Claude Opus 4.8 Dirilis: Model Paling Mumpuni dari Anthropic Sejauh Ini

Anthropic baru saja merilis Claude Opus 4.8 — lebih cepat, lebih jujur, dan lebih baik dalam tugas-tugas agensial. Berikut semua pembaruannya dan mengapa ini penting bagi para pengembang.

Anthropic merilis Claude Opus 4.8 minggu ini. Ini adalah model paling mumpuni yang telah mereka buat dan tersedia secara umum, dikembangkan dari Opus 4.7 dengan peningkatan dalam pemrograman, penalaran, tugas-tugas agensial, dan kejujuran. Harganya tetap sama: $5 per satu juta token input, $25 per satu juta token output.
Berikut perubahan yang terjadi dan mengapa hal ini penting bagi para pengembang yang membangun di atasnya.
Apa yang Berubah Sejak Opus 4.7?
Berikut perubahan yang sebenarnya:
1. Penilaian dan Kejujuran yang Lebih Baik
Opus 4.8 jauh lebih kecil kemungkinannya membuat klaim tanpa dasar atau membiarkan kesalahan kode lolos tanpa diperhatikan. Evaluasi Anthropic menunjukkan bahwa model ini empat kali lebih kecil kemungkinannya dibanding pendahulunya untuk membiarkan bug dalam kodenya sendiri tanpa memberi tanda. Ini merupakan peningkatan penting ketika Anda mempercayai model untuk bekerja secara otonom.
Penguji awal melaporkan bahwa model ini mengajukan pertanyaan yang tepat, mendeteksi kesalahannya sendiri, dan menolak rencana yang tidak masuk akal.
2. Performa Agensial yang Lebih Kuat
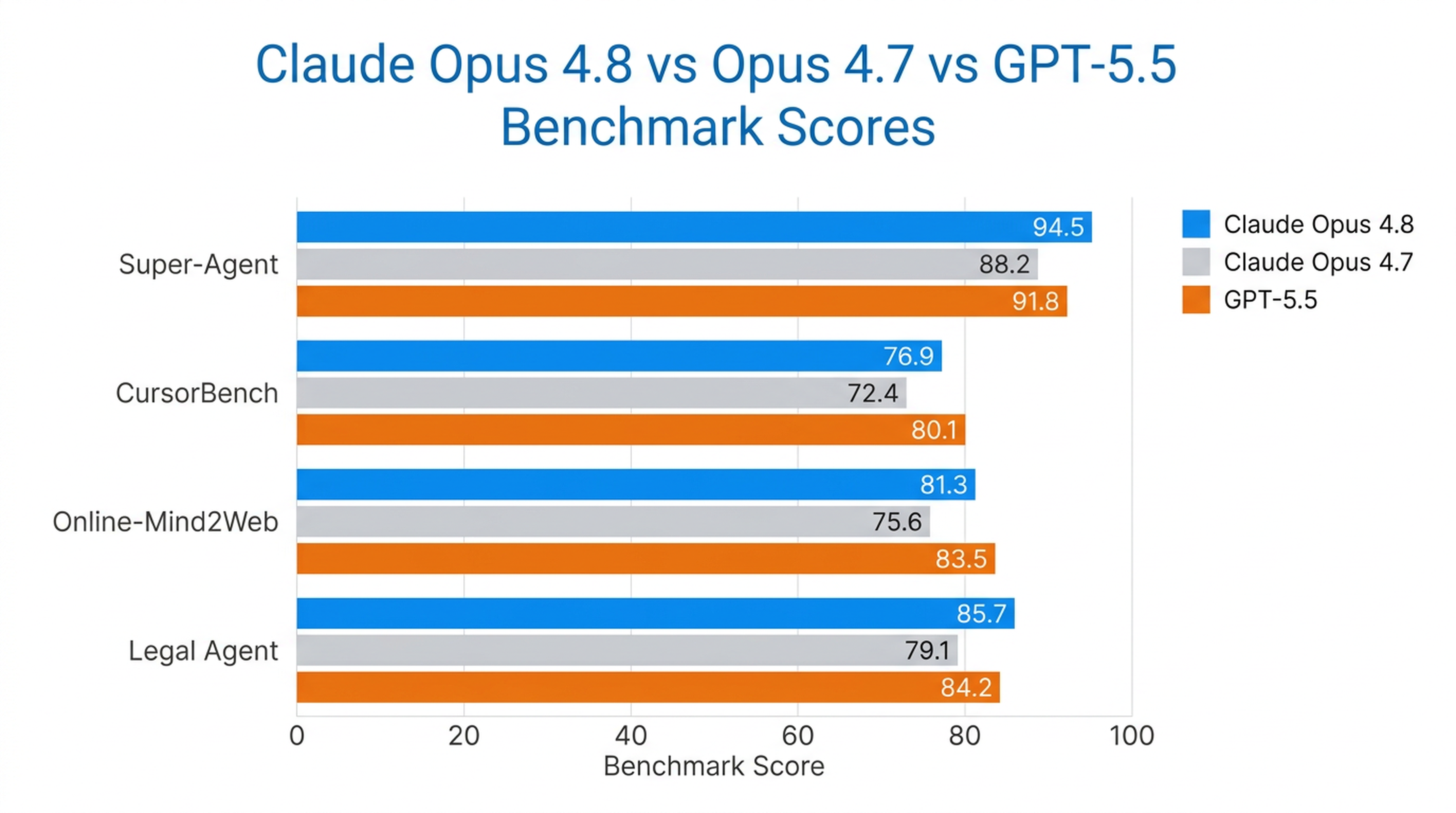
Opus 4.8 adalah satu-satunya model yang menyelesaikan setiap kasus secara menyeluruh pada tolok ukur Super-Agent Anthropic, mengungguli model Opus sebelumnya dan GPT-5.5 dengan biaya setara. Pada CursorBench, ia melampaui versi Opus sebelumnya di setiap tingkat usaha, menggunakan langkah pemanggilan alat yang lebih sedikit untuk kecerdasan yang sama.
Ini juga merupakan model penggunaan komputer dan agen peramban terkuat yang diuji oleh Anthropic, dengan skor 84% pada Online-Mind2Web.
3. Pemanggilan Alat yang Lebih Cepat dan Efisien
Model ini lebih kecil kemungkinannya untuk melewatkan panggilan alat yang dibutuhkan suatu tugas—masalah yang dikenal pada Opus 4.7. Jejak agensial yang panjang juga tetap fokus pada tugas dengan lebih sedikit penyimpangan setelah kompaksi konteks.
4. Pemikiran Adaptif yang Benar-Benar Adaptif
Dengan pemikiran adaptif diaktifkan, Opus 4.8 memutuskan setiap giliran apakah penalaran diperlukan. Pencarian sederhana mendapatkan jawaban langsung. Masalah kompleks diproses dengan penalaran sebelum jawaban diberikan. Token yang terbuang lebih sedikit dibandingkan dengan Opus 4.7.
Fitur Baru yang Perlu Diketahui
Pengendalian Usaha — Sekarang Tersedia di Semua Paket
Kontrol baru di samping pemilih model memungkinkan pengguna memilih seberapa besar usaha yang dikeluarkan Claude untuk sebuah respons. Opus 4.8 secara bawaan menggunakan tingkat usaha high, dengan opsi extra dan max untuk tugas yang lebih sulit. Batas kecepatan di Claude Code telah ditingkatkan untuk menangani penggunaan token yang lebih tinggi.
Mode Cepat — 2,5x Lebih Cepat, Biaya Lebih Rendah
Mode cepat kini tersedia untuk Opus 4.8 sebagai pratinjau riset di API Claude. Mode ini memberikan hingga 2,5× lebih banyak token output per detik dengan biaya tiga kali lebih murah dibandingkan model sebelumnya.
Pesan Sistem di Tengah Percakapan
Messages API kini menerima entri role: "system" di dalam array pesan. Anda dapat memperbarui instruksi Claude di tengah tugas tanpa merusak cache prompt — berguna saat izin atau konteks berubah selama loop agensial.
Batas Minimum Cache Prompt yang Lebih Rendah
Panjang prompt minimum yang dapat di-cache turun menjadi 1.024 token. Prompt yang sebelumnya terlalu pendek untuk di-cache di Opus 4.7 kini dapat membuat entri cache tanpa perubahan kode apa pun.
Tolok Ukur di Dunia Nyata
| Tolok Ukur | Kinerja Opus 4.8 |
|---|---|
| Super-Agent | Semua kasus diselesaikan sepenuhnya (satu-satunya model yang melakukannya) |
| CursorBench | Melampaui semua model Opus sebelumnya di setiap tingkat usaha |
| Online-Mind2Web | 84% (model terkuat yang diuji) |
| Legal Agent Benchmark | Skor tertinggi yang tercatat; model pertama yang menembus 10% secara keseluruhan |

Opus 4.8 paling kuat di area di mana otonomi jangka panjang penting — agen pemrograman, agen riset, alur kerja hukum, dan pekerjaan pengetahuan perusahaan.
Harga — Tidak Berubah dari Opus 4.7
| Mode | Input | Output |
|---|---|---|
| Standar | $5 / 1M token | $25 / 1M token |
| Cepat | $10 / 1M token | $50 / 1M token |
Harga sama seperti Opus 4.7, dengan performa yang lebih baik. ID model di API adalah claude-opus-4-8. Model ini mendukung jendela konteks 1 juta token dan output maksimum 128k token.
Selanjutnya: Model Kelas Mythos
Anthropic juga memberi petunjuk tentang kelas model baru dengan “kecerdasan yang bahkan lebih tinggi dari Opus.” Sejumlah kecil organisasi sudah menggunakan Claude Mythos Preview untuk pekerjaan keamanan siber melalui Project Glasswing. Perusahaan berencana menghadirkan model kelas Mythos ke semua pelanggan dalam beberapa minggu mendatang, setelah langkah-langkah pengamanan diterapkan.
Mengapa Keberagaman Model Itu Penting
Kini model AI baru diluncurkan hampir setiap minggu. Bagi pengembang yang membangun di atasnya, pertanyaan sebenarnya bukanlah model mana yang “terbaik” — melainkan model mana yang paling tepat untuk setiap tugas, dan bagaimana beralih di antara mereka tanpa hambatan.
Itulah masalah yang ditangani oleh Felo AI. Selain pencarian berbasis AI yang mengambil jawaban waktu nyata dari model-model canggih, Felo menawarkan LLM Playground di mana Anda dapat memanggil, menguji, dan membandingkan keluaran dari berbagai model terkemuka di satu tempat. Tidak perlu mengganti kunci API atau berpindah dasbor. Cukup pilih model, jalankan prompt Anda, dan lihat kinerjanya.
Jika Anda sedang mengevaluasi model untuk alur kerja Anda, atau sekadar penasaran dengan apa yang tersedia, memiliki semuanya dalam satu antarmuka membuat proses perbandingan jauh lebih mudah.
Coba Felo AI Secara Gratis → https://felo.ai
Tulisan ini juga tersedia dalam English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, Français, العربية, Русский, اردو, Deutsch, Tiếng Việt, Türkçe, Italiano, ไทย, Español, বাংলা and Português.