🙆♀️Risultati rivoluzionari di Felo AI: Accuratezza del benchmark SimpleQA del 91,2%, stabilendo un nuovo standard per la ricerca AI

Felo AI ha raggiunto progressi rivoluzionari nel benchmark SimpleQA, guidando il campo della ricerca AI con un'accuratezza del 91,2%. Scopri come tecnologie innovative come la riscrittura delle query tra lingue migliorano l'esperienza di ricerca.
Innovare i motori di ricerca AI con un'accuratezza senza pari
Siamo entusiasti di annunciare che Felo ha superato tutti i concorrenti nell'ultima performance del benchmark SimpleQA. SimpleQA è un test chiave sviluppato da OpenAI per valutare l'accuratezza fattuale nelle risposte AI. Con un'impressionante 91,2% di accuratezza, Felo Pro (modalità rapida) stabilisce un nuovo standard per i motori di ricerca AI, superando significativamente concorrenti come Perplexity e Gemini.
Benchmark SimpleQA: la pietra di paragone per i motori di ricerca AI
SimpleQA è un benchmark sviluppato da OpenAI per misurare l'efficacia dei sistemi AI nell'utilizzare i dati del web per rispondere a domande fattuali concise. A differenza delle metriche di ricerca tradizionali, SimpleQA si concentra sulla riduzione dei problemi di illusione nei sistemi AI, enfatizzando l'accuratezza e l'affidabilità dei fatti — una sfida di lunga data nel campo dell'AI. L'eccellente performance di Felo in questo benchmark dimostra il nostro impegno a fornire soluzioni all'avanguardia per i motori di ricerca AI.
Metodologia di test: un rigoroso framework di valutazione
Felo ha adottato un framework standardizzato per la valutazione del benchmark SimpleQA, per garantire equità e trasparenza. Il metodo include i seguenti passaggi:
- Domanda: inviare direttamente a Felo le domande del dataset SimpleQA.
- Generazione delle risposte: utilizzare Felo Pro (modalità rapida) per generare le risposte.
Tutti i test sono stati condotti utilizzando lo stesso set di domande e criteri di valutazione, definiti nel protocollo originale di SimpleQA, per garantire un confronto equo tra tutti i partecipanti.
Risultati del test: Felo raggiunge un'accuratezza leader del settore
I risultati del benchmark SimpleQA evidenziano la posizione di leadership di Felo nel campo della ricerca intelligente AI:
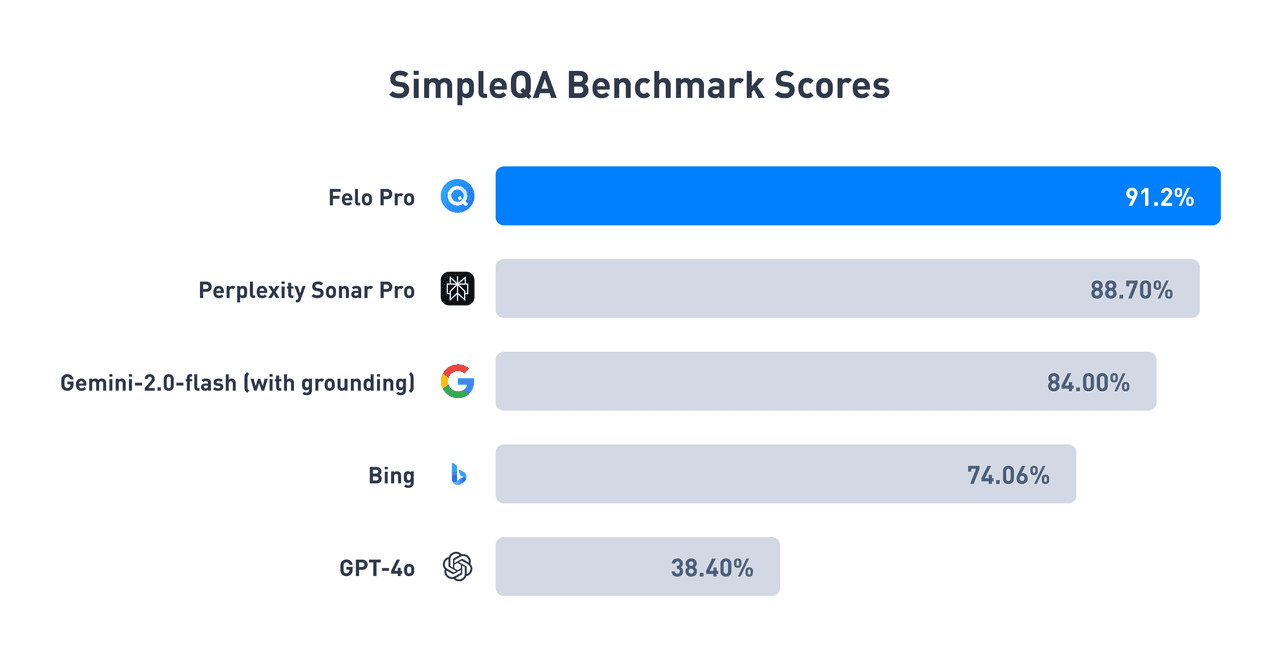
Abbiamo reso pubblici i risultati dei test di Felo, puoi visitare questo link per ulteriori dettagli.
Qual è l'unicità di Felo?
Felo deve la sua eccellente performance nel benchmark SimpleQA alla sua architettura e design innovativi, con differenze chiave che includono:
- Avanzata riscrittura delle query multilingue Felo è in grado di scomporre intelligentemente le query originali in sottoquery più dettagliate, scegliendo anche l'ambiente linguistico più appropriato per la ricerca in base alle domande degli utenti, ottimizzando queste sottoquery per i motori di ricerca tradizionali e i sistemi RAG. Questo consente a Felo di ottenere più pagine web rilevanti.
- Tecnologia di indicizzazione mista Felo utilizza una tecnologia di ricerca mista basata su parole chiave e semantica, applicando una compressione semantica consapevole del modello ai contenuti delle pagine web, permettendo a Felo di rimuovere il rumore irrilevante mantenendo la densità fattuale chiave. Questo assicura che il LLM (modello di linguaggio di grandi dimensioni) riceva solo le informazioni più rilevanti e di alta qualità.
- Formazione focalizzata sulla ricerca A differenza dei motori di ricerca generali, Felo ottimizza i modelli di ordinamento per il modo unico in cui i modelli di linguaggio di grandi dimensioni elaborano le informazioni, sviluppando internamente 7 LLM, per fornire risultati di ricerca più precisi e contestualizzati.