Comment utiliser les modèles de raisonnement OpenAI : modèles o1-preview/o1-Mini - Chat AI gratuit

Le chat Felo AI prend désormais en charge l'utilisation gratuite du modèle de raisonnement O1
Dans le paysage en évolution rapide de l'intelligence artificielle, OpenAI a introduit une série révolutionnaire de grands modèles de langage connus sous le nom de série o1. Ces modèles sont conçus pour effectuer des tâches de raisonnement complexes, ce qui en fait un outil puissant pour les développeurs et les chercheurs. Dans cet article de blog, nous allons explorer comment utiliser efficacement les modèles de raisonnement d'OpenAI, en nous concentrant sur leurs capacités, leurs limites et les meilleures pratiques pour leur mise en œuvre.


Comprendre les modèles de la série OpenAI o1
Les modèles de la série o1 se distinguent des itérations précédentes des modèles de langage d'OpenAI en raison de leur méthodologie d'entraînement unique. Ils utilisent l'apprentissage par renforcement pour améliorer leurs capacités de raisonnement, leur permettant de réfléchir de manière critique avant de générer des réponses. Ce processus de pensée interne permet aux modèles de produire une longue chaîne de raisonnement, ce qui est particulièrement bénéfique pour aborder des problèmes complexes.
Caractéristiques clés des modèles OpenAI o1
1. **Raisonnement avancé** : Les modèles o1 excellent dans le raisonnement scientifique, obtenant des résultats impressionnants dans la programmation compétitive et les benchmarks académiques. Par exemple, ils se classent au 89e percentile sur Codeforces et ont démontré une précision de niveau doctorat dans des matières comme la physique, la biologie et la chimie.
2. **Deux variantes** : OpenAI propose deux versions des modèles o1 via leur API :
- **o1-preview** : Il s'agit d'une version précoce conçue pour aborder des problèmes difficiles en utilisant des connaissances générales larges.
- **o1-mini** : Une variante plus rapide et plus économique, particulièrement adaptée aux tâches de codage, de mathématiques et de sciences qui ne nécessitent pas de connaissances générales étendues.
3. **Fenêtre de contexte** : Les modèles o1 disposent d'une fenêtre de contexte substantielle de 128 000 tokens, permettant une entrée et un raisonnement étendus. Cependant, il est crucial de gérer ce contexte efficacement pour éviter d'atteindre les limites de tokens.
Commencer avec les modèles OpenAI o1
Pour commencer à utiliser les modèles o1, les développeurs peuvent y accéder via le point de terminaison des complétions de chat de l'API OpenAI.
Êtes-vous prêt à élever votre expérience d'interaction avec l'IA ? Felo AI Chat offre désormais la possibilité d'explorer le modèle de raisonnement O1 à coût nul !
Essayez gratuitement le modèle de raisonnement o1.
Limitations bêta des modèles OpenAI o1
Il est important de noter que les modèles o1 sont actuellement en version bêta, ce qui signifie qu'il y a certaines limitations à prendre en compte :
Au cours de la phase bêta, de nombreux paramètres de l'API de complétion de chat ne sont pas encore disponibles. Plus particulièrement :
- Modalités : texte uniquement, les images ne sont pas prises en charge.
- Types de messages : messages utilisateur et assistant uniquement, les messages système ne sont pas pris en charge.
- Streaming : non pris en charge.
- Outils : outils, appels de fonction et paramètres de format de réponse ne sont pas pris en charge.
- Logprobs : non pris en charge.
- Autre :
temperature,top_petnsont fixés à1, tandis quepresence_penaltyetfrequency_penaltysont fixés à0. - Assistants et Batch : ces modèles ne sont pas pris en charge dans l'API Assistants ou l'API Batch.
**Gestion de la fenêtre de contexte** :
Avec une fenêtre de contexte de 128 000 tokens, il est essentiel de gérer l'espace efficacement. Chaque complétion a une limite maximale de tokens de sortie, qui inclut à la fois les tokens de raisonnement et les tokens de complétion visibles. Par exemple :
- **o1-preview** : Jusqu'à 32 768 tokens
- **o1-mini** : Jusqu'à 65 536 tokens
Vitesse des modèles OpenAI o1
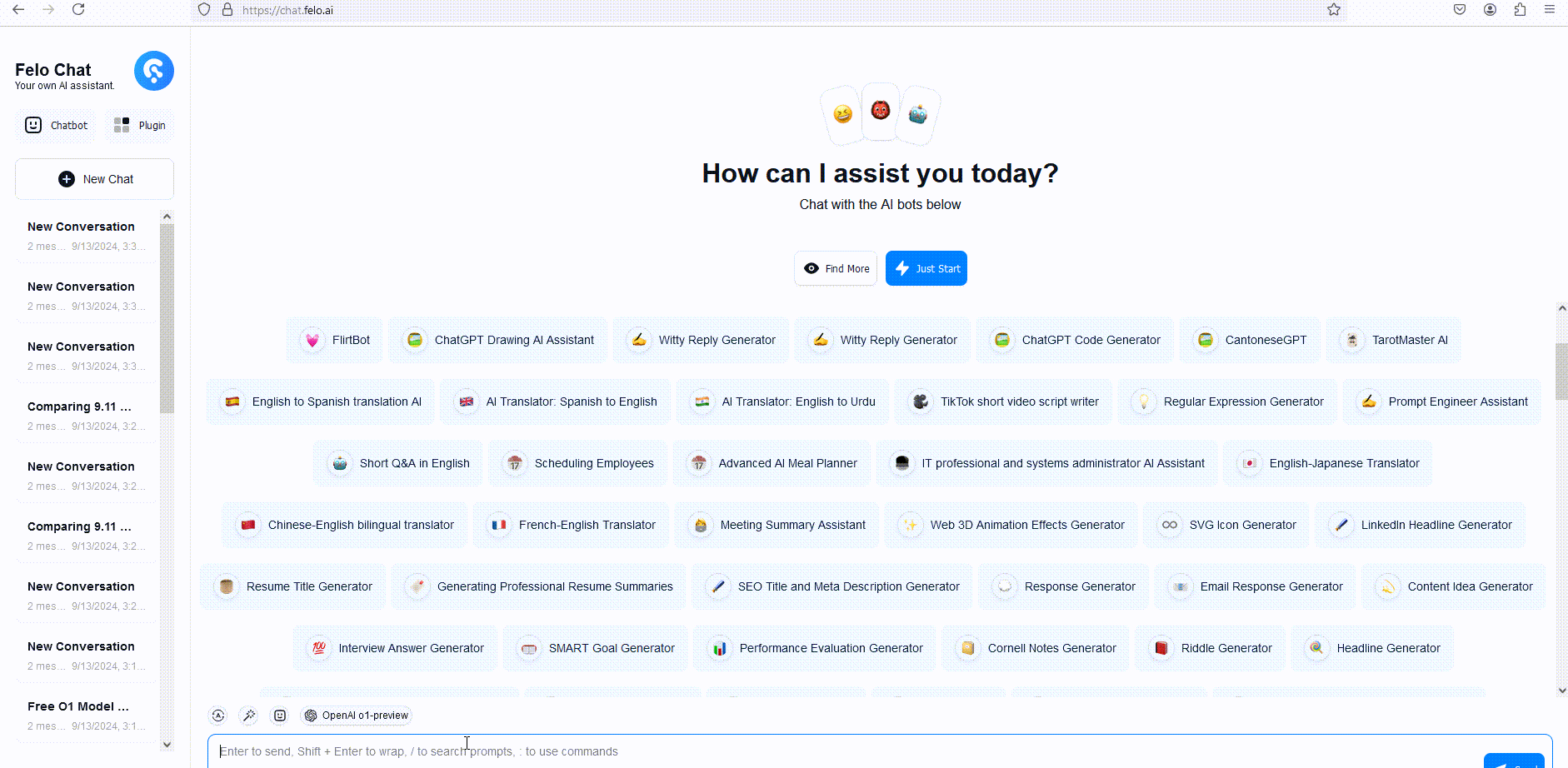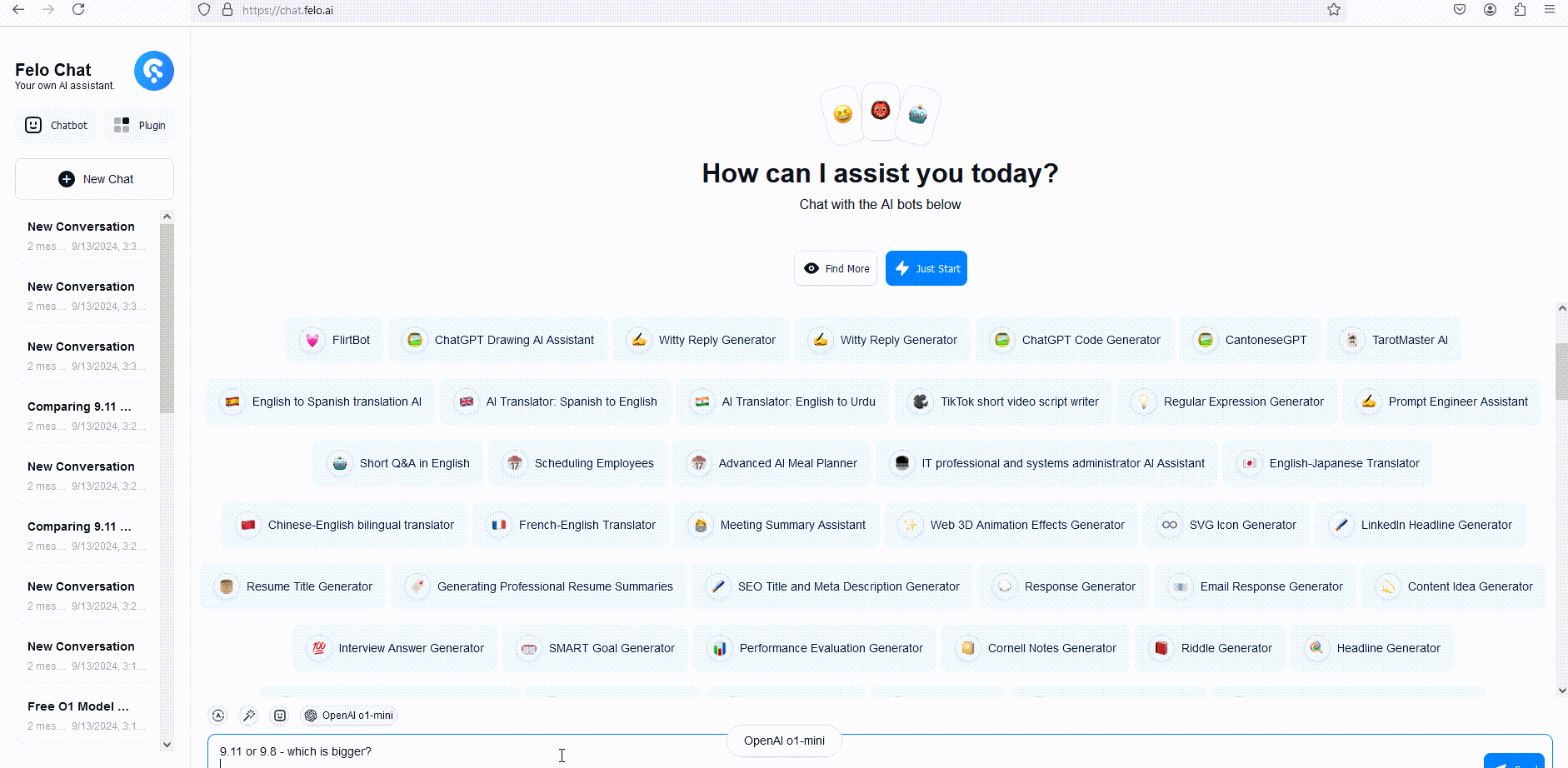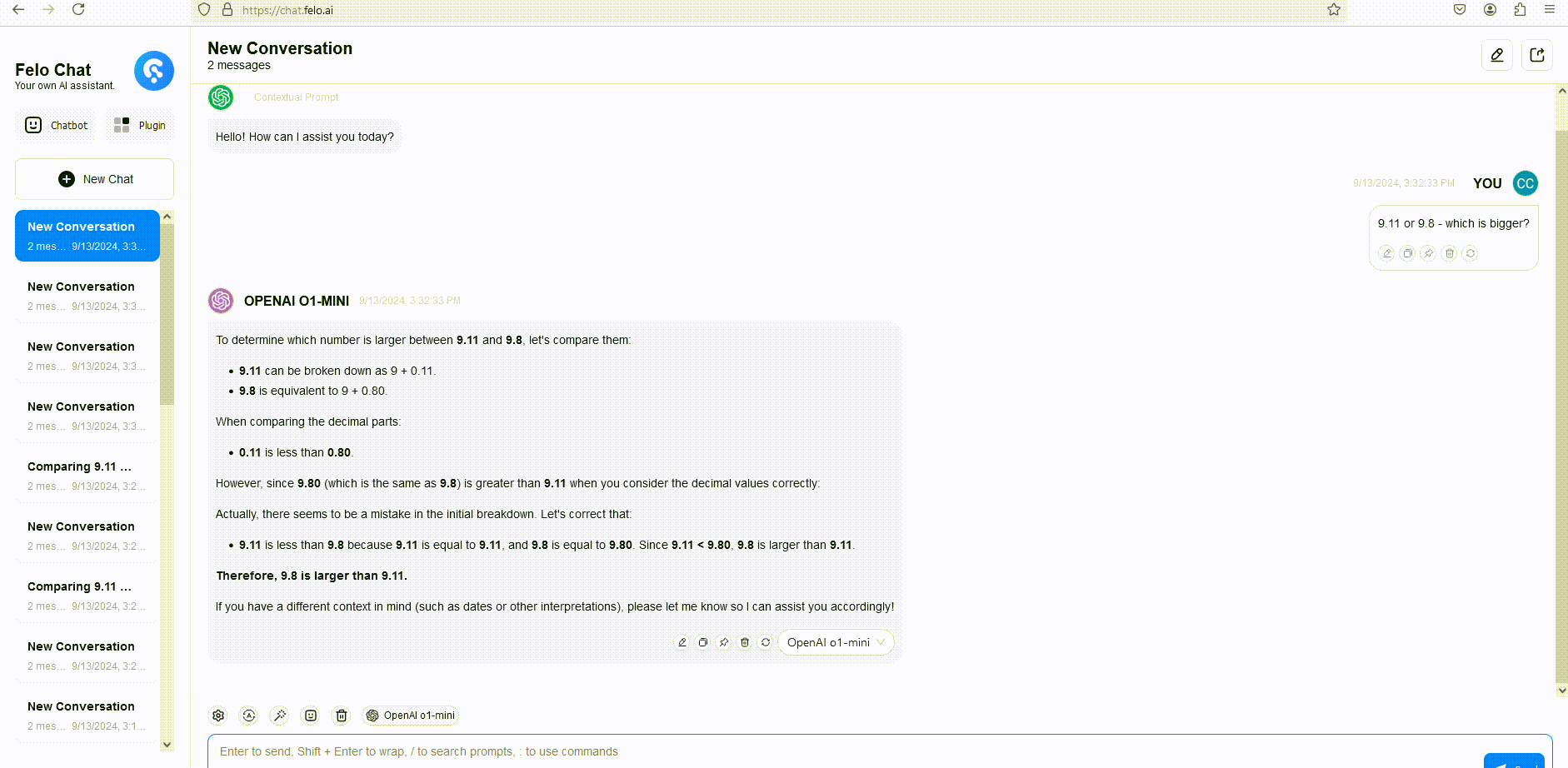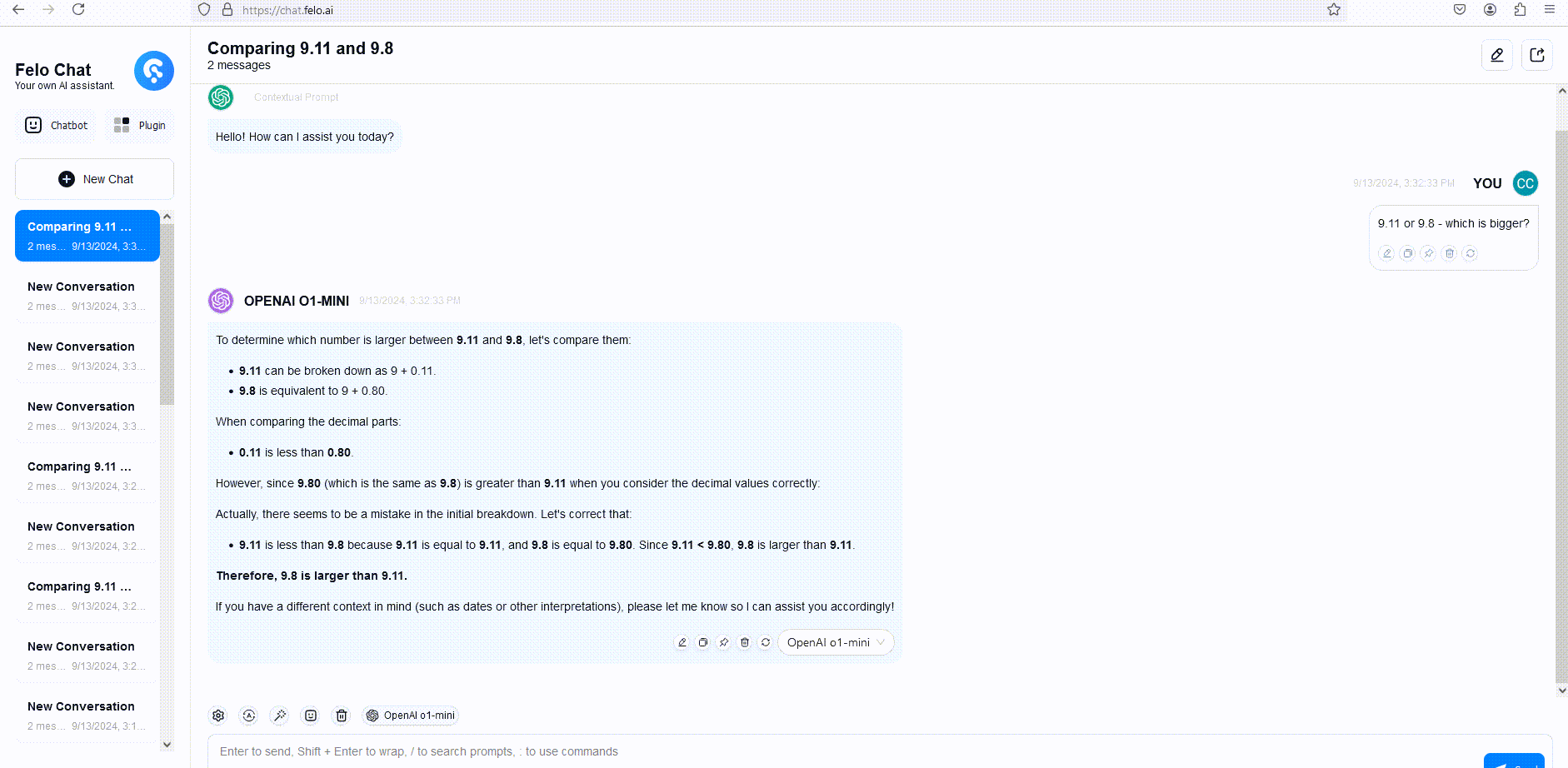
Pour illustrer, nous avons comparé les réponses de GPT-4o, o1-mini et o1-preview à une question de raisonnement verbal. Bien que GPT-4o ait fourni une réponse incorrecte, les deux o1-mini et o1-preview ont répondu correctement, avec o1-mini atteignant la bonne réponse environ 3 à 5 fois plus rapidement.

Comment choisir entre les modèles GPT-4o, O1 Mini et O1 Preview ?
**O1 Preview** : Il s'agit d'une version précoce du modèle OpenAI O1, conçue pour tirer parti d'une vaste connaissance générale pour raisonner à travers des problèmes complexes.
**O1 Mini** : Une version plus rapide et plus abordable de O1, particulièrement efficace pour les tâches de codage, de mathématiques et de sciences, idéale pour les situations qui ne nécessitent pas de connaissances générales étendues.
Les modèles O1 offrent des améliorations significatives en matière de raisonnement mais ne sont pas destinés à remplacer GPT-4o dans tous les cas d'utilisation.
Pour les applications nécessitant une entrée d'image, des appels de fonction ou des temps de réponse rapides et constants, les modèles GPT-4o et GPT-4o Mini restent les meilleurs choix. Cependant, si vous développez des applications qui nécessitent un raisonnement approfondi et peuvent accepter des temps de réponse plus longs, les modèles O1 pourraient être un excellent choix.
Conseils pour une incitation efficace des modèles O1 Mini et O1 Preview
Les modèles OpenAI o1 fonctionnent mieux avec des incitations claires et simples. Certaines techniques, telles que l'incitation par quelques exemples ou demander au modèle de "penser étape par étape", pourraient ne pas améliorer les performances et peuvent même les entraver. Voici quelques meilleures pratiques à suivre :
1. **Gardez les incitations simples et directes** : Les modèles sont les plus efficaces lorsqu'ils reçoivent des instructions brèves et claires sans nécessiter d'élaboration extensive.
2. **Évitez les incitations de chaîne de pensée** : Étant donné que ces modèles gèrent le raisonnement en interne, il n'est pas nécessaire de les inciter à "penser étape par étape" ou "expliquer votre raisonnement".
3. **Utilisez des délimiteurs pour plus de clarté** : Utilisez des délimiteurs comme des guillemets triples, des balises XML ou des titres de section pour définir clairement différentes parties de l'entrée, ce qui aide le modèle à interpréter chaque section correctement.
4. **Limitez le contexte supplémentaire dans la génération augmentée par récupération (RAG)** : Lorsque vous fournissez un contexte ou des documents supplémentaires, incluez uniquement les informations les plus pertinentes pour éviter de compliquer la réponse du modèle.
Prix des modèles o1 Mini et 1 Preview.
Le calcul des coûts pour les modèles o1 Mini et 1 Preview est différent des autres modèles, car il inclut un coût supplémentaire pour les tokens de raisonnement.
Tarification o1-mini
3,00 $ / 1M tokens d'entrée
12,00 $ / 1M tokens de sortie
Tarification o1-preview
15,00 $ / 1M tokens d'entrée
60,00 $ / 1M tokens de sortie
Gestion des coûts des modèles o1-preview/o1-mini
Pour contrôler les dépenses avec les modèles de la série o1, vous pouvez utiliser le paramètre `max_completion_tokens` pour définir une limite sur le nombre total de tokens que le modèle génère, englobant à la fois les tokens de raisonnement et les tokens de complétion.
Dans les modèles précédents, le paramètre `max_tokens` gérait à la fois le nombre de tokens générés et le nombre de tokens visibles pour l'utilisateur, qui étaient toujours les mêmes. Cependant, avec la série o1, le nombre total de tokens générés peut dépasser le nombre de tokens affichés à l'utilisateur en raison des tokens de raisonnement internes.
Étant donné que certaines applications dépendent de la correspondance de `max_tokens` avec le nombre de tokens reçus de l'API, la série o1 introduit `max_completion_tokens` pour contrôler spécifiquement le nombre total de tokens produits par le modèle, y compris à la fois les tokens de raisonnement et les tokens de complétion visibles. Cette option explicite garantit que les applications existantes restent compatibles avec les nouveaux modèles. Le paramètre `max_tokens` continue de fonctionner comme il l'a fait pour tous les modèles précédents.
Conclusion
Les modèles de la série o1 d'OpenAI représentent une avancée significative dans le domaine de l'intelligence artificielle, en particulier dans leur capacité à effectuer des tâches de raisonnement complexes. En comprenant leurs capacités, leurs limites et les meilleures pratiques d'utilisation, les développeurs peuvent exploiter la puissance de ces modèles pour créer des applications innovantes. Alors qu'OpenAI continue de peaufiner et d'élargir la série o1, nous pouvons nous attendre à des développements encore plus passionnants dans le domaine du raisonnement piloté par l'IA. Que vous soyez un développeur chevronné ou que vous débutiez, les modèles o1 offrent une opportunité unique d'explorer l'avenir des systèmes intelligents. Bon codage !
Felo AI Chat vous offre toujours une expérience gratuite avec des modèles d'IA avancés du monde entier. Cliquez ici pour l'essayer!