Claude Opus 4.8 publié : le modèle le plus performant d’Anthropic à ce jour

Anthropic vient de publier Claude Opus 4.8 — plus rapide, plus honnête et meilleur pour les tâches agentiques. Voici toutes les nouveautés et pourquoi elles comptent pour les développeurs.

Anthropic a publié Claude Opus 4.8 cette semaine. C’est le modèle le plus performant qu’ils aient rendu disponible au public, s’appuyant sur Opus 4.7 avec des améliorations dans le code, le raisonnement, les tâches agentiques et l’honnêteté. Le prix reste le même : 5 $ par million de jetons d’entrée, 25 $ par million de jetons de sortie.
Voici ce qui a changé et pourquoi cela compte pour les développeurs qui construisent dessus.
Ce qui a changé depuis Opus 4.7
Voici ce qui a réellement évolué :
1. Meilleur jugement et plus d’honnêteté
Opus 4.8 est beaucoup moins enclin à faire des affirmations non fondées ou à laisser passer des défauts de code sans les signaler. Les évaluations d’Anthropic montrent qu’il est environ quatre fois moins susceptible que son prédécesseur de laisser passer des bogues dans son propre code sans les repérer. C’est le genre d’amélioration qui compte lorsqu’on fait confiance à un modèle pour fonctionner de manière autonome.
Les premiers testeurs ont rapporté qu’il pose les bonnes questions, corrige ses propres erreurs et remet en question un plan quand il n’a pas de sens.
2. Meilleures performances agentiques
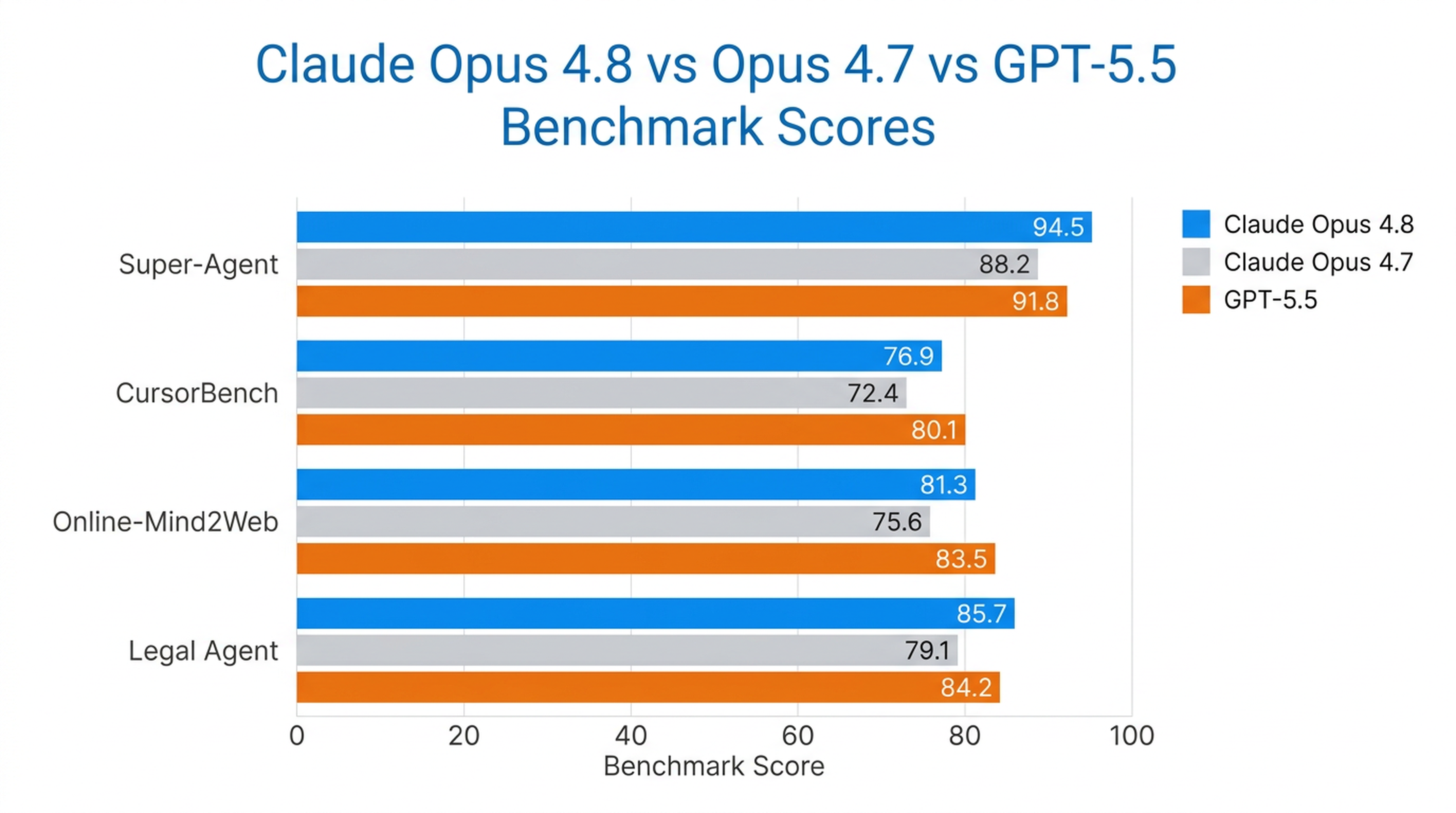
Opus 4.8 est le seul modèle à avoir terminé chaque cas de bout en bout sur le benchmark Super‑Agent d’Anthropic, surpassant les versions précédentes d’Opus et GPT‑5.5 à coût équivalent. Sur CursorBench, il dépasse les versions antérieures d’Opus à tous les niveaux d’effort, en utilisant moins d’appels d’outils pour la même intelligence.
C’est aussi le modèle le plus performant en utilisation informatique et en agents de navigation testé par Anthropic, avec un score de 84 % sur Online‑Mind2Web.
3. Appels d’outils plus rapides et plus efficaces
Le modèle est moins susceptible d’ignorer un appel d’outil requis par une tâche, ce qui était un point faible connu d’Opus 4.7. Les longues séquences agentiques restent également mieux concentrées après la compaction du contexte, avec moins de déraillements.
4. Raisonnement adaptatif réellement adaptatif
Avec le raisonnement adaptatif activé, Opus 4.8 décide à chaque tour si un raisonnement est nécessaire. Les requêtes simples reçoivent une réponse directe. Les problèmes complexes bénéficient d’un raisonnement avant la réponse. Moins de jetons gaspillés comparé à Opus 4.7.
Nouvelles fonctionnalités à connaître
Contrôle de l’effort — désormais sur tous les plans
Un nouveau réglage, à côté du sélecteur de modèle, permet aux utilisateurs de choisir le niveau d’effort que Claude fournit dans une réponse. Opus 4.8 utilise par défaut un effort high, avec des options extra et max pour les tâches plus difficiles. Les limites de taux dans Claude Code ont été augmentées pour gérer l’utilisation accrue de jetons.
Mode rapide — vitesse ×2,5, coût réduit
Le mode rapide est désormais disponible pour Opus 4.8 en aperçu de recherche sur l’API Claude. Il offre jusqu’à 2,5 × plus de jetons de sortie par seconde à un coût trois fois inférieur aux modèles précédents.
Messages système en cours de conversation
L’API Messages accepte désormais des entrées role: "system" à l’intérieur du tableau de messages. Vous pouvez ainsi mettre à jour les instructions de Claude au milieu d’une tâche sans interrompre le cache de l’invite — pratique lorsque les permissions ou le contexte changent durant une boucle agentique.
Seuil de cache d’invite abaissé
La longueur minimale d’une invite mise en cache est passée à 1 024 jetons. Les invites trop courtes pour être mises en cache sur Opus 4.7 créent maintenant des entrées de cache sans modification de code.
Benchmarks du monde réel
| Benchmark | Performances d’Opus 4.8 |
|---|---|
| Super‑Agent | Tous les cas terminés de bout en bout (seul modèle à le faire) |
| CursorBench | Surpasse tous les modèles Opus précédents à tous les niveaux d’effort |
| Online‑Mind2Web | 84 % (modèle le plus performant testé) |
| Legal Agent Benchmark | Score le plus élevé enregistré ; premier modèle à dépasser 10 % au total |

Opus 4.8 est le plus solide là où l’autonomie à long terme est cruciale — agents de codage, de recherche, de processus juridiques, et travaux de connaissance en entreprise.
Tarification — inchangée par rapport à Opus 4.7
| Mode | Entrée | Sortie |
|---|---|---|
| Standard | 5 $ / 1 M jetons | 25 $ / 1 M jetons |
| Rapide | 10 $ / 1 M jetons | 50 $ / 1 M jetons |
Même prix qu’Opus 4.7, avec de meilleures performances. L’identifiant du modèle sur l’API est claude-opus-4-8. Il prend en charge une fenêtre de contexte de 1 M jetons et une sortie maximale de 128 k jetons.
Et ensuite : les modèles de classe Mythos
Anthropic a également évoqué une nouvelle classe de modèles dotés d’une « intelligence encore supérieure à Opus ». Un petit nombre d’organisations utilisent déjà Claude Mythos Preview pour des travaux de cybersécurité via le projet Glasswing. L’entreprise prévoit de rendre les modèles de classe Mythos disponibles à tous les clients dans les prochaines semaines, une fois les garde‑fous en place.
Pourquoi la diversité des modèles est importante
De nouveaux modèles d’IA sortent chaque semaine. Pour les développeurs qui les utilisent, la vraie question n’est pas de savoir quel modèle est « le meilleur », mais lequel est le plus adapté à chaque tâche, et comment passer de l’un à l’autre sans friction.
C’est justement le défi que Felo AI relève. Au‑delà de sa recherche alimentée par l’IA qui s’appuie sur des modèles avancés pour fournir des réponses en temps réel, Felo propose un LLM Playground permettant d’appeler, tester et comparer les résultats d’une large gamme de modèles de pointe en un seul endroit. Pas de jonglage entre les clés API, pas de basculement entre tableaux de bord. Il suffit de choisir un modèle, d’exécuter votre invite et d’observer les résultats.
Si vous évaluez des modèles pour votre flux de travail, ou si vous êtes simplement curieux de découvrir ce qui existe, les avoir tous dans une seule interface rend la comparaison beaucoup plus agréable.
Essayez Felo AI gratuitement → https://felo.ai
Cet article est également disponible en English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, العربية, Русский, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Türkçe, Italiano, ไทย, Español, বাংলা and Português.