Cara Menggunakan Model Penalaran OpenAI: model o1-preview/o1-Mini - Chat AI Gratis

Felo AI Chat sekarang mendukung penggunaan gratis model Penalaran O1
Dalam lanskap kecerdasan buatan yang berkembang pesat, OpenAI telah memperkenalkan serangkaian model bahasa besar yang revolusioner yang dikenal sebagai seri o1. Model-model ini dirancang untuk melakukan tugas penalaran yang kompleks, menjadikannya alat yang kuat bagi pengembang dan peneliti. Dalam posting blog ini, kita akan menjelajahi cara menggunakan model penalaran OpenAI secara efektif, dengan fokus pada kemampuan, batasan, dan praktik terbaik untuk implementasi.
Felo AI Chat sekarang mendukung penggunaan gratis model Penalaran O1. Cobalah sekarang!!


Memahami Model Seri OpenAI o1
Model seri o1 berbeda dari iterasi sebelumnya dari model bahasa OpenAI karena metodologi pelatihan unik mereka. Mereka memanfaatkan pembelajaran penguatan untuk meningkatkan kemampuan penalaran mereka, memungkinkan mereka berpikir kritis sebelum menghasilkan respons. Proses pemikiran internal ini memungkinkan model untuk menghasilkan rantai penalaran yang panjang, yang sangat bermanfaat untuk mengatasi masalah kompleks.
Fitur Utama Model OpenAI o1
1. **Penalaran Lanjutan**: Model o1 unggul dalam penalaran ilmiah, mencapai hasil yang mengesankan dalam pemrograman kompetitif dan tolok ukur akademis. Misalnya, mereka berada di persentil ke-89 di Codeforces dan telah menunjukkan akurasi setara PhD dalam subjek seperti fisika, biologi, dan kimia.
2. **Two Variants**: OpenAI menawarkan dua versi model o1 melalui API mereka:
- **o1-preview**: Ini adalah versi awal yang dirancang untuk mengatasi masalah sulit menggunakan pengetahuan umum yang luas.
- **o1-mini**: Varian yang lebih cepat dan lebih hemat biaya, terutama cocok untuk tugas pemrograman, matematika, dan sains yang tidak memerlukan pengetahuan umum yang luas.
3. **Jendela Konteks**: Model o1 dilengkapi dengan jendela konteks yang substansial sebesar 128.000 token, memungkinkan input dan penalaran yang luas. Namun, sangat penting untuk mengelola konteks ini secara efektif untuk menghindari batasan token.
Memulai dengan Model OpenAI o1
Untuk mulai menggunakan model o1, pengembang dapat mengaksesnya melalui endpoint penyelesaian obrolan dari API OpenAI.
Apakah Anda siap untuk meningkatkan pengalaman interaksi AI Anda? Felo AI Chat sekarang menawarkan kesempatan untuk menjelajahi model Penalaran O1 yang mutakhir tanpa biaya!
Cobalah secara gratis model penalaran o1.
Batasan Beta Model OpenAI o1
Penting untuk dicatat bahwa model o1 saat ini dalam tahap beta, yang berarti ada beberapa batasan yang perlu diperhatikan:
Selama fase beta, banyak parameter API penyelesaian obrolan belum tersedia. Yang paling mencolok:
- Modalitas: hanya teks, gambar tidak didukung.
- Jenis pesan: hanya pesan pengguna dan asisten, pesan sistem tidak didukung.
- Streaming: tidak didukung.
- Alat: alat, pemanggilan fungsi, dan parameter format respons tidak didukung.
- Logprobs: tidak didukung.
- Lainnya:
temperature,top_pdanntetap pada1, sementarapresence_penaltydanfrequency_penaltytetap pada0. - Asisten dan Batch: model ini tidak didukung dalam API Asisten atau API Batch.
**Mengelola Jendela Konteks**:
Dengan jendela konteks sebesar 128.000 token, sangat penting untuk mengelola ruang ini secara efektif. Setiap penyelesaian memiliki batas maksimum token output, yang mencakup baik token penalaran maupun token penyelesaian yang terlihat. Misalnya:
- **o1-preview**: Hingga 32.768 token
- **o1-mini**: Hingga 65.536 token
Kecepatan Model OpenAI o1
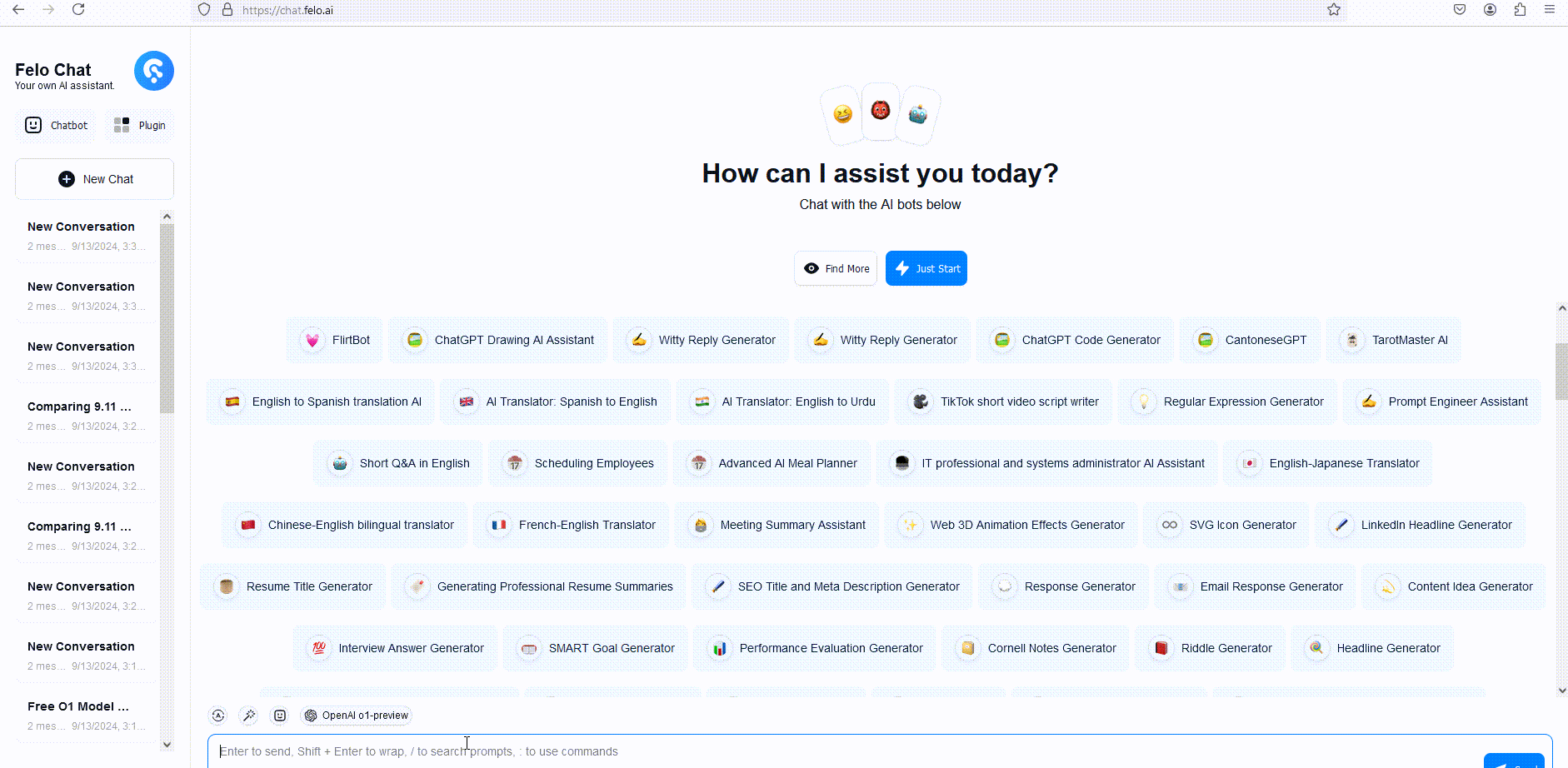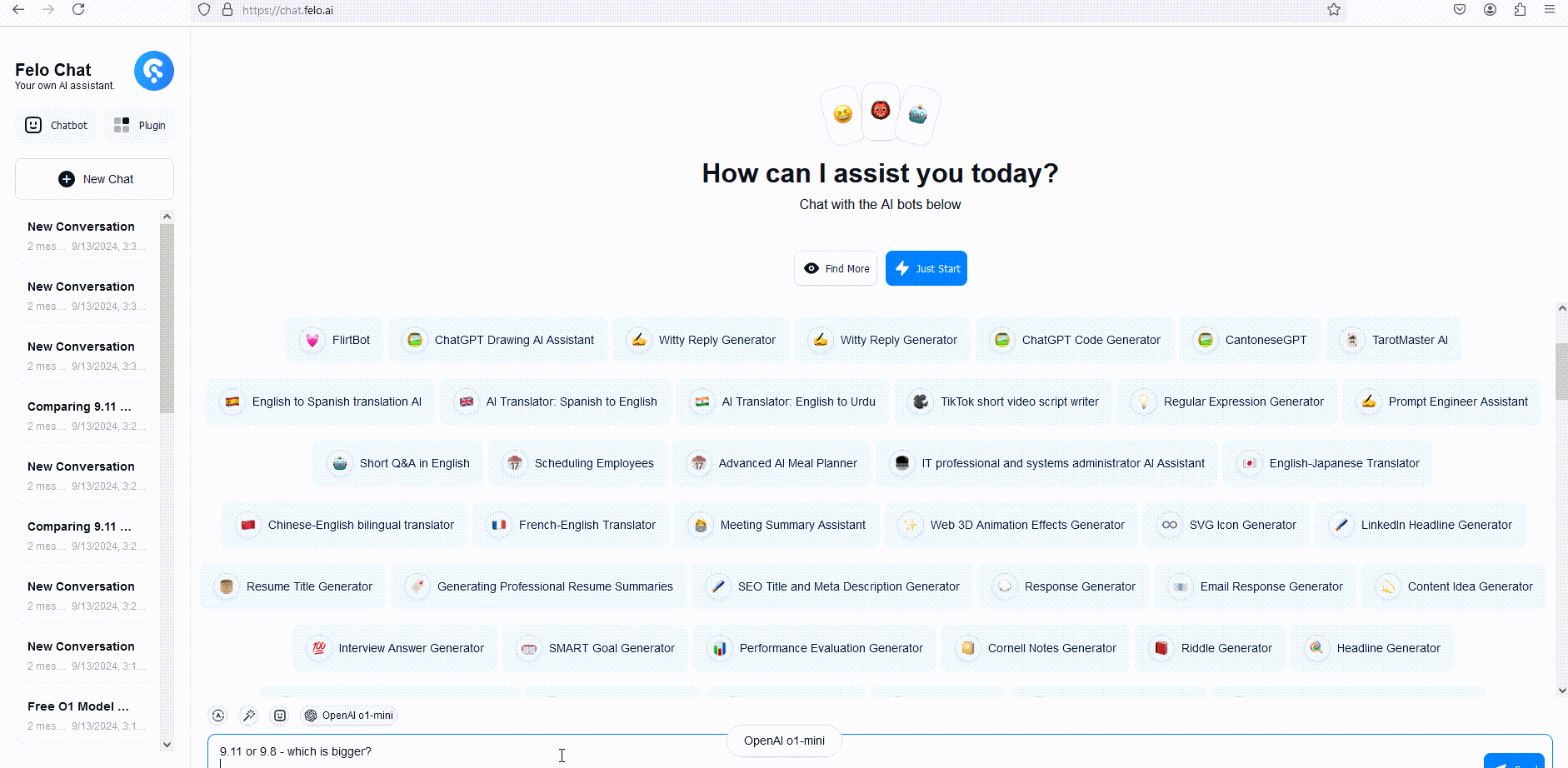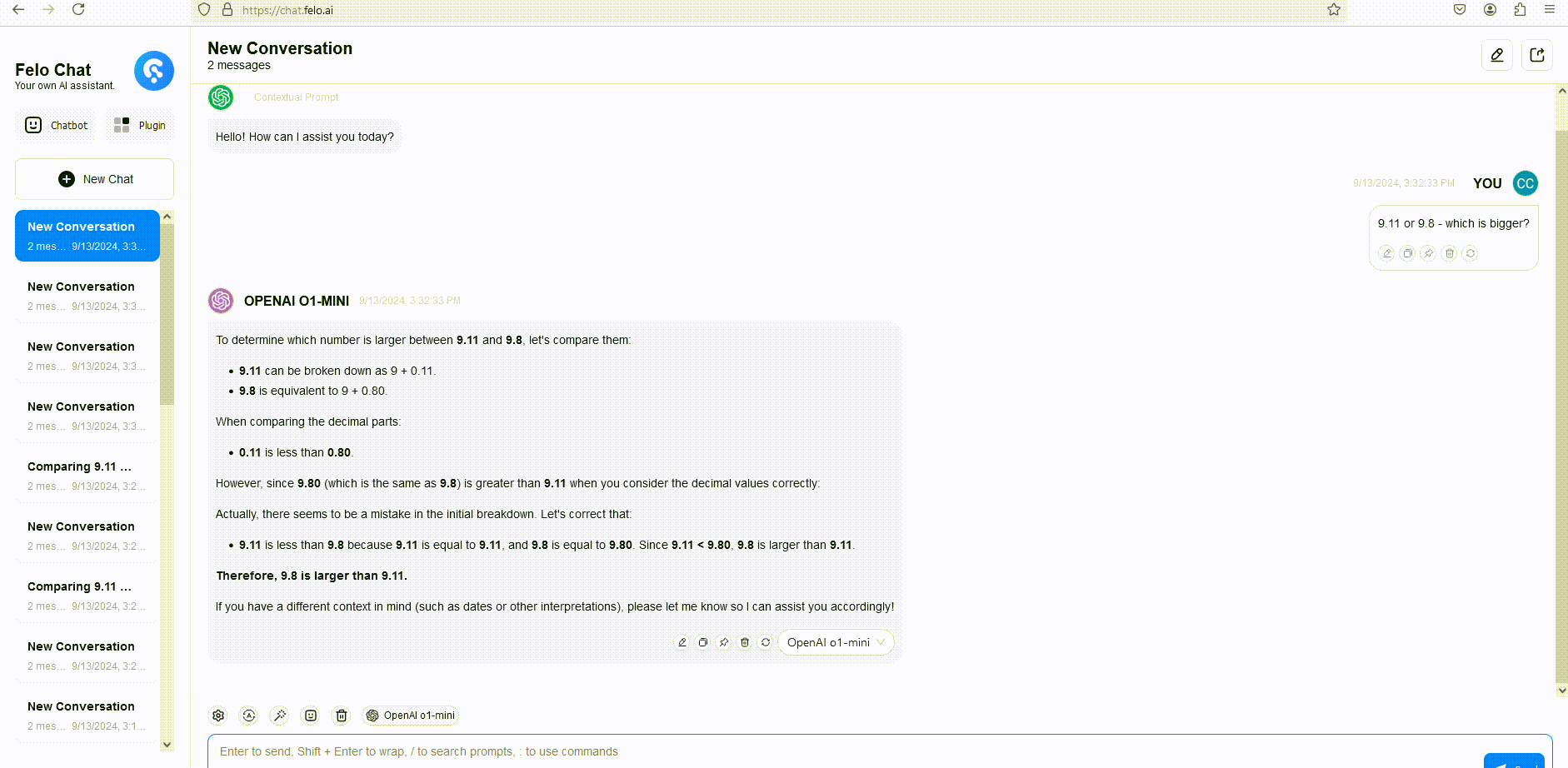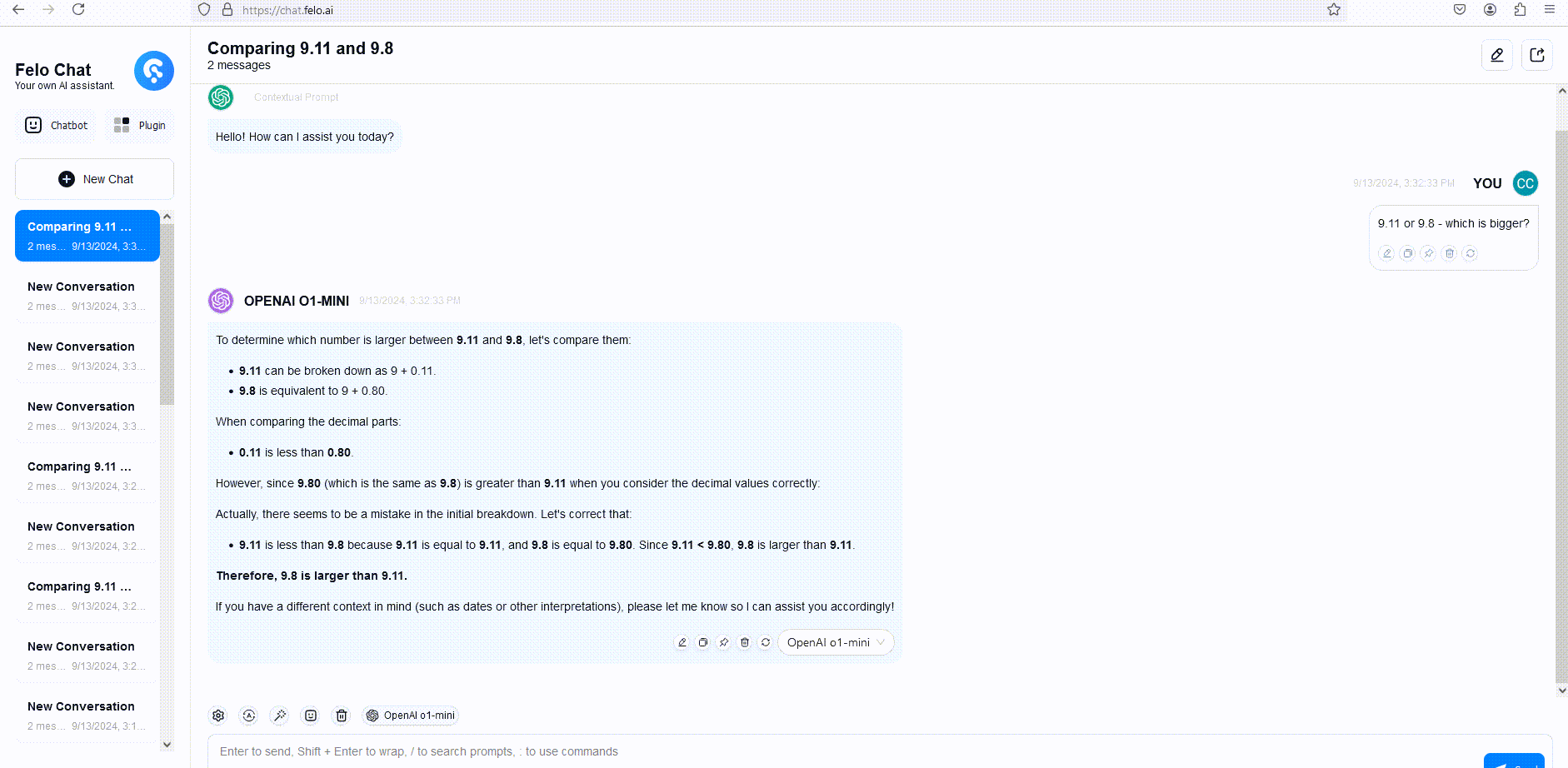
Untuk menggambarkan, kami membandingkan respons dari GPT-4o, o1-mini, dan o1-preview terhadap pertanyaan penalaran kata. Meskipun GPT-4o memberikan jawaban yang salah, baik o1-mini maupun o1-preview menjawab dengan benar, dengan o1-mini mencapai jawaban yang benar sekitar 3-5 kali lebih cepat.

Bagaimana cara memilih antara model GPT-4o, O1 Mini, dan O1 Preview?
**O1 Preview**: Ini adalah versi awal dari model OpenAI O1, dirancang untuk memanfaatkan pengetahuan umum yang luas untuk penalaran melalui masalah kompleks.
**O1 Mini**: Versi O1 yang lebih cepat dan lebih terjangkau, terutama baik untuk tugas pemrograman, matematika, dan sains, ideal untuk situasi yang tidak memerlukan pengetahuan umum yang luas.
Model O1 menawarkan peningkatan signifikan dalam penalaran tetapi tidak dimaksudkan untuk menggantikan GPT-4o dalam semua kasus penggunaan.
Untuk aplikasi yang memerlukan input gambar, pemanggilan fungsi, atau waktu respons yang cepat secara konsisten, model GPT-4o dan GPT-4o Mini masih merupakan pilihan terbaik. Namun, jika Anda mengembangkan aplikasi yang memerlukan penalaran mendalam dan dapat mengakomodasi waktu respons yang lebih lama, model O1 mungkin menjadi pilihan yang tepat.
Tips untuk Memicu Model O1 Mini dan O1 Preview Secara Efektif
Model OpenAI o1 berfungsi paling baik dengan pemicu yang jelas dan langsung. Beberapa teknik, seperti pemicu few-shot atau meminta model untuk "berpikir langkah demi langkah," mungkin tidak meningkatkan kinerja dan bahkan dapat menghambatnya. Berikut adalah beberapa praktik terbaik yang harus diikuti:
1. **Jaga Pemicu Tetap Sederhana dan Langsung**: Model paling efektif ketika diberikan instruksi singkat dan jelas tanpa perlu elaborasi yang luas.
2. **Hindari Pemicu Rantai-Pemikiran**: Karena model ini menangani penalaran secara internal, tidak perlu meminta mereka untuk "berpikir langkah demi langkah" atau "menjelaskan penalaran Anda."
3. **Gunakan Pembatas untuk Kejelasan**: Gunakan pembatas seperti tanda kutip tiga, tag XML, atau judul bagian untuk mendefinisikan bagian-bagian berbeda dari input dengan jelas, yang membantu model menginterpretasikan setiap bagian dengan benar.
4. **Batasi Konteks Tambahan dalam Generasi Augmented Retrieval (RAG)**: Saat menyediakan konteks atau dokumen tambahan, sertakan hanya informasi yang paling relevan untuk menghindari memperumit respons model.
Harga untuk model o1 Mini dan 1 Preview.
Perhitungan biaya untuk model o1 Mini dan 1 Preview berbeda dari model lain, karena mencakup biaya tambahan untuk token penalaran.
Harga o1-mini
$3,00 / 1M token input
$12,00 / 1M token output
Harga o1-preview
$15,00 / 1M token input
$60,00 / 1M token output
Mengelola Biaya Model o1-preview/ o1-mini
Untuk mengontrol pengeluaran dengan model seri o1, Anda dapat menggunakan parameter `max_completion_tokens` untuk menetapkan batas pada total jumlah token yang dihasilkan model, mencakup baik token penalaran maupun token penyelesaian.
Dalam model sebelumnya, parameter `max_tokens` mengelola baik jumlah token yang dihasilkan maupun jumlah token yang terlihat oleh pengguna, yang selalu sama. Namun, dengan seri o1, total token yang dihasilkan dapat melebihi jumlah token yang ditampilkan kepada pengguna karena token penalaran internal.
Karena beberapa aplikasi bergantung pada `max_tokens` yang cocok dengan jumlah token yang diterima dari API, seri o1 memperkenalkan `max_completion_tokens` untuk secara khusus mengontrol total jumlah token yang dihasilkan oleh model, termasuk baik token penalaran maupun token penyelesaian yang terlihat. Opsi eksplisit ini memastikan bahwa aplikasi yang ada tetap kompatibel dengan model baru. Parameter `max_tokens` terus berfungsi seperti sebelumnya untuk semua model sebelumnya.
Kesimpulan
Model seri o1 OpenAI mewakili kemajuan signifikan dalam bidang kecerdasan buatan, terutama dalam kemampuan mereka untuk melakukan tugas penalaran yang kompleks. Dengan memahami kemampuan, batasan, dan praktik terbaik untuk penggunaan, pengembang dapat memanfaatkan kekuatan model ini untuk menciptakan aplikasi inovatif. Saat OpenAI terus menyempurnakan dan memperluas seri o1, kita dapat mengharapkan perkembangan yang lebih menarik dalam ranah penalaran yang didorong oleh AI. Apakah Anda seorang pengembang berpengalaman atau baru memulai, model o1 menawarkan kesempatan unik untuk menjelajahi masa depan sistem cerdas. Selamat berkoding!
Felo AI Chat selalu menawarkan Anda pengalaman gratis dengan model AI canggih dari seluruh dunia. Klik di sini untuk mencobanya!