Claude Opus 4.8 リリース:Anthropic 史上最も高性能なモデル

Anthropic が新たに Claude Opus 4.8 をリリース — より高速で、より誠実、そしてエージェント的タスクにさらに強力。開発者にとって重要な改善点をすべて紹介します。

Anthropic は今週、Claude Opus 4.8 をリリースしました。これはこれまで一般公開された中で最も高性能なモデルで、Opus 4.7 を基盤に、コーディング、推論、エージェント的タスク、誠実性のすべてにおいて改良が加えられています。価格は据え置きで、入力トークン 100 万あたり 5 ドル、出力トークン 100 万あたり 25 ドルです。
ここでは、何が変わったのか、そして開発者にとってなぜ重要なのかを解説します。
Opus 4.7 からの変更点
実際に変更された内容は次の通りです。
1. 判断力と誠実性の向上
Opus 4.8 は、根拠のない主張をする可能性や、コードの欠陥を見逃す可能性が大幅に低減しました。Anthropic の評価によると、Opus 4.7 と比べて 約 4 倍もバグを見逃さない 傾向があるとのことです。これは、モデルに自律的な作業を任せる際に非常に重要な改善です。
初期のテスターは、このモデルが「正しい質問をし、ミスを自ら発見し、計画に問題があれば指摘する」と報告しています。
2. より強力なエージェント的性能
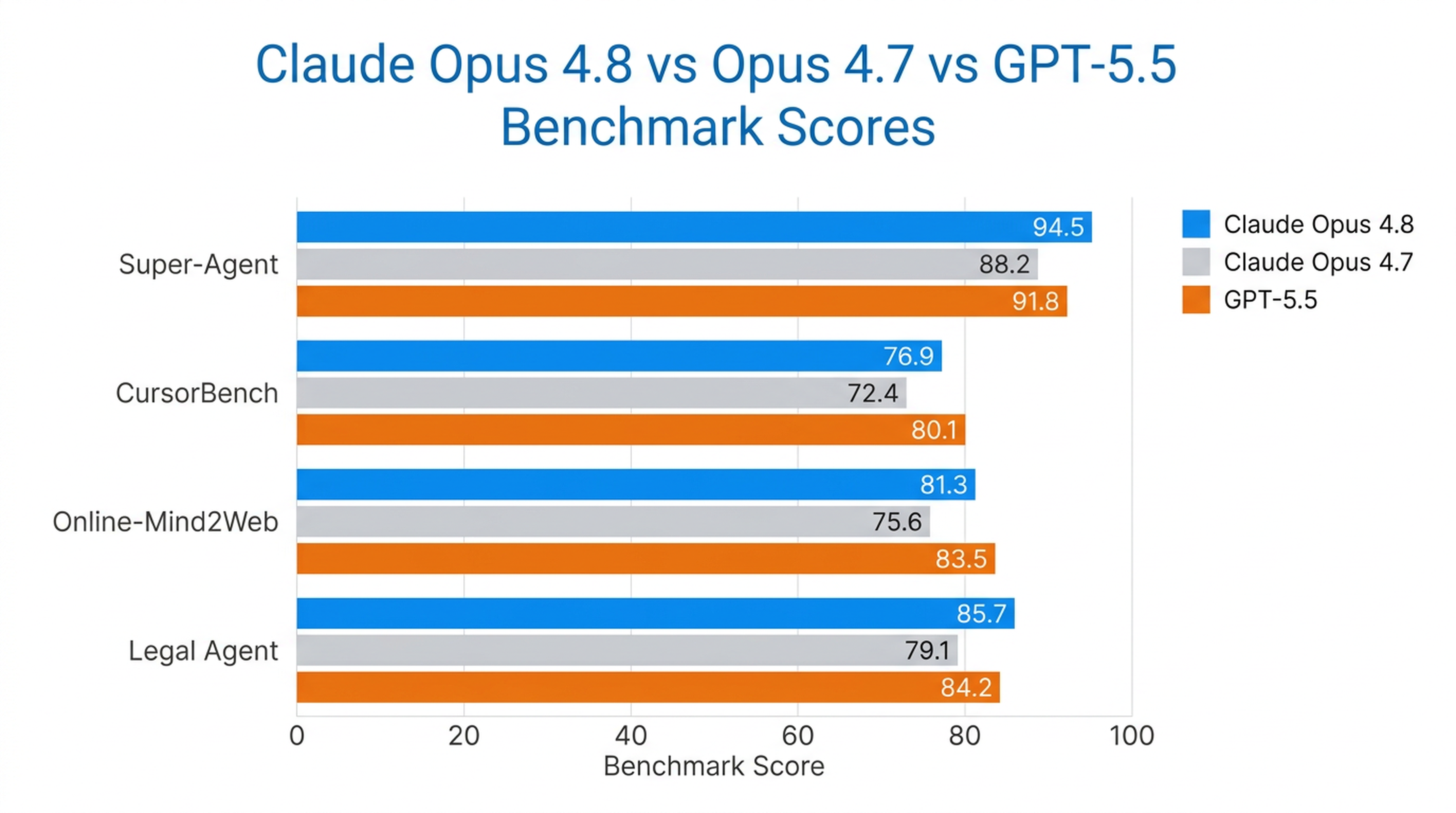
Opus 4.8 は、Anthropic の Super-Agent ベンチマークにおいて 全ケースをエンドツーエンドで完了した唯一のモデル であり、コスト同等で過去の Opus モデルや GPT-5.5 を上回りました。CursorBench でも、あらゆる取り組みレベルで以前の Opus を凌駕し、同等の知能レベルをより少ないツール呼び出しステップで達成しています。
さらに、Anthropic がテストした中で最も強力なコンピュータ操作・ブラウザエージェントモデルであり、Online-Mind2Web で 84% のスコア を記録しました。
3. より高速で効率的なツール呼び出し
Opus 4.7 で課題とされていた「必要なツール呼び出しをスキップする問題」が軽減されました。長いエージェント実行でも、コンテキスト圧縮後のタスク逸脱が減少し、一貫性が向上しています。
4. 真に適応する「アダプティブ思考」
アダプティブ思考を有効にすると、Opus 4.8 はターンごとに推論が必要かどうかを判断します。単純な照会では即答し、複雑な問題では回答前に推論を行います。Opus 4.7 よりもトークンの無駄が少なくなっています。
注目すべき新機能
Effort Control — すべてのプランで利用可能に
モデルセレクターの横に新しいコントロールが追加され、Claude が応答にどれだけの「労力」をかけるかを選択できるようになりました。Opus 4.8 はデフォルトで high 努力に設定され、より難しいタスク向けに extra や max のオプションも用意されています。Claude Code のレート制限も、より多くのトークン使用に対応できるよう緩和されました。
Fast モード — 2.5 倍の速度、低コスト
Fast モードは現在、Claude API 上で Opus 4.8 のリサーチプレビューとして提供中です。従来モデルと比べて 最大 2.5 倍の出力トークン速度 を実現し、コストは 3 分の 1 です。
会話中に更新可能なシステムメッセージ
Messages API は、メッセージ配列内に role: "system" エントリを受け入れるようになりました。これにより、プロンプトキャッシュを壊すことなく、タスク途中で Claude の指示を更新できます。権限やコンテキストが変化するエージェント実行中に便利です。
プロンプトキャッシュの最小長さを引き下げ
キャッシュ可能なプロンプトの最小長さが 1,024 トークン に短縮されました。Opus 4.7 では短すぎてキャッシュ化できなかったプロンプトも、コード変更なしでキャッシュエントリを作成できるようになりました。
実世界のベンチマーク
| ベンチマーク | Opus 4.8 の性能 |
|---|---|
| Super-Agent | 全ケースをエンドツーエンドで完了(唯一のモデル) |
| CursorBench | すべての労力度レベルで過去の Opus モデルを上回る |
| Online-Mind2Web | 84%(最も強力なテスト済みモデル) |
| Legal Agent Benchmark | 過去最高スコア、初の 10% 超え達成 |

Opus 4.8 は、長期的な自律処理が重要な場面 — コーディングエージェント、リサーチエージェント、法務ワークフロー、企業知識業務 — において最も強力です。
価格 — Opus 4.7 から据え置き
| モード | 入力 | 出力 |
|---|---|---|
| Standard | $5 / 1M tokens | $25 / 1M tokens |
| Fast | $10 / 1M tokens | $50 / 1M tokens |
価格は Opus 4.7 と同じで、性能は向上しています。API 上のモデル ID は claude-opus-4-8 です。100 万トークンのコンテキストウィンドウと、最大 128k 出力トークンに対応しています。
次に来るもの:Mythos クラスのモデル
Anthropic は、「Opus を超える知能」を持つ新しいモデルクラスを示唆しています。少数の組織はすでに Claude Mythos Preview を Project Glasswing 経由でサイバーセキュリティ業務に利用中です。安全対策が整い次第、数週間以内にすべての顧客向けに Mythos クラスモデルを展開する予定です。
モデル多様性が重要な理由
現在では毎週のように新しい AI モデルが登場しています。開発者にとって重要なのは、「どのモデルが一番か」ではなく、「どのタスクにどのモデルが適しているか」、そして「モデル間をスムーズに切り替える方法」です。
この課題に取り組むのが Felo AI です。高度なモデルを活用してリアルタイム回答を提供する AI 検索だけでなく、LLM Playground も提供しており、主要モデルをひとつの場所で呼び出し・テスト・比較できます。API キーの切り替えやダッシュボード移動の手間は不要です。モデルを選び、プロンプトを実行し、結果を確認するだけです。
自分のワークフローに最適なモデルを評価する際や、単に最新モデルを試したいときでも、一つのインターフェースで比較できると作業がずっとシンプルになります。
無料で Felo AI を試す → https://felo.ai
この記事は次の言語でもお読みいただけます:English、简体中文、한국어、繁體中文、हिन्दी、Français、العربية、Русский、اردو、Bahasa Indonesia、Deutsch、Tiếng Việt、Türkçe、Italiano、ไทย、Español、বাংলা、Português。