Réalisations révolutionnaires de Felo AI : Taux de précision de 91,2 % au test de référence SimpleQA, établissant une nouvelle norme pour la recherche AI.

Felo AI a réalisé des avancées révolutionnaires dans le test de référence SimpleQA, avec un taux de précision de 91,2 %, menant le domaine de la recherche AI. Découvrez comment des technologies innovantes telles que la reformulation de requêtes interlangues améliorent l'expérience de recherche.
Révolutionner les moteurs de recherche AI avec une précision inégalée
Nous sommes ravis d'annoncer que Felo a récemment surpassé tous ses concurrents dans le benchmark SimpleQA. SimpleQA est un test clé développé par OpenAI pour évaluer l'exactitude factuelle dans les réponses AI. Avec un impressionnant 91,2% de précision, Felo Pro (mode rapide) établit une nouvelle référence pour les moteurs de recherche AI, dépassant de manière significative des concurrents tels que Perplexity et Gemini.
Benchmark SimpleQA : La pierre de touche des moteurs de recherche AI
SimpleQA est un benchmark développé par OpenAI, conçu pour mesurer l'efficacité des systèmes AI à répondre à des questions factuelles concises en utilisant des données du web. Contrairement aux indicateurs de recherche traditionnels, SimpleQA se concentre sur la réduction des problèmes d'illusion dans les systèmes AI en mettant l'accent sur la précision et la fiabilité des faits - un défi de longue date dans le domaine de l'AI. La performance exceptionnelle de Felo dans ce benchmark démontre notre engagement à fournir des solutions de pointe pour les moteurs de recherche AI.
Méthodologie de test : Un cadre d'évaluation rigoureux
Felo a utilisé un cadre standardisé pour évaluer le benchmark SimpleQA afin d'assurer équité et transparence. La méthode comprend les étapes suivantes :
- Questions : Soumettre directement les questions du jeu de données SimpleQA à Felo.
- Génération de réponses : Utiliser Felo Pro (mode rapide) pour générer des réponses.
Tous les tests ont été effectués avec le même ensemble de questions et critères d'évaluation, définis dans le protocole original de SimpleQA, garantissant une comparaison équitable entre tous les participants.
Résultats des tests : Felo atteint un taux de précision de leader de l'industrie
Les résultats du benchmark SimpleQA mettent en évidence la position de leader de Felo dans le domaine de la recherche intelligente AI :
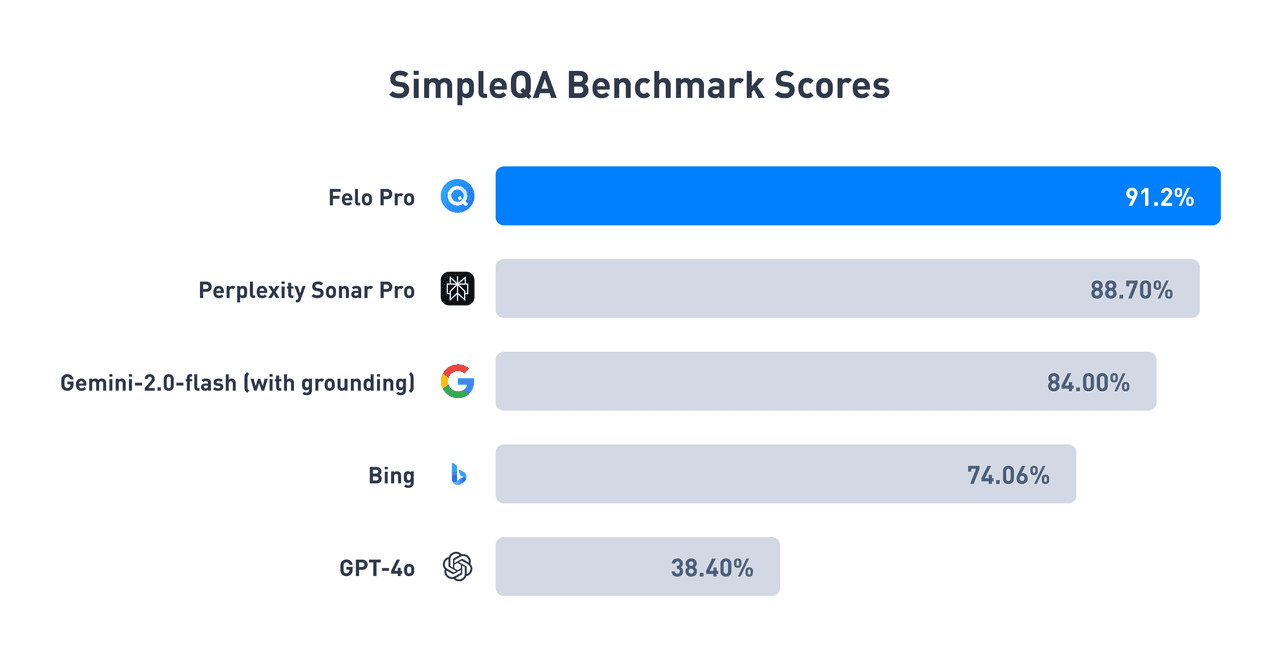
Nous avons rendu publics les résultats des tests de Felo, vous pouvez consulter ici pour plus de détails.
Qu'est-ce qui rend Felo unique ?
Felo doit sa performance exceptionnelle dans le benchmark SimpleQA à son architecture et son design innovants, avec des différences clés comprenant :
- Réécriture de requêtes multilingues avancée Felo est capable de décomposer intelligemment les requêtes originales en sous-requêtes plus granulaires, choisissant même le contexte linguistique le plus approprié pour la recherche en fonction des questions des utilisateurs, ces sous-requêtes étant optimisées pour la recherche dans les moteurs de recherche traditionnels et les systèmes RAG. Cela permet à Felo d'accéder à un plus grand nombre de pages web pertinentes.
- Technologie d'indexation hybride Felo utilise une technologie de recherche hybride basée sur des mots-clés et sémantique, en appliquant une compression sémantique consciente des modèles au contenu des pages web, permettant à Felo de conserver la densité factuelle clé tout en éliminant le bruit non pertinent. Cela garantit que le LLM (modèle de langage large) ne reçoit que les informations les plus pertinentes et de haute qualité.
- Formation axée sur la recherche Contrairement aux moteurs de recherche généraux, Felo a affiné ses modèles de classement spécifiquement pour la manière unique dont les modèles de langage large traitent l'information, développant 7 LLM en interne pour fournir des résultats de recherche plus précis et contextuels.