Felo Web Fetch pour Google Antigravity : Extraire les informations produit et web sous forme de données structurées

Découvrez comment la compétence Felo Web Fetch donne aux agents Google Antigravity la capacité d’extraire des pages web en Markdown, HTML ou texte propre pour la recherche produit, l’analyse concurrentielle et la collecte de données structurées.
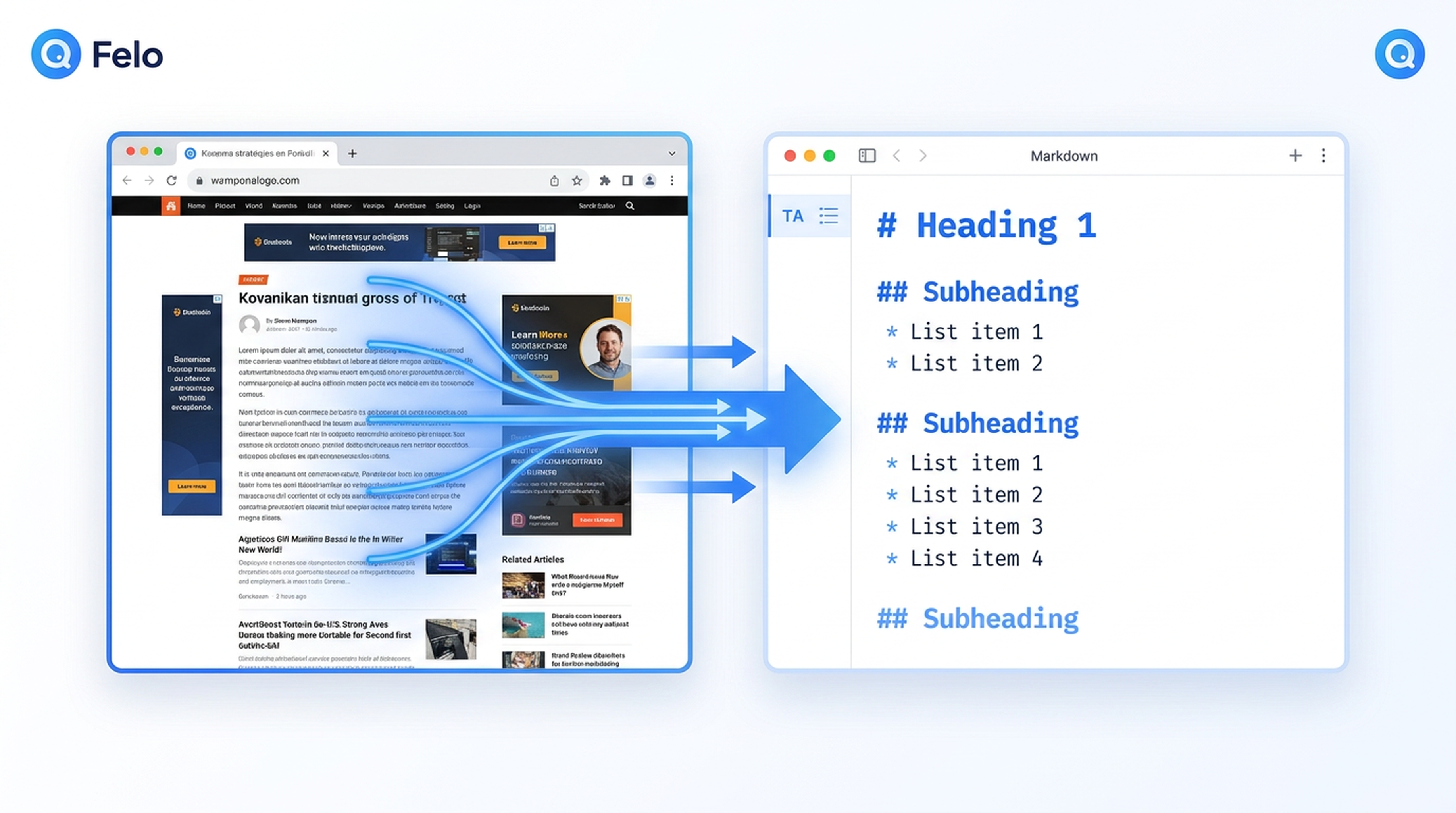
Le premier obstacle rencontré par les agents Antigravity
Vous confiez à votre agent Google Antigravity une tâche de recherche. Peut-être qu’il s’agit de comparer les tarifs SaaS, de récupérer les listes de fonctionnalités des concurrents ou de rassembler des sources pour un compte rendu. L’agent planifie bien. Il sait ce dont il a besoin. Mais il se heurte à un mur : les données d’entraînement de Gemini 3 ont une date de coupure, et l’agent ne peut pas accéder au web en direct par lui-même.
C’est là qu’interviennent les Felo Skills. En particulier, la compétence Felo Web Fetch comble ce vide d’extraction — transformant n’importe quelle page web en Markdown, HTML ou texte brut propre et structuré que votre agent Antigravity peut réellement exploiter.
Qu’est-ce que Felo Web Fetch ?
Felo Web Fetch est une compétence basée sur des dossiers que vous déposez dans le répertoire .agent/skills/ de votre Google Antigravity. Une fois installée, elle devient une capacité déclenchée de manière autonome — votre agent n’a pas besoin que vous tapiez une commande ou que vous copiez des URL. Lorsqu’une tâche nécessite la lecture d’une page web, le gestionnaire d’agents associe la tâche à la description de la compétence et l’exécute automatiquement.
La compétence utilise l’API Felo Web Extract (POST /v2/web/extract) pour récupérer le contenu de n’importe quelle URL et le renvoyer dans le format requis par votre flux de travail :
| Format de sortie | Quand l’utiliser |
|---|---|
| Markdown | Idéal pour la consommation par IA — structure propre avec titres, listes et liens conservés |
| HTML | Lorsque vous avez besoin de la structure DOM brute pour un traitement ultérieur |
| Text | Extraction de texte brut, utile pour un balayage rapide ou un traitement textuel en aval |
Installez-la depuis felo.ai/skills/antigravity — copiez simplement le dossier dans
.agent/skills/et validez dans Git. Chaque développeur de votre équipe disposera de la capacité à la prochaine synchronisation.
Fonctionnement à l’intérieur d’Antigravity
Le chemin d'installation est volontairement simple :
# Cloner le dépôt des compétences Felo
git clone https://github.com/Felo-Inc/felo-skills.git
# Copier la compétence web-fetch dans le dossier des compétences Antigravity
cp -r felo-skills/felo-web-fetch ~/.gemini/antigravity/skills/
Une fois le dossier felo-web-fetch placé dans .agent/skills/, le fichier SKILL.md fait tout le travail de fond. Son champ de description agit comme un déclencheur sémantique. Lorsque votre agent rencontre une tâche du type « comparer les tarifs de ces trois produits SaaS » ou « extraire la liste des fonctionnalités de cette page concurrente », le gestionnaire d’agents charge la compétence automatiquement — sans nécessité d’invocation manuelle.
Capacités principales
1. Mode lisibilité pour une extraction d’articles propre
Toutes les pages web ne sont pas bien structurées. Les blogs, articles d’actualité et pages de documentation comportent souvent des barres de navigation, des encadrés latéraux, des pieds de page et du bruit publicitaire. Felo Web Fetch prend en charge un mode lisibilité (--with-readability true) qui n’extrait que le contenu principal de l’article, en supprimant tout le reste.
C’est particulièrement utile pour les agents Antigravity en phase de recherche : au lieu d’analyser 200 Ko de bruit de page, l’agent reçoit un corps d’article clair et ciblé — exactement le contenu nécessaire à son analyse.
2. Ciblage par sélecteur CSS pour une extraction précise
Parfois, vous ne souhaitez pas la page entière. Vous voulez le tableau de prix dans .pricing-section, ou le journal des modifications dans div.changelog. Felo Web Fetch accepte un paramètre --target-selector, vous permettant d’extraire uniquement l’élément DOM qui vous intéresse.
Pour les flux de travail d’intelligence concurrentielle, cela signifie que votre agent peut récupérer des données de tarification structurées, des tableaux de comparaison de fonctionnalités ou des fiches produits sans avoir à filtrer le contenu non pertinent.
3. Modes de crawl : Rapide vs Précis
| Mode | Idéal pour |
|---|---|
fast | Pages statiques, documentation, articles de blog — celles qui se chargent immédiatement |
fine | Pages riches en JavaScript, applications monopage, ou nécessitant un rendu dynamique |
Le mode par défaut du gestionnaire d’agents est fast, pour l’efficacité. Pour extraire un contenu sur une page produit basée sur React ou un tableau de bord derrière une authentification, on passera à fine pour garantir que tout le contenu est chargé avant l’extraction.
4. Prise en charge des cookies et de l’authentification
Pour les pages derrière un login, Felo Web Fetch prend en charge la transmission de cookies (--cookie "session_id=xxx") et d’agents utilisateurs personnalisés. Cela permet à votre agent Antigravity d’extraire du contenu depuis des tableaux de bord authentifiés, des portails internes de documentation ou des pages partenaires — élargissant ainsi la gamme de sources accessibles au-delà des simples URL publiques.
5. Résumés structurés : liens et images
Au-delà du contenu brut, la compétence peut inclure :
--with-links-summary true— tous les liens extraits et résumés--with-images-summary true— toutes les images extraites avec métadonnées--with-images-readability true— images associées à leur contexte environnant
Pour un agent de recherche compilant une vue d’ensemble produit, ces résumés deviennent des points de données structurés — des liens pour le suivi, des URL d’images pour la comparaison visuelle et des métadonnées contextuelles enrichissant le livrable final.
Cas d’usage concrets
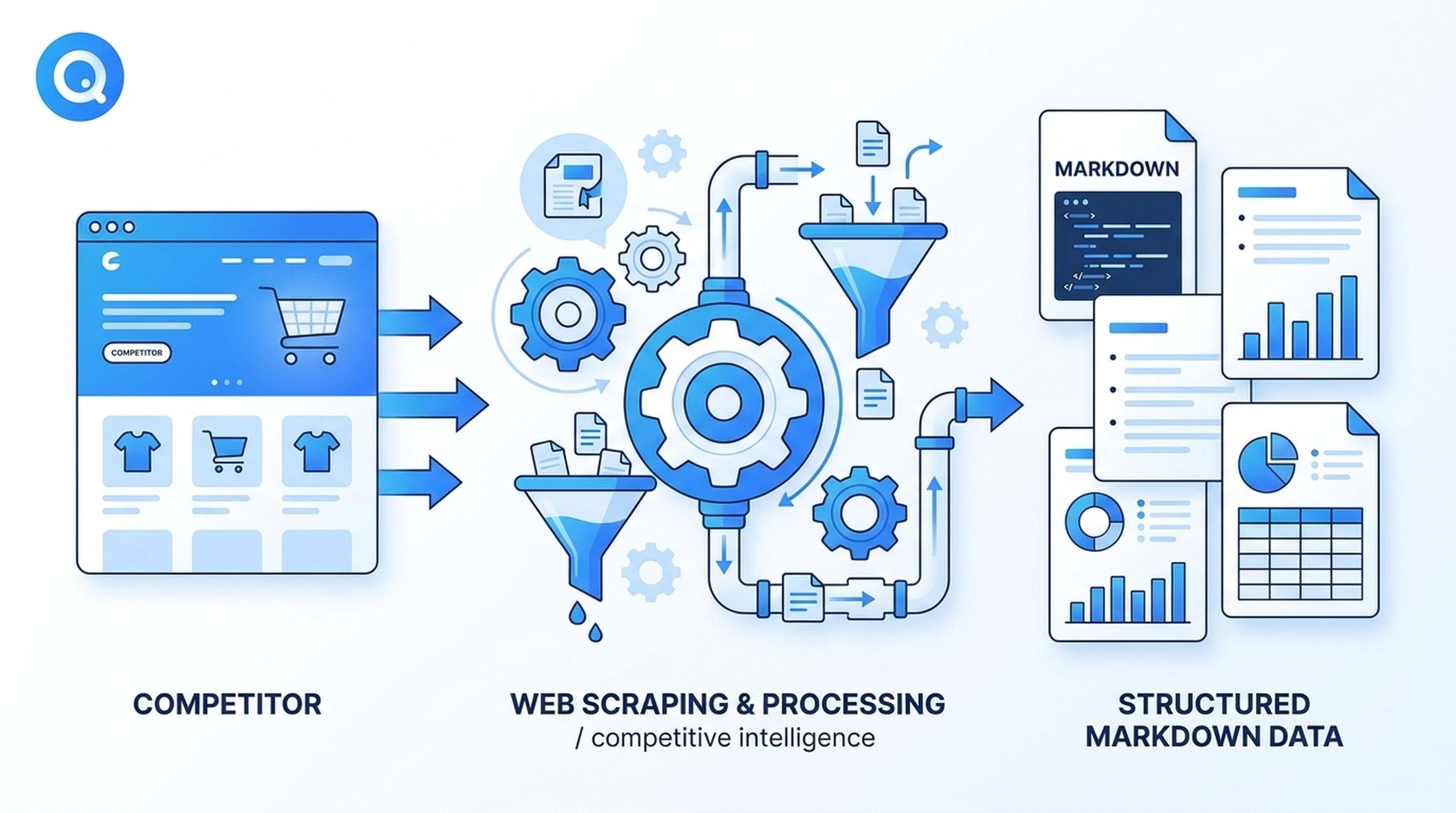
Intelligence concurrentielle à grande échelle
Imaginez que votre agent Antigravity doive surveiller chaque semaine les pages produits de trois concurrents. Avec Felo Web Fetch installé, l’agent :
- Visite automatiquement chaque page de tarification concurrente
- Extrait le contenu en Markdown propre
- Compare les fonctionnalités, gammes de prix et nouveautés par rapport à votre référence
- Signale toute modification depuis la dernière extraction
L’agent n’a pas besoin que vous récupériez les pages à la main. La compétence se déclenche lorsque la tâche correspond, extrait les données et les renvoie dans le pipeline de raisonnement de l’agent.
Recherche produit et décisions d’achat
Lorsqu’une tâche d’agent implique d’évaluer des outils, services ou plateformes, Felo Web Fetch lui donne accès à des pages produits actuelles — et non à des données d’entraînement obsolètes. L’agent extrait spécifications, tarifs, listes d’intégrations et témoignages clients directement à la source, produisant des rapports d’achat fondés sur des informations réelles et à jour.
Sources pour la création de contenu
Les équipes de contenu utilisent Antigravity pour rédiger des notes, analyses de marché et rapports de recherche. Felo Web Fetch alimente l’agent avec des sources fiables extraites des pages originales — garantissant que les productions de l’agent reposent sur des sources primaires plutôt que sur des approximations.
Détection de modifications dans la documentation et les API
Pour les équipes d’ingénierie, il est essentiel de détecter les évolutions dans la documentation API, les SDK ou les portails développeurs. Felo Web Fetch peut extraire ces pages de documentation en Markdown, que l’agent compare ensuite aux versions précédentes pour identifier les ruptures, nouveaux points d’entrée ou fonctionnalités obsolètes.
Référence API pour les développeurs
Si vous intégrez Felo Web Fetch de manière programmée (en dehors d’Antigravity), l’API est simple :
curl -X POST "https://openapi.felo.ai/v2/web/extract" \
-H "Authorization: Bearer $FELO_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"url": "https://example.com/product",
"output_format": "markdown",
"with_readability": true,
"crawl_mode": "fast"
}'
Paramètres principaux de la requête :
| Paramètre | Type | Par défaut | Description |
|---|---|---|---|
url | string | — | URL de la page à extraire |
output_format | string | html | html, markdown ou text |
crawl_mode | string | fast | fast ou fine |
with_readability | boolean | — | N’extraire que le contenu principal |
target_selector | string | — | Sélecteur CSS pour des éléments spécifiques |
wait_for_selector | string | — | Attendre un élément avant extraction |
timeout | integer | — | Délai d’attente en millisecondes |
set_cookies | array | — | Cookies pour pages authentifiées |
Une réponse réussie renvoie le contenu extrait dans data.content, structuré selon votre output_format choisi.
Pourquoi c’est important pour les équipes Antigravity
La valeur de Felo Web Fetch ne réside pas seulement dans l’extraction elle-même — mais dans ce qu’elle rend possible dans les flux de travail de vos agents Antigravity :
1. Les agents travaillent avec des données actuelles, pas des connaissances en cache. Gemini 3 ne peut pas naviguer sur le web. Felo Web Fetch comble ce fossé, donnant aux agents accès au contenu réel de toute URL au moment de l’extraction.
2. Une sortie structurée signifie un raisonnement structuré. Lorsque le contenu est livré en Markdown propre, l’agent peut analyser titres, listes, tableaux et blocs de code — produisant une analyse fondée sur la structure réelle des pages.
3. Zéro dérive de configuration. Comme la compétence réside dans .agent/skills/ et est versionnée dans Git, chaque développeur de votre équipe bénéficie de la même capacité. Pas de configuration par utilisateur, ni de bricolage spécifique à l’environnement.
4. Elle fonctionne avec d’autres Felo Skills. Associez Felo Web Fetch à Felo Search pour la vérification de recherche en direct, ou à Felo Slides pour transformer le contenu extrait en présentations prêtes à l’emploi. Le gestionnaire d’agents orchestre automatiquement la passation entre les compétences.
Mise en route
Intégrer Felo Web Fetch dans votre flux Antigravity prend quelques minutes :
- Visitez felo.ai et créez une clé API (Paramètres → Clés API)
- Définissez la variable d’environnement :
export FELO_API_KEY="your-api-key-here" - Copiez le dossier de la compétence dans votre répertoire
.agent/skills/ - Validez dans Git pour que les agents de votre équipe la récupèrent automatiquement
Et c’est tout. Votre prochaine tâche d’agent impliquant la lecture d’une page web déclenchera automatiquement Felo Web Fetch — sans intervention manuelle ni changement de contexte.
Une vision plus large
Felo Web Fetch fait partie d’un écosystème plus vaste de Felo Skills pour Google Antigravity. Ensemble, ces compétences transforment le gestionnaire d’agents Antigravity, le faisant passer d’un simple planificateur à un véritable outil de recherche et de production — comblant les lacunes de connaissance, maintenant la mémoire d’équipe, et livrant des résultats finalisés.
La couche d’extraction que fournit Felo Web Fetch est souvent la première compétence installée par les équipes, car elle résout le problème le plus immédiat : votre agent doit lire le web, et Gemini 3 ne peut pas le faire seul. Une fois l’extraction maîtrisée, l’ajout de la recherche en direct, des bases de connaissances persistantes et de la génération de livrables devient une évolution naturelle.
Prêt à donner à vos agents Antigravity la capacité d’extraire, d’analyser et d’agir sur du contenu web réel ? Commencez avec Felo Web Fetch — c’est gratuit, basé sur des dossiers et prêt pour les équipes dès l’installation.
Cet article est également disponible en English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, العربية, Русский, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Türkçe, Italiano, ไทย, Español, বাংলা and Português.