Rapporto di Valutazione delle Domande Fuzzy per Motori di Ricerca AI (v1.3)

Questo articolo valuta le prestazioni di diversi motori di ricerca AI nella gestione delle "domande fuzzy." Felo AI ha ottenuto i migliori risultati con un tasso di accuratezza dell'80%, seguito da Perplexity Pro. L'articolo analizza i punti di forza e di debolezza di ciascun prodotto e fornisce casi studio specifici per illustrazione. I dati e i risultati della valutazione sono stati resi open source, offrendo preziose intuizioni per lo sviluppo di motori di ricerca AI.
I. Conclusione
Nell'era attuale, saturata di informazioni, man mano che le domande degli utenti diventano più complesse, il divario di prestazioni tra i sistemi di ricerca AI diventa sempre più evidente. Questo è particolarmente vero quando si tratta di configurazioni software, più fonti di dati, informazioni non facilmente disponibili online o domande relative a date. Ci riferiamo a queste domande impegnative come "ricerche di domande ambigue." In questa valutazione, abbiamo testato in modo completo diversi motori di ricerca AI popolari, tra cui Perplexity Basic, Perplexity Pro, GenSpark, Felo AI, iAsk e You.com, concentrandoci su questo tipo di query.
Dopo una serie di test rigorosi, abbiamo concluso:
- Felo AI è emerso come il performer di spicco, dimostrando un'eccezionale capacità di gestire domande ambigue. Ha guidato il gruppo con un impressionante tasso di accuratezza dell'80%, elaborando in modo efficiente dati provenienti da più fonti e fornendo risposte dettagliate e affidabili a domande complesse, proprio come un esperto esperto.
- Perplexity Pro si è assicurato il secondo posto con un punteggio del 70%, mostrando resilienza nell'affrontare alcune domande complesse.
- iAsk ha performato in modo adeguato, raggiungendo un tasso di accuratezza del 60% e fornendo occasionalmente risposte efficaci a domande ambigue.
- Perplexity Basic, GenSpark, e You.com hanno avuto prestazioni inferiori in questa valutazione. I loro modelli linguistici hanno mostrato chiare debolezze nella comprensione e nell'elaborazione di domande ambigue, raggiungendo tassi di accuratezza del 55%, 45% e 35% rispettivamente, che sono stati meno che soddisfacenti.
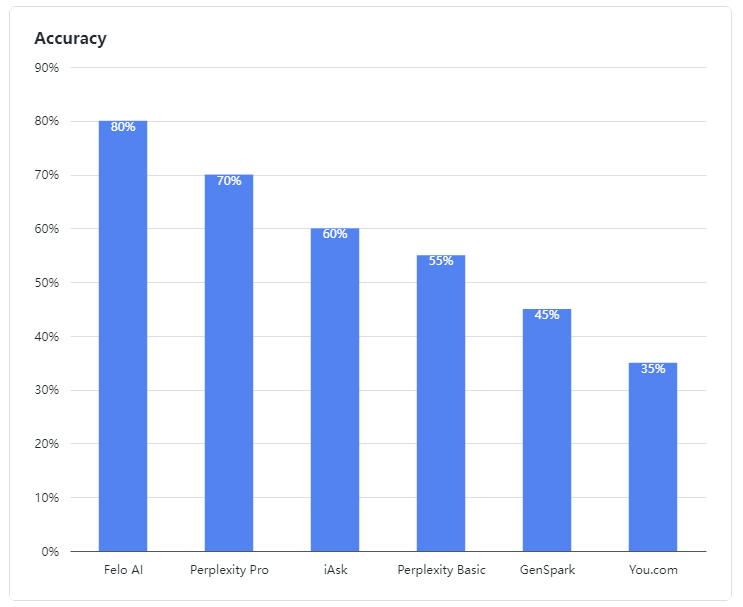
Figura 1: Tassi di accuratezza dei prodotti valutati
II. Dati di Valutazione
Nella nostra valutazione, le domande ambigue sono state definite come quelle che coinvolgono configurazioni software, più fonti di dati, informazioni non disponibili online o informazioni relative a date. Gli LLM spesso assemblano contenuti provenienti da più fonti per rispondere a tali domande.
I nostri casi di test per domande ambigue sono open-source:
👉 Casi di test: https://github.com/sparticleinc/ASEED/blob/main/datasets/ambiguity_search.csv
👉 Risultati dei test: https://github.com/sparticleinc/ASEED/tree/main/evaluations/promptfoo/ambiguity_search
III. Analisi dei Casi
👉 Domanda: Dove si svolgeranno i prossimi Giochi Olimpici?
Verità di base: I Giochi Olimpici estivi del 2028, noti anche come Giochi della XXXIV Olimpiade, si svolgeranno a Los Angeles, USA.
Commento: A causa dell'abbondanza di informazioni online che affermano che le prossime Olimpiadi si svolgeranno a Parigi, Francia, nel 2024, tutti i prodotti tranne Felo AI hanno risposto in modo errato.

