un nivel que compite directamente con los mejores modelos cerrados.
DeepSeek V4-Flash es la versión rápida. 284 mil millones de parámetros totales, 13 mil millones activos. Te ofrece respuestas rápidas y competentes para preguntas cotidianas sin la latencia del modelo más grande.
Ambos comparten una ventana de contexto de un millón de tokens — suficiente para procesar una base de código completa, un documento de longitud de libro o meses de notas de reuniones en una sola conversación.
Cómo se compara
Aquí es donde V4-Pro se posiciona frente a los pesos pesados actuales:
| Prueba de referencia | DeepSeek V4-Pro | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|---|
| MMLU | 90.1% | ~91% | ~89% |
| HumanEval | 76.8% | ~78% | ~77% |
| SWE-bench Verificado | 80.6% | ~82% | ~80% |
| Puntuación en Codeforces | 3,206 | ~3,100 | ~2,900 |
| MATH | 64.5% | ~66% | ~63% |
V4-Pro lidera en programación competitiva y iguala o supera a GPT-5.4 en varias tareas de codificación. El modo de razonamiento extendido (V4-Pro-Max) obtuvo un 93.5% en LiveCodeBench y un 89.8% en IMOAnswerBench.
La brecha entre los modelos de código abierto y los modelos cerrados nunca ha sido tan pequeña. En algunas tareas, ha desaparecido por completo.
Cómo usar DeepSeek V4 en el Playground
Toma unos cinco segundos:
1. Abre el Playground.
Ve a playground.felo.ai en tu navegador. No se necesita inicio de sesión.
2. Elige DeepSeek V4 en el selector de modelos.
Verás un menú desplegable con todos los modelos disponibles. Elige V4-Pro para tareas complejas o V4-Flash para respuestas rápidas.
3. Comienza a chatear.
Escribe tu pregunta de forma natural. El modelo responde en tiempo real, igual que cualquier otra interfaz de chat que hayas usado antes.
Esa es toda la configuración. Sin clave de API, sin presupuestos de tokens, sin página de facturación.
Algunas cosas que vale la pena probar
Si no estás seguro de por dónde empezar, aquí tienes algunos ejemplos que muestran lo que V4 puede hacer:
- Pega un archivo de código largo y pídele a V4-Pro que encuentre errores o sugiera refactorizaciones
- Preséntale un problema de matemáticas — de nivel competitivo si quieres ponerlo a prueba
- Pídele que explique un concepto técnico de una manera específica ("explica los transformadores como si yo fuera un ingeniero de bases de datos")
- Pega el resumen de un artículo de investigación y pide un análisis crítico
- Prueba el mismo prompt en V4-Pro y GPT-5.4 uno al lado del otro — el Playground lo hace sencillo
Cuándo elegir V4-Pro vs. V4-Flash
Ambos modelos están disponibles en el Playground, y elegir entre ellos es sencillo.
V4-Pro es el que se debe usar cuando la pregunta es difícil. Síntesis de investigaciones, depuración de código complejo, demostraciones matemáticas, análisis de documentos extensos, cualquier tarea que se beneficie del razonamiento profundo. Es más lento, pero piensa con más profundidad.
V4-Flash es para todo lo demás. Búsquedas rápidas de información, redacción de textos, lluvia de ideas, traducciones, resúmenes. Responde más rápido y maneja las tareas rutinarias tan bien como el modelo más grande. Si vas a hacer muchas preguntas durante una sesión, V4-Flash mantiene todo en movimiento.
Una buena regla general: comienza con V4-Flash. Si la respuesta parece superficial o la tarea es claramente compleja, cambia a V4-Pro. El Playground te permite cambiar de modelo en medio de la conversación, así que no hay penalización por experimentar.
Por qué el Playground es importante para probar nuevos modelos
Cada vez que se lanza un nuevo modelo, surge el mismo problema: ¿cómo probarlo realmente?
La API oficial requiere registrarse, añadir una tarjeta de crédito, escribir código para hacer solicitudes y gestionar los costos de los tokens. Eso está bien si vas a integrar el modelo en un producto. Pero es excesivo si solo quieres hacerle unas cuantas preguntas y ver cómo razona.
Felo LLM Playground elimina todo ese proceso. Se lanza un nuevo modelo, abres una pestaña del navegador y ya lo estás usando. Sin configuración, sin costo, sin compromiso.
Esto importa más de lo que parece. La diferencia entre "Debería probar ese nuevo modelo" y realmente probarlo suele ser unos 20 minutos de configuración de cuenta y de API. El Playground reduce eso a cero.
También hace que la comparación de modelos sea práctica. ¿Quieres saber si DeepSeek V4 maneja tu caso de uso mejor que Claude o GPT? Haz la misma pregunta a cada modelo en pestañas adyacentes. Aprenderás más en cinco minutos de pruebas prácticas que leyendo tablas de referencias.
Qué hace que valga la pena probar DeepSeek V4
Más allá de los números de referencia, V4 tiene algunas cosas que realmente vale la pena experimentar de primera mano:
Tres modos de razonamiento. V4 ofrece Non-Think (respuestas rápidas y directas), Think High (análisis paso a paso) y Think Max (esfuerzo máximo de razonamiento). Puedes notar la diferencia: Think Max en un problema de matemáticas difícil produce un trabajo notablemente más completo que el modo predeterminado. En el Playground, esto significa que puedes ajustar cuánta computación aplica el modelo a tu pregunta. Una verificación rápida de hechos no necesita Think Max. Una demostración complicada, sí.
Rendimiento multilingüe sólido. V4 fue entrenado con un fuerte énfasis en datos multilingües. Si trabajas entre varios idiomas —inglés y chino, japonés y coreano, o cualquier combinación—, V4 maneja bien el cambio de código y las preguntas entre idiomas. Haz una pregunta en inglés sobre una fuente en chino y no perderá el ritmo.
Capacidad de programación. Con una calificación de Codeforces de 3,206 y un 80.6% en SWE-bench, V4-Pro es uno de los modelos de programación más potentes que puedes usar hoy. Pídele que escriba una función, revise una solicitud de extracción o explique por qué tu expresión regular no hace coincidencia, y será consistentemente bueno. El Playground es una forma rápida de probar esto: pega un fragmento, pide una revisión y compara los comentarios de V4 con los de Claude o GPT.
El contexto de un millón de tokens. La mayoría de los modelos tienen un límite de 128K o 200K tokens. V4 maneja un millón. Eso equivale aproximadamente a 750,000 palabras —unas 10 novelas completas, o toda la documentación interna de una empresa mediana. Puedes pegar la base de código completa de un proyecto y hacer preguntas sobre esta sin dividirla ni resumirla primero. Los modelos anteriores te obligaban a fragmentar ese trabajo. V4 lo asume completo.
Casos de uso prácticos en el Playground
A continuación se presentan algunas formas en que las personas ya están utilizando DeepSeek V4 en el Playground:
Desarrolladores pegan código y le piden a V4-Pro que lo revise, sugiera optimizaciones o explique patrones desconocidos. El contexto de un millón de tokens significa que puedes incluir un módulo completo —no solo una sola función— y obtener comentarios que consideren el panorama completo. Algunos desarrolladores usan V4-Flash para preguntas rápidas de sintaxis y V4-Pro para discusiones a nivel de arquitectura.
Estudiantes usan V4-Pro-Max para ejercicios de matemáticas y ciencias. El modo de razonamiento Think Max recorre las demostraciones paso a paso, lo que lo hace útil no solo para obtener respuestas, sino también para comprender el enfoque. También es fuerte explicando conceptos a diferentes niveles: pídele que explique el descenso de gradiente para un estudiante de primer año versus un candidato a doctorado, y obtendrás respuestas significativamente diferentes.
Investigadores proporcionan a V4 resúmenes de artículos o secciones completas y solicitan análisis crítico, brechas metodológicas o conexiones con trabajos relacionados. El entrenamiento multilingüe también es útil aquí: V4 puede trabajar con fuentes en chino, japonés o coreano y discutirlas en inglés sin perder matices.
Escritores y profesionales del marketing usan V4-Flash para lluvia de ideas, redacción y edición. Es lo suficientemente rápido para el trabajo iterativo: escribe un borrador, recibe retroalimentación, revisa y repite, sin la latencia que hace frustrantes a los modelos más grandes para sesiones de ida y vuelta.
Comparación de DeepSeek V4 con otros modelos en el Playground
El Playground te da acceso a modelos de múltiples proveedores. Así es como encaja V4:
En tareas de programación, V4-Pro está entre los mejores disponibles. Supera a Claude Opus 4.6 en Codeforces y SWE-bench, y se alterna el liderazgo con GPT-5.4 dependiendo de la tarea específica.
En cuanto a redacción y seguimiento de instrucciones, Claude todavía tiene una ventaja. Si necesitas una prosa matizada o una adhesión cuidadosa a instrucciones de formato complejas, los modelos de Claude tienden a ser más confiables.
En conocimientos generales y razonamiento, V4-Pro, GPT-5.4 y Gemini 3.1 Pro están todos dentro de unos pocos puntos porcentuales entre sí. La diferencia práctica es difícil de notar en la mayoría de las preguntas.
En velocidad para tareas rutinarias, V4-Flash es difícil de superar. Es lo suficientemente rápido y capaz para la gran mayoría de las preguntas cotidianas.
La verdadera ventaja del Playground es que no tienes que fiarte de la palabra de nadie. Haz tu propia comparación. Los modelos están todos ahí.
Preguntas frecuentes
¿DeepSeek V4 es realmente gratuito en Felo Playground?
Sí. Tanto V4-Pro como V4-Flash están disponibles sin costo. No necesitas crear una cuenta ni ingresar información de pago.
¿Necesito instalar algo?
No. Felo LLM Playground se ejecuta completamente en el navegador en playground.felo.ai. Funciona en computadoras de escritorio y dispositivos móviles.
¿Puedo usar DeepSeek V4 en idiomas distintos del inglés?
Sí. V4 funciona bien en inglés, chino, japonés, coreano y muchos otros idiomas. Fue entrenado con un fuerte enfoque multilingüe.
¿Cuál es la diferencia entre Felo Playground y Felo Search?
Felo Search combina modelos de IA con búsqueda web en tiempo real para ofrecerte respuestas basadas en información actual, con citas. El Playground es una interfaz de chat directa — sin búsqueda web, solo tú y el modelo. Usa Search cuando necesites datos actualizados; usa el Playground cuando quieras razonar, programar, escribir o explorar ideas.
¿Hay un límite de uso?
El Playground es gratuito. Pueden aplicarse límites de velocidad específicos durante los períodos de alto tráfico, pero no hay presupuestos de tokens ni límites diarios para el uso normal.
Prueba DeepSeek V4 ahora
DeepSeek V4 está disponible en Felo LLM Playground. Abre una pestaña, elige el modelo y descubre lo que un modelo de código abierto con un billón de parámetros puede hacer por tu trabajo.