🙆♀️Felo AIの画期的な成果:SimpleQAベンチマークで91.2%の正答率を達成、AI検索の新基準を確立

Felo AIはSimpleQAベンチマークテストで91.2%の正確性を達成し、AI検索分野で先頭を走っています。言語を超えたクエリの書き換えなどの革新的な技術が検索体験をどのように向上させるかを知ることができます。
Felo AIは、SimpleQAベンチマークテストにおいて91.2%の正答率を記録し、AI検索分野をリードする成果を達成しました。クロスリンガルなクエリリライトなどの革新的技術が検索体験をどのように向上させるのか、ご紹介します。
AI検索エンジンの精度を飛躍的に向上
私たちは、FeloがSimpleQAベンチマークテストにおいて他の競合を凌駕する成績を収めたことを発表できることを大変嬉しく思います。SimpleQAは、OpenAIが開発したAIの事実性に関する精度を評価する重要なベンチマークテストです。Felo Pro(クイックモード)は、91.2%という驚異的な正答率を達成し、PerplexityやGeminiといった競合製品を大きく上回る結果を残しました。この成果は、AI検索エンジンの新たな基準を確立するものです。
SimpleQAベンチマークとは?AI検索エンジンの精度を測る試金石
SimpleQAは、AIシステムがWeb上のデータを活用し、簡潔で事実に基づいた質問にどれだけ正確に回答できるかを評価するためにOpenAIが開発したベンチマークテストです。従来の検索エンジンの評価指標とは異なり、SimpleQAは事実の正確性と信頼性を重視し、AIシステムにおける「幻覚(ハルシネーション)」の発生を抑えることに焦点を当てています。Feloがこのベンチマークで優れた成績を収めたことは、AI検索エンジンの最先端技術を追求する当社の取り組みを示すものです。
厳格な評価プロセス:公平性と透明性を確保
Feloは、SimpleQAベンチマークテストに対し、標準化された評価手法を採用し、公平性と透明性を確保しています。評価プロセスは以下の手順で行われました。
- 質問の入力:SimpleQAのデータセットに含まれる質問をそのままFeloに入力
- 回答の生成:Felo Pro(クイックモード)を用いて回答を生成
すべてのテストは、同じ質問セットと評価基準に基づいて実施されており、これはSimpleQAのオリジナルの評価プロトコルに準拠しています。この手法により、公正な比較が可能となりました。
テスト結果:Felo、業界トップの正確性を記録
SimpleQAベンチマークの結果は、FeloがAI検索分野においてリーダーであることを証明しています。
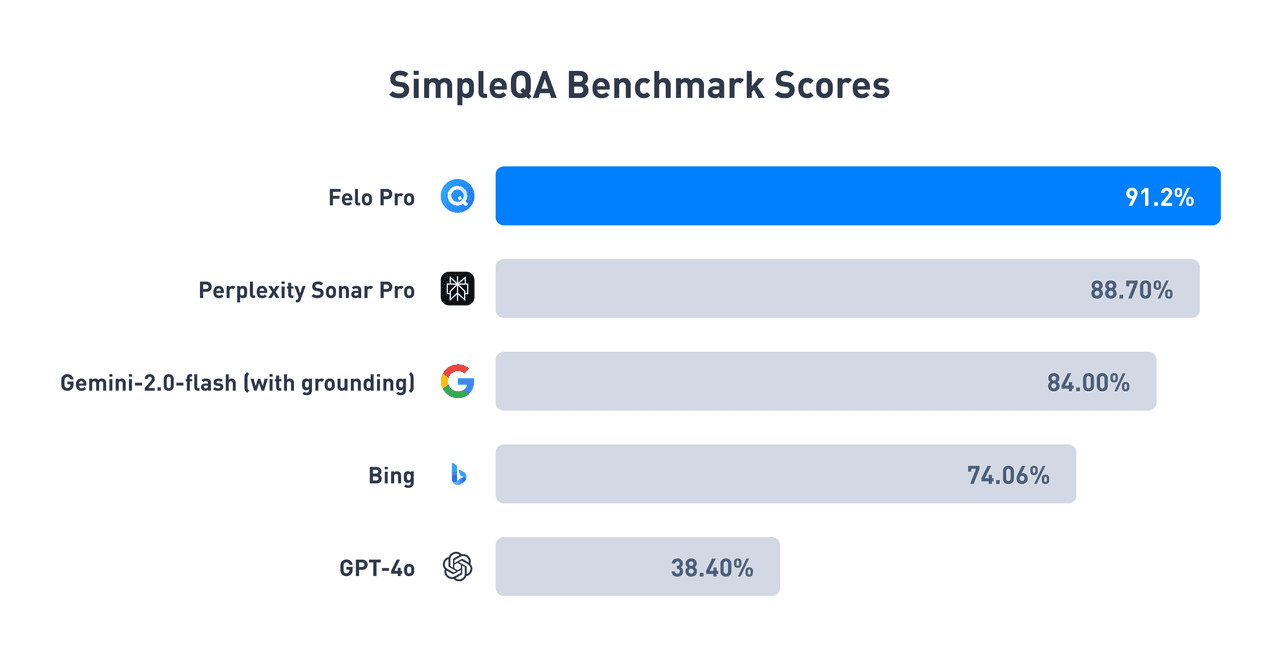
(Feloのテスト結果はオープンに公開されており、詳細はこちらからご覧いただけます)
Feloが優れている理由とは?
FeloがSimpleQAベンチマークで卓越した結果を出せた理由は、その革新的なアーキテクチャと独自の設計にあります。主な特長は以下の通りです。
-
高度なクロスリンガルクエリリライト
Feloは、ユーザーのクエリをより細かく分解し、最適な言語環境を選択して検索を実行できます。従来の検索エンジンやRAGシステムに最適化されたサブクエリを生成することで、より関連性の高いWebページを取得することが可能です。
-
ハイブリッドインデックス技術
Feloは、キーワード検索とセマンティック検索を組み合わせた独自の技術を採用しています。ページコンテンツをモデルが認識できる形で圧縮し、不要なノイズを排除しながらも重要な情報を保持することで、LLM(大規模言語モデル)が受け取る情報の精度と品質を向上させています。
-
検索特化型のトレーニング
Feloは、汎用的な検索エンジンとは異なり、大規模言語モデルが情報を処理する特性に最適化されたランキングモデルを採用しています。独自開発した7つのLLMを活用し、コンテキストに即した正確な検索結果を提供できるように設計されています。
Feloは、これからもAI検索エンジンの進化を加速させ、ユーザーに最高の検索体験を提供してまいります。 🚀