Claude Opus 4.8 जारी: अब तक का Anthropic का सबसे सक्षम मॉडल

Anthropic ने अभी Claude Opus 4.8 जारी किया है — यह तेज़, अधिक ईमानदार, और एजेंटिक कार्यों में बेहतर है। यहाँ सब कुछ नया और यह डेवलपर्स के लिए क्यों महत्वपूर्ण है।

इस सप्ताह Claude Opus 4.8 जारी हुआ। यह अब तक का सबसे सक्षम मॉडल है जिसे Anthropic ने सार्वजनिक किया है — इसमें कोडिंग, तर्क, एजेंटिक कार्य, और ईमानदारी में सुधार किए गए हैं। कीमत वही बनी हुई है: प्रति मिलियन इनपुट टोकन $5, और प्रति मिलियन आउटपुट टोकन $25।
यहाँ देखें कि क्या बदला है और डेवलपर्स के लिए क्या मायने रखता है।
Opus 4.7 के बाद क्या बदला?
यहाँ देखें असली बदलाव:
1. बेहतर निर्णय क्षमता और ईमानदारी
Opus 4.8 बिना सबूत वाले दावे करने या ख़राब कोड को न पहचान पाने की संभावना को काफी कम करता है। Anthropic के मूल्यांकन के अनुसार, यह अपने पूर्व मॉडल की तुलना में लगभग चार गुना कम संभावना रखता है कि अपने कोड में बग होने पर उसे बिना चिन्हित किए छोड़ दे। जब आप एक मॉडल पर स्वतंत्र रूप से काम करने का भरोसा करते हैं, तो यह सुधार बहुत मायने रखता है।
प्रारंभिक परीक्षकों ने रिपोर्ट किया कि यह सही सवाल पूछता है, अपनी गलतियाँ पकड़ता है, और जब किसी योजना में तर्क नहीं होता तो उसे चुनौती देता है।
2. अधिक मजबूत एजेंटिक प्रदर्शन
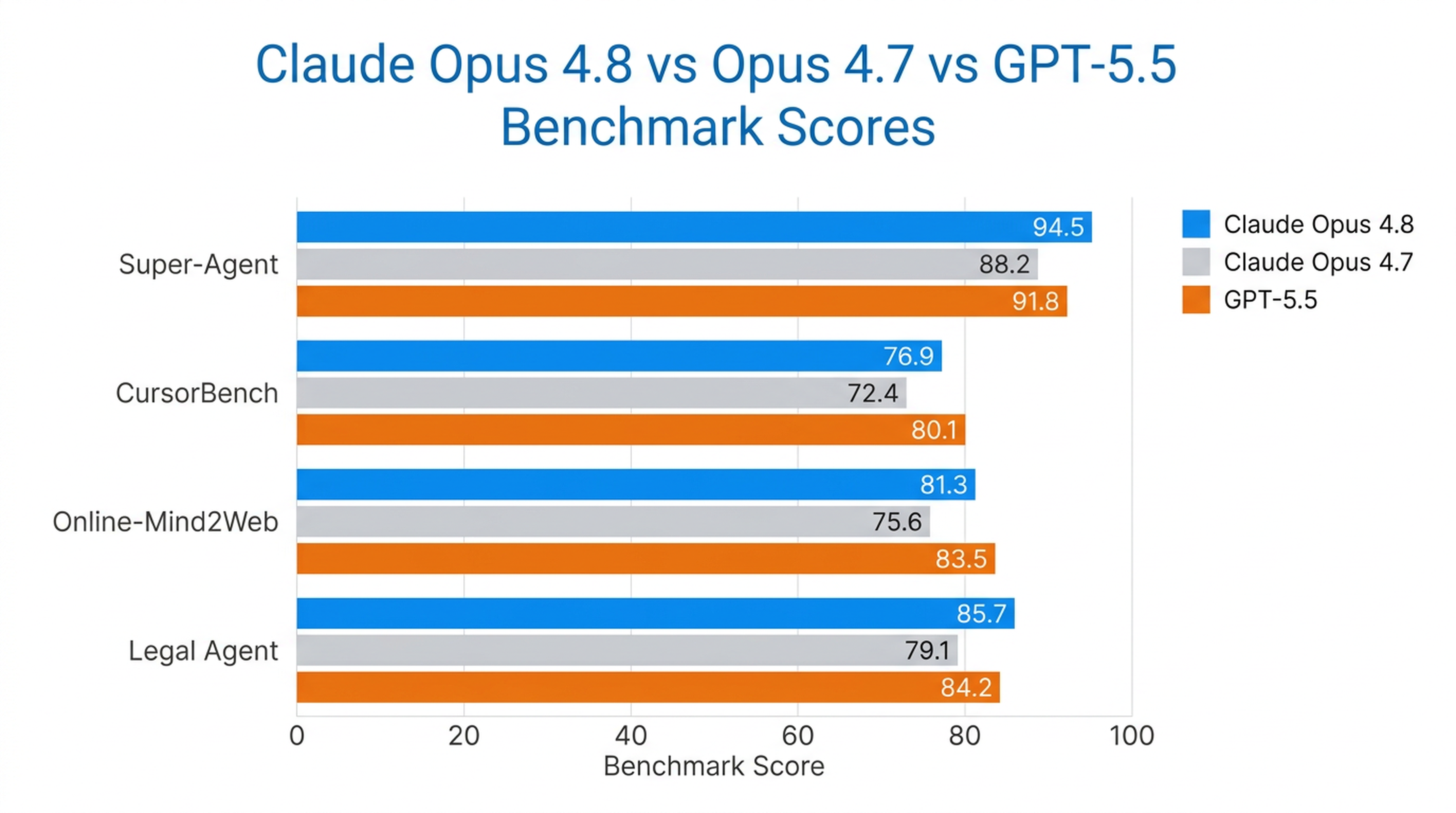
Opus 4.8 Anthropic के Super-Agent बेंचमार्क में हर केस को शुरू से अंत तक पूरा करने वाला एकमात्र मॉडल है — और यह पिछले Opus मॉडलों तथा GPT-5.5 को समान लागत पर मात देता है। CursorBench पर, यह हर स्तर पर पिछली Opus संस्करणों से बेहतर प्रदर्शन करता है, समान बुद्धिमत्ता के लिए कम टूल-कॉलिंग चरणों का उपयोग करते हुए।
यह Anthropic द्वारा परीक्षण किए गए सबसे शक्तिशाली कंप्यूटर-यूज़ और ब्राउज़र-एजेंट मॉडल में से एक है — Online-Mind2Web पर 84% स्कोर के साथ।
3. तेज़ और अधिक कुशल टूल-कॉलिंग
यह मॉडल अब ऐसे टूल कॉल को छोड़ने की संभावना कम रखता है जो कार्य के लिए आवश्यक हैं — जो Opus 4.7 में एक ज्ञात समस्या थी। लंबे एजेंटिक ट्रेस अब संदर्भ संपीड़न के बाद भी कार्य पर केंद्रित रहते हैं, कम विचलन के साथ।
4. अनुकूलनशील सोच जो वास्तव में अनुकूलित होती है
अनुकूलनशील सोच सक्षम होने पर, Opus 4.8 हर टर्न पर तय करता है कि क्या तर्क आवश्यक है। सरल प्रश्नों के लिए यह सीधे उत्तर देता है, जबकि जटिल समस्याओं के लिए पहले तर्क करता है। Opus 4.7 की तुलना में कम टोकन की बर्बादी होती है।
जानने योग्य नई सुविधाएँ
Effort Control — अब सभी योजनाओं पर उपलब्ध
मॉडल चयनकर्ता के साथ एक नया नियंत्रण आता है जिससे उपयोगकर्ता यह तय कर सकते हैं कि Claude किसी उत्तर में कितना प्रयास लगाए। Opus 4.8 डिफ़ॉल्ट रूप से high प्रयास पर होता है, और कठिन कार्यों के लिए extra और max विकल्प भी उपलब्ध हैं। Claude Code में दर सीमाएँ बढ़ाई गई हैं ताकि अधिक टोकन उपयोग को संभाल सके।
Fast Mode — 2.5x गति, कम लागत
Fast मोड अब Claude API पर Opus 4.8 के लिए शोध पूर्वावलोकन के रूप में उपलब्ध है। यह प्रति सेकंड 2.5× अधिक आउटपुट टोकन प्रदान करता है और लागत लगभग तीन गुना सस्ती है।
बातचीत के बीच में System संदेश
Messages API अब role: "system" प्रविष्टियों को संदेशों की array में स्वीकार करता है। इससे आप कार्य के बीच Claude के निर्देशों को अपडेट कर सकते हैं बिना प्रॉम्प्ट कैश को तोड़े — यह तब उपयोगी है जब अनुमतियाँ या संदर्भ किसी एजेंटिक लूप के दौरान बदलते हैं।
कम न्यूनतम प्रॉम्प्ट कैश
कैश किए जाने योग्य प्रॉम्प्ट की न्यूनतम लंबाई अब 1,024 टोकन कर दी गई है। जो प्रॉम्प्ट Opus 4.7 पर बहुत छोटे होकर कैश नहीं हो पाते थे, अब वे बिना किसी कोड बदलाव के कैश दर्ज बनाएंगे।
वास्तविक दुनिया के बेंचमार्क
| बेंचमार्क | Opus 4.8 प्रदर्शन |
|---|---|
| Super-Agent | सभी मामलों को शुरू से अंत तक पूरा किया (केवल यही मॉडल ऐसा कर पाया) |
| CursorBench | प्रत्येक स्तर पर सभी पूर्व Opus मॉडलों से बेहतर प्रदर्शन |
| Online-Mind2Web | 84% (अब तक का सबसे मजबूत मॉडल) |
| Legal Agent Benchmark | सर्वोच्च दर्ज स्कोर; पहला मॉडल जिसने कुल मिलाकर 10% का आंकड़ा पार किया |

Opus 4.8 उन परिदृश्यों में सबसे प्रभावी है जहाँ दीर्घकालिक स्वायत्तता महत्वपूर्ण होती है — जैसे कोडिंग एजेंट, अनुसंधान एजेंट, कानूनी कार्यप्रवाह, और एंटरप्राइज़ ज्ञान कार्य।
मूल्य निर्धारण — Opus 4.7 जैसा ही
| मोड | इनपुट | आउटपुट |
|---|---|---|
| Standard | $5 / 1M tokens | $25 / 1M tokens |
| Fast | $10 / 1M tokens | $50 / 1M tokens |
Opus 4.7 जितनी ही कीमत पर बेहतर प्रदर्शन। API पर मॉडल आईडी है claude-opus-4-8। यह 1M टोकन कॉन्टेक्स्ट विंडो और 128k अधिकतम आउटपुट टोकन को सपोर्ट करता है।
आगे क्या: Mythos-श्रेणी के मॉडल
Anthropic ने एक नए मॉडल वर्ग की भी झलक दी है जिसका "बुद्धि स्तर Opus से भी अधिक" है। कुछ संगठनों ने पहले से ही Claude Mythos Preview का उपयोग साइबरसुरक्षा कार्यों में Project Glasswing के माध्यम से शुरू कर दिया है। कंपनी योजना बना रही है कि सभी ग्राहकों को आने वाले हफ्तों में Mythos-श्रेणी के मॉडल उपलब्ध कराए जाएँ, जब आवश्यक सुरक्षा व्यवस्थाएँ हो जाएँ।
मॉडल विविधता क्यों महत्वपूर्ण है
अब हर सप्ताह नए AI मॉडल आ रहे हैं। डेवलपर्स के लिए वास्तविक सवाल यह नहीं है कि कौन सा मॉडल “सबसे अच्छा” है — बल्कि यह कि कौन सा मॉडल किस कार्य के लिए सही है, और उनके बीच बिना किसी झंझट के कैसे स्विच किया जाए।
यही समस्या Felo AI हल करता है। अपने AI-संचालित सर्च से आगे बढ़ते हुए, जो उन्नत मॉडलों से वास्तविक समय के जवाब प्रदान करता है, Felo एक LLM Playground भी देता है, जहाँ आप विभिन्न अग्रणी मॉडलों को एक ही स्थान पर कॉल, परीक्षण, और तुलना कर सकते हैं। न API कुंजियों का झंझट, न डैशबोर्ड बदलने की ज़रूरत। बस मॉडल चुनें, अपना प्रॉम्प्ट चलाएँ, और देखें यह कैसे प्रदर्शन करता है।
अगर आप अपने कार्यप्रवाह के लिए मॉडल का मूल्यांकन कर रहे हैं, या बस यह जानने के इच्छुक हैं कि कौन-कौन से मौजूद हैं, तो उन्हें एक ही इंटरफ़ेस में होना तुलना की प्रक्रिया को बहुत आसान बना देता है।
Felo AI को मुफ़्त में आज़माएँ → https://felo.ai
यह पोस्ट इन भाषाओं में भी उपलब्ध है: English, 简体中文, 日本語, 한국어, 繁體中文, Français, العربية, Русский, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Türkçe, Italiano, ไทย, Español, বাংলা and Português।