Claude Opus 4.8 rilasciato: il modello più potente di Anthropic fino ad oggi

Anthropic ha appena rilasciato Claude Opus 4.8 — più veloce, più onesto e migliore nei compiti agentici. Ecco tutte le novità e perché sono importanti per gli sviluppatori.

Anthropic ha rilasciato Claude Opus 4.8 questa settimana. È il modello più potente che abbiano mai reso generalmente disponibile, costruito sulla base di Opus 4.7 con miglioramenti in ambito di programmazione, ragionamento, compiti agentici e onestà. Il prezzo rimane lo stesso: 5 $ per milione di token in input, 25 $ per milione di token in output.
Ecco cosa è cambiato e cosa conta per gli sviluppatori che ci costruiscono sopra.
Cosa è cambiato rispetto a Opus 4.7?
Ecco cosa è effettivamente cambiato:
1. Miglior giudizio e maggiore onestà
Opus 4.8 è significativamente meno incline a fare affermazioni non supportate o a lasciare passare difetti di codice senza notarli. Le valutazioni di Anthropic mostrano che è circa quattro volte meno probabile rispetto al suo predecessore che consenta a bug nel proprio codice di passare senza essere segnalati. Questo tipo di miglioramento conta davvero quando ci si affida a un modello per operare in modo autonomo.
I primi tester hanno riferito che fa le domande giuste, individua i propri errori e si oppone quando un piano non ha senso.
2. Prestazioni agentiche più solide
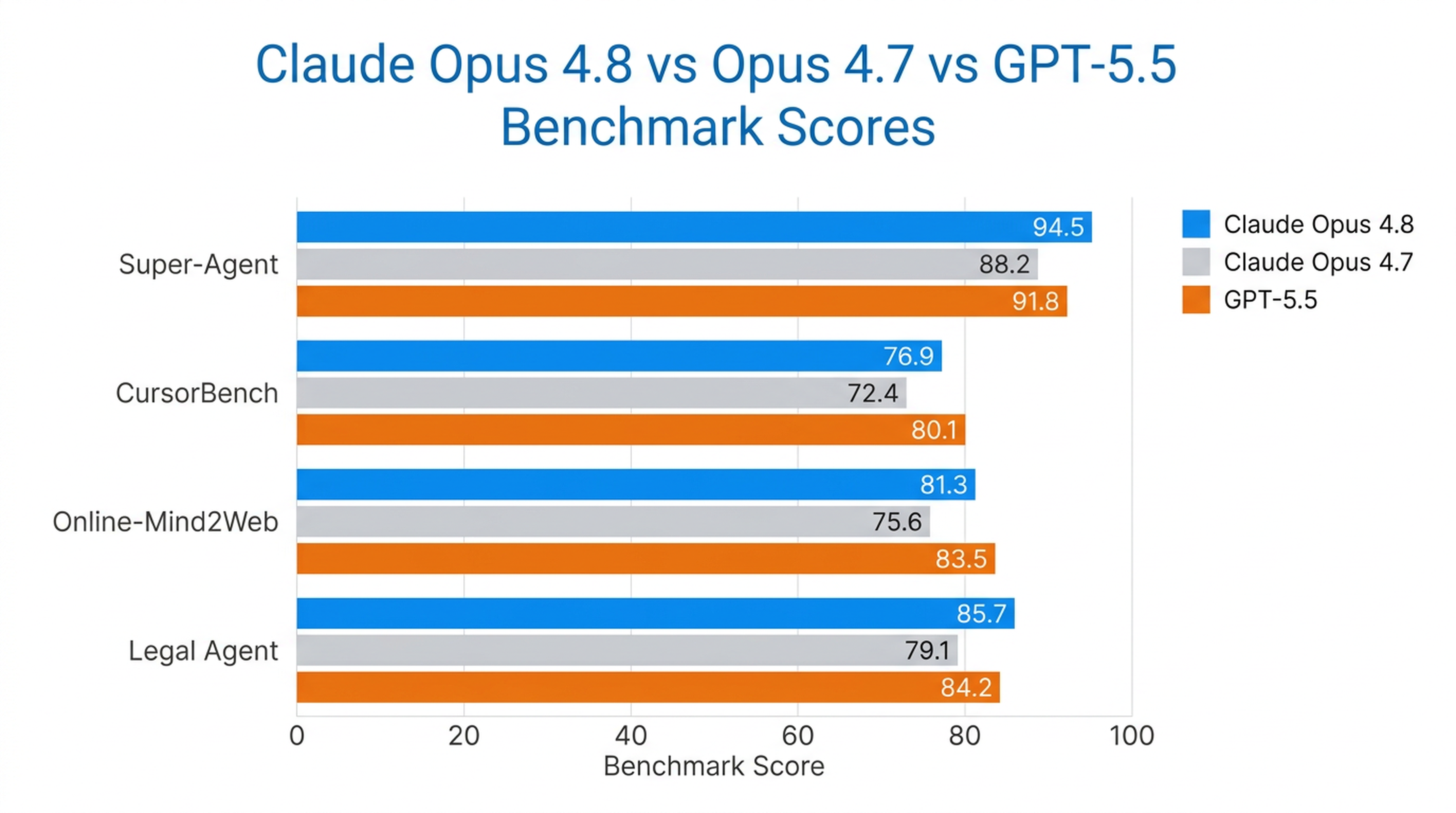
Opus 4.8 è l’unico modello a completare ogni caso end-to-end nel benchmark Super-Agent di Anthropic, superando i precedenti modelli Opus e GPT-5.5 a parità di costo. Su CursorBench supera le versioni precedenti di Opus a ogni livello di impegno, utilizzando meno passaggi di tool-calling per la stessa intelligenza.
È anche il modello più forte nei test di utilizzo del computer e di agenti browser condotti da Anthropic, ottenendo un 84% su Online-Mind2Web.
3. Chiamate agli strumenti più veloci ed efficienti
Il modello è meno incline a saltare una chiamata a uno strumento necessaria per un compito, un punto dolente noto in Opus 4.7. Anche le lunghe tracce agentiche rimangono più focalizzate sul compito con meno deviazioni dopo la compattazione del contesto.
4. Pensiero adattivo che si adatta davvero
Con il pensiero adattivo attivato, Opus 4.8 decide a ogni turno se il ragionamento è necessario. Le ricerche semplici ricevono risposte dirette. I problemi complessi ottengono un ragionamento prima della risposta. Meno token sprecati rispetto a Opus 4.7.
Nuove funzionalità da conoscere
Controllo dello sforzo — ora in tutti i piani
Un nuovo controllo accanto al selettore del modello consente agli utenti di scegliere quanto impegno Claude deve mettere in una risposta. Opus 4.8 è impostato di default su high effort, con opzioni extra e max per i compiti più difficili. I limiti di velocità in Claude Code sono stati aumentati per gestire il maggiore utilizzo di token.
Modalità veloce — 2,5× più rapida, costo inferiore
La modalità veloce è ora disponibile per Opus 4.8 come anteprima di ricerca sull’API di Claude. Offre fino a 2,5× più token di output al secondo a un costo tre volte inferiore rispetto ai modelli precedenti.
Messaggi di sistema a conversazione in corso
L’API dei messaggi ora accetta voci role: "system" all’interno dell’array dei messaggi. Puoi aggiornare le istruzioni di Claude durante un compito senza interrompere la cache del prompt — utile quando permessi o contesto cambiano durante un ciclo agentico.
Soglia minima della cache del prompt più bassa
La lunghezza minima del prompt memorizzabile in cache è scesa a 1.024 token. I prompt che erano troppo brevi per essere memorizzati in cache su Opus 4.7 ora creano voci in cache senza necessità di modificare il codice.
Benchmark nel mondo reale
| Benchmark | Prestazioni di Opus 4.8 |
|---|---|
| Super-Agent | Tutti i casi completati end-to-end (unico modello a riuscirci) |
| CursorBench | Supera tutti i precedenti modelli Opus a ogni livello di sforzo |
| Online-Mind2Web | 84% (modello più forte testato) |
| Legal Agent Benchmark | Punteggio più alto registrato; primo modello a superare il 10% complessivo |

Opus 4.8 è più forte dove l’autonomia a lungo termine è importante — agenti per la programmazione, la ricerca, i flussi di lavoro legali e il lavoro di conoscenza aziendale.
Prezzi — invariati rispetto a Opus 4.7
| Modalità | Input | Output |
|---|---|---|
| Standard | 5 $ / 1M token | 25 $ / 1M token |
| Veloce | 10 $ / 1M token | 50 $ / 1M token |
Stesso prezzo di Opus 4.7, ma con prestazioni migliori. L’ID del modello sull’API è claude-opus-4-8. Supporta la finestra di contesto da 1M di token e un massimo di 128k token in output.
Cosa c’è dopo: i modelli della classe Mythos
Anthropic ha anche accennato a una nuova classe di modelli con “intelligenza ancora più elevata rispetto a Opus”. Un numero limitato di organizzazioni sta già utilizzando Claude Mythos Preview per lavori di cybersecurity attraverso il Project Glasswing. L’azienda prevede di rendere disponibili i modelli della classe Mythos a tutti i clienti nelle prossime settimane, una volta implementate le misure di sicurezza.
Perché la diversità dei modelli è importante
Nuovi modelli di intelligenza artificiale vengono rilasciati ogni settimana. Per gli sviluppatori che li utilizzano, la vera domanda non è quale modello sia “il migliore”, ma quale sia il più adatto per ogni compito — e come passare da uno all’altro senza attriti.
Questo è il problema che Felo AI affronta. Oltre alla sua ricerca potenziata dall’IA che utilizza modelli avanzati per risposte in tempo reale, Felo offre un LLM Playground dove puoi richiamare, testare e confrontare gli output di una vasta gamma di modelli di punta in un’unica piattaforma. Niente più chiavi API da gestire, niente più passaggi tra dashboard. Basta scegliere un modello, eseguire il tuo prompt e vedere come si comporta.
Se stai valutando modelli per il tuo flusso di lavoro, o sei semplicemente curioso di sapere cosa c’è là fuori, averli tutti in un’unica interfaccia rende il processo di confronto molto meno doloroso.
Prova Felo AI gratuitamente → https://felo.ai
Questo articolo è disponibile anche in English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, Français, العربية, Русский, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Türkçe, ไทย, Español, বাংলা and Português.