Rapport d'évaluation des questions floues du moteur de recherche IA (v1.3)

Cet article évalue la performance de plusieurs moteurs de recherche IA dans le traitement des "questions de requête floues." Felo AI a obtenu les meilleurs résultats avec un taux de précision de 80%, suivi de Perplexity Pro. L'article analyse les forces et les faiblesses de chaque produit et fournit des études de cas spécifiques à titre d'illustration. Les données et résultats de l'évaluation ont été rendus open source, offrant des perspectives précieuses pour le développement des moteurs de recherche IA.
I. Conclusion
Dans l'ère saturée d'informations d'aujourd'hui, alors que les requêtes des utilisateurs deviennent de plus en plus complexes, l'écart de performance entre les systèmes de recherche AI devient de plus en plus apparent. Cela est particulièrement vrai lorsqu'il s'agit de configurations logicielles, de multiples sources de données, d'informations non disponibles en ligne ou de requêtes liées à des dates. Nous faisons référence à ces requêtes difficiles comme des "recherches de questions ambiguës". Dans cette évaluation, nous avons testé de manière exhaustive plusieurs moteurs de recherche AI populaires, y compris Perplexity Basic, Perplexity Pro, GenSpark, Felo AI, iAsk et You.com, en nous concentrant sur ce type de requête.
Après une série de tests rigoureux, nous avons conclu :
- Felo AI s'est démarqué comme le meilleur performer, démontrant une capacité exceptionnelle à traiter des requêtes ambiguës. Il a mené le peloton avec un impressionnant taux de précision de 80 %, traitant efficacement des données multi-sources et fournissant des réponses détaillées et fiables à des requêtes complexes, tout comme un expert expérimenté.
- Perplexity Pro a sécurisé la deuxième place avec un score de 70 %, montrant une résilience face à certaines questions complexes.
- iAsk a obtenu des résultats adéquats, atteignant un taux de précision de 60 % et fournissant parfois des réponses efficaces à des questions ambiguës.
- Perplexity Basic, GenSpark, et You.com ont sous-performé dans cette évaluation. Leurs modèles linguistiques ont montré des faiblesses claires dans la compréhension et le traitement des requêtes ambiguës, atteignant des taux de précision de 55 %, 45 % et 35 % respectivement, ce qui était moins que satisfaisant.
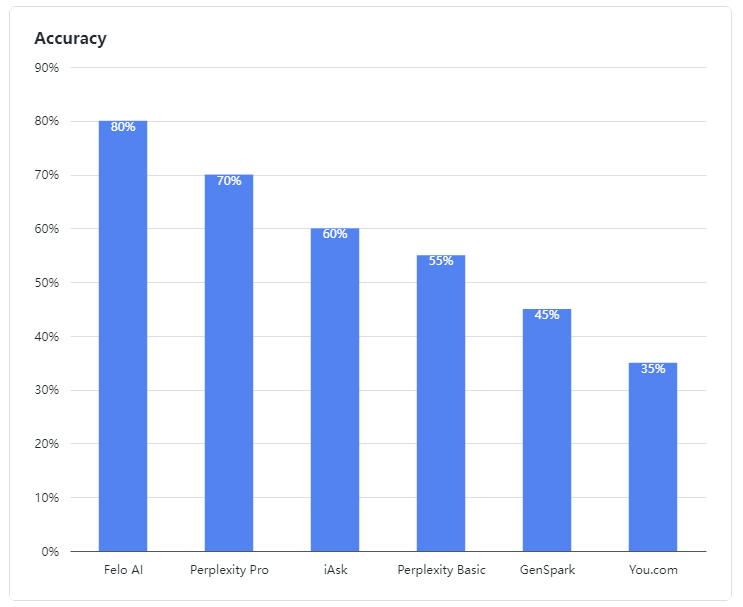
Figure 1 : Taux de précision des produits évalués
II. Données d'évaluation
Dans notre évaluation, les questions ambiguës étaient définies comme celles impliquant des configurations logicielles, plusieurs sources de données, des informations non disponibles en ligne ou des informations liées aux dates. Les LLMs assemblent souvent du contenu provenant de plusieurs sources pour répondre à de telles questions.
Nos cas de test de questions ambiguës sont open-source :
👉 Cas de test : https://github.com/sparticleinc/ASEED/blob/main/datasets/ambiguity_search.csv
👉 Résultats des tests : https://github.com/sparticleinc/ASEED/tree/main/evaluations/promptfoo/ambiguity_search
III. Analyse de cas
👉 Question : Où se tiendront les prochains Jeux Olympiques ?
Vérité de terrain : Les Jeux Olympiques d'été de 2028, également connus sous le nom de Jeux de la XXXIV Olympiade, se tiendront à Los Angeles, aux États-Unis.
Commentaire : En raison de l'abondance d'informations en ligne indiquant que les prochains Jeux Olympiques se tiendront à Paris, France en 2024, tous les produits sauf Felo AI ont répondu incorrectement.

