Laporan Evaluasi Pertanyaan Fuzzy Mesin Pencari AI (v1.3)

Artikel ini mengevaluasi kinerja beberapa mesin pencari AI dalam menangani "pertanyaan kueri fuzzy." Felo AI tampil terbaik dengan tingkat akurasi 80%, diikuti oleh Perplexity Pro. Artikel ini menganalisis kekuatan dan kelemahan masing-masing produk dan menyediakan studi kasus spesifik sebagai ilustrasi. Data dan hasil evaluasi telah dibuat sumber terbuka, menawarkan wawasan berharga untuk pengembangan mesin pencari AI.
I. Kesimpulan
Di era informasi yang jenuh saat ini, seiring dengan semakin kompleksnya pertanyaan pengguna, kesenjangan kinerja antara sistem Pencarian AI semakin terlihat. Hal ini terutama berlaku ketika berhadapan dengan konfigurasi perangkat lunak, beberapa sumber data, informasi yang tidak tersedia secara online, atau pertanyaan terkait tanggal. Kami menyebut pertanyaan yang menantang ini sebagai "pencarian pertanyaan ambigu." Dalam evaluasi ini, kami menguji secara komprehensif beberapa mesin Pencarian AI populer, termasuk Perplexity Basic, Perplexity Pro, GenSpark, Felo AI, iAsk, dan You.com, dengan fokus pada jenis pertanyaan ini.
Setelah serangkaian pengujian yang ketat, kami menyimpulkan:
- Felo AI muncul sebagai performer terbaik, menunjukkan kemampuan luar biasa dalam menangani pertanyaan ambigu. Ia memimpin dengan tingkat akurasi yang mengesankan sebesar 80%, secara efisien memproses data dari berbagai sumber dan memberikan jawaban yang rinci dan dapat diandalkan untuk pertanyaan kompleks, mirip dengan seorang ahli berpengalaman.
- Perplexity Pro mengamankan tempat kedua dengan skor 70%, menunjukkan ketahanan dalam menangani beberapa pertanyaan kompleks.
- iAsk tampil cukup baik, mencapai tingkat akurasi 60% dan kadang-kadang memberikan jawaban yang efektif untuk pertanyaan ambigu.
- Perplexity Basic, GenSpark, dan You.com berkinerja kurang baik dalam evaluasi ini. Model bahasa mereka menunjukkan kelemahan yang jelas dalam memahami dan memproses pertanyaan ambigu, mencapai tingkat akurasi masing-masing 55%, 45%, dan 35%, yang kurang memuaskan.
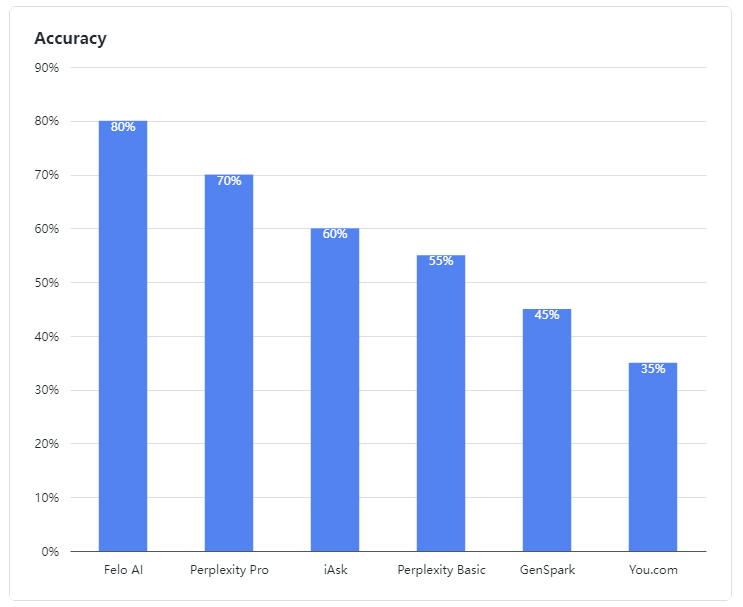
Gambar 1: Tingkat akurasi produk yang dievaluasi
II. Data Evaluasi
Dalam penilaian kami, pertanyaan ambigu didefinisikan sebagai pertanyaan yang melibatkan konfigurasi perangkat lunak, beberapa sumber data, informasi yang tidak tersedia secara online, atau informasi terkait tanggal. LLM sering menggabungkan konten dari beberapa sumber untuk menjawab pertanyaan semacam itu.
Kasus uji pertanyaan ambigu kami bersifat open-source:
👉 Kasus uji: https://github.com/sparticleinc/ASEED/blob/main/datasets/ambiguity_search.csv
👉 Hasil uji: https://github.com/sparticleinc/ASEED/tree/main/evaluations/promptfoo/ambiguity_search
III. Analisis Kasus
👉 Pertanyaan: Di mana Olimpiade berikutnya akan diadakan?
Kebenaran dasar: Olimpiade Musim Panas 2028, juga dikenal sebagai Permainan XXXIV Olimpiade, akan diadakan di Los Angeles, AS.
Komentar: Karena banyaknya informasi online yang menyatakan bahwa Olimpiade berikutnya akan diadakan di Paris, Prancis pada tahun 2024, semua produk kecuali Felo AI menjawab dengan salah.

