Google Antigravity 向け Felo Web Fetch:製品やウェブ情報を構造化データとして抽出

Felo Web Fetch スキルにより、Google Antigravity エージェントがウェブページをきれいな Markdown、HTML、またはテキストに変換し、製品調査、競合分析、構造化データ収集を行う方法を学びましょう。
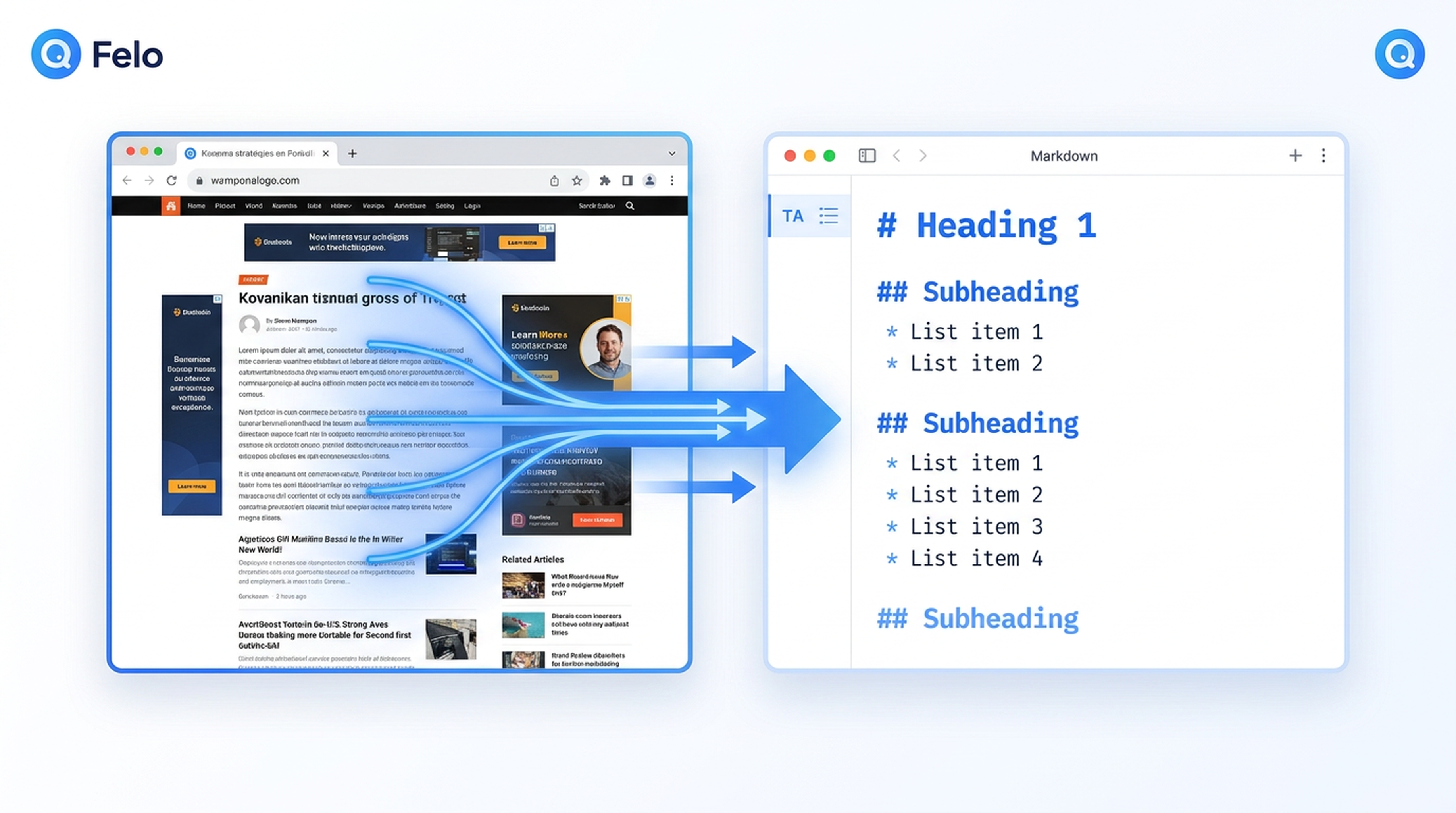
Antigravity エージェントが最初に直面する問題
あなたは Google Antigravity エージェントにリサーチタスクを与えます。たとえば SaaS の価格比較や、競合の機能リストの取得、またはブリーフィング資料の収集などです。エージェントは計画的に進めます。何が必要か は理解しています。しかし、そこで壁にぶつかります。Gemini 3 の学習データにはカットオフ日があるため、エージェントは自力でライブウェブにアクセスできないのです。
そこで登場するのが Felo Skills です。特に Felo Web Fetch スキル は抽出のギャップを埋め、任意のウェブページをきれいで構造化された Markdown、HTML、またはプレーンテキストに変換し、Antigravity エージェントが実際に使える形にします。
Felo Web Fetch とは?
Felo Web Fetch は、Google Antigravity の .agent/skills/ ディレクトリに配置するフォルダベースのスキルです。インストールすると、自動的にトリガーされる機能になります。エージェントはスラッシュコマンドを入力したり、URL をコピーペーストしたりする必要はありません。タスクにウェブページの読み取りが必要な場合、Agent Manager がスキルの説明と照合し、自動的に実行します。
このスキルは Felo Web Extract API(POST /v2/web/extract)を使用して任意の URL からコンテンツを取得し、ワークフローで必要な形式で返します。
| 出力形式 | 使用タイミング |
|---|---|
| Markdown | AI に最適 — 見出し、リスト、リンクを保持したクリーンな構造 |
| HTML | 追加処理のために生の DOM 構造が必要な場合 |
| Text | プレーンテキストの抽出。素早いスキャンや後続のテキスト処理に有用 |
felo.ai/skills/antigravity からインストールできます。フォルダを
.agent/skills/にコピーして Git にコミットするだけで、次回プル時にチーム全員が利用可能になります。
Antigravity 内部での動作
インストール手順は意図的にシンプルです。
# Felo スキルリポジトリをクローン
git clone https://github.com/Felo-Inc/felo-skills.git
# web-fetch スキルを Antigravity のスキルフォルダにコピー
cp -r felo-skills/felo-web-fetch ~/.gemini/antigravity/skills/
.agent/skills/ 内に felo-web-fetch フォルダを配置すると、SKILL.md ファイルが主な機能を担います。その description フィールドが セマンティックトリガーとして機能します。エージェントが 「これら3つのSaaS製品の価格を比較」 や 「この競合ページから機能リストを抽出」 といったタスクに出会うと、Agent Manager はスキルを自動的にロードします。手動操作は必要ありません。
コア機能
1. クリーンな記事抽出のための「読みやすさモード」
すべてのウェブページが構造化されているわけではありません。ブログ、ニュース記事、ドキュメントには、ナビゲーションバーやサイドバー、フッター、広告のようなノイズが多く含まれます。Felo Web Fetch は 読みやすさモード(--with-readability true)をサポートし、メインの記事コンテンツだけを抽出して他を除去します。
これは特にリサーチを行う Antigravity エージェントにとって有効で、200KB のノイズを解析する代わりに、集中した読みやすい記事本文を受け取り、分析に必要な正確な情報を得られます。
2. 精密な抽出のための CSS セレクター指定
ページ全体でなく、一部だけを取得したい場合もあります。たとえば .pricing-section 内の料金表や、div.changelog 内の更新履歴などです。Felo Web Fetch は --target-selector パラメータを受け付け、関心のある DOM 要素だけを抽出できます。
競合分析ワークフローでは、これによりエージェントが関係のないコンテンツを除き、構造化された価格データや機能比較表、製品仕様を取得できます。
3. クロールモード:Fast と Fine
| モード | 適した用途 |
|---|---|
fast | 静的ページ、ドキュメント、ブログ記事などすぐにレンダリングされるページ |
fine | JavaScript 多用ページ、SPA、動的コンテンツを読み込む必要があるページ |
Agent Manager のデフォルトは効率重視の fast です。React ベースの製品ページや認証が必要なダッシュボードなどから抽出する場合は fine に切り替え、コンテンツ読み込み完了後に抽出します。
4. Cookie および認証対応
ログインが必要なページに対して、Felo Web Fetch は Cookie(--cookie "session_id=xxx")やカスタムユーザーエージェント文字列の指定をサポートします。これにより、Antigravity エージェントは認証付きダッシュボード、内部ドキュメントポータル、またはパートナーページからもコンテンツを抽出できるようになります。
5. 構造化サマリー:リンクと画像
生データに加えて、スキルは以下を含めることができます。
--with-links-summary true— すべてのリンクを抽出してサマリー化--with-images-summary true— すべての画像をメタデータ付きで抽出--with-images-readability true— 画像をその周囲の文脈とペアリング
製品概要をまとめるリサーチエージェントにとって、これらのサマリーは構造化されたデータポイントとなり、後続リサーチ用の参照リンクや、視覚比較用の画像 URL、文脈的メタデータといった形で成果物を豊かにします。
実際のユースケース
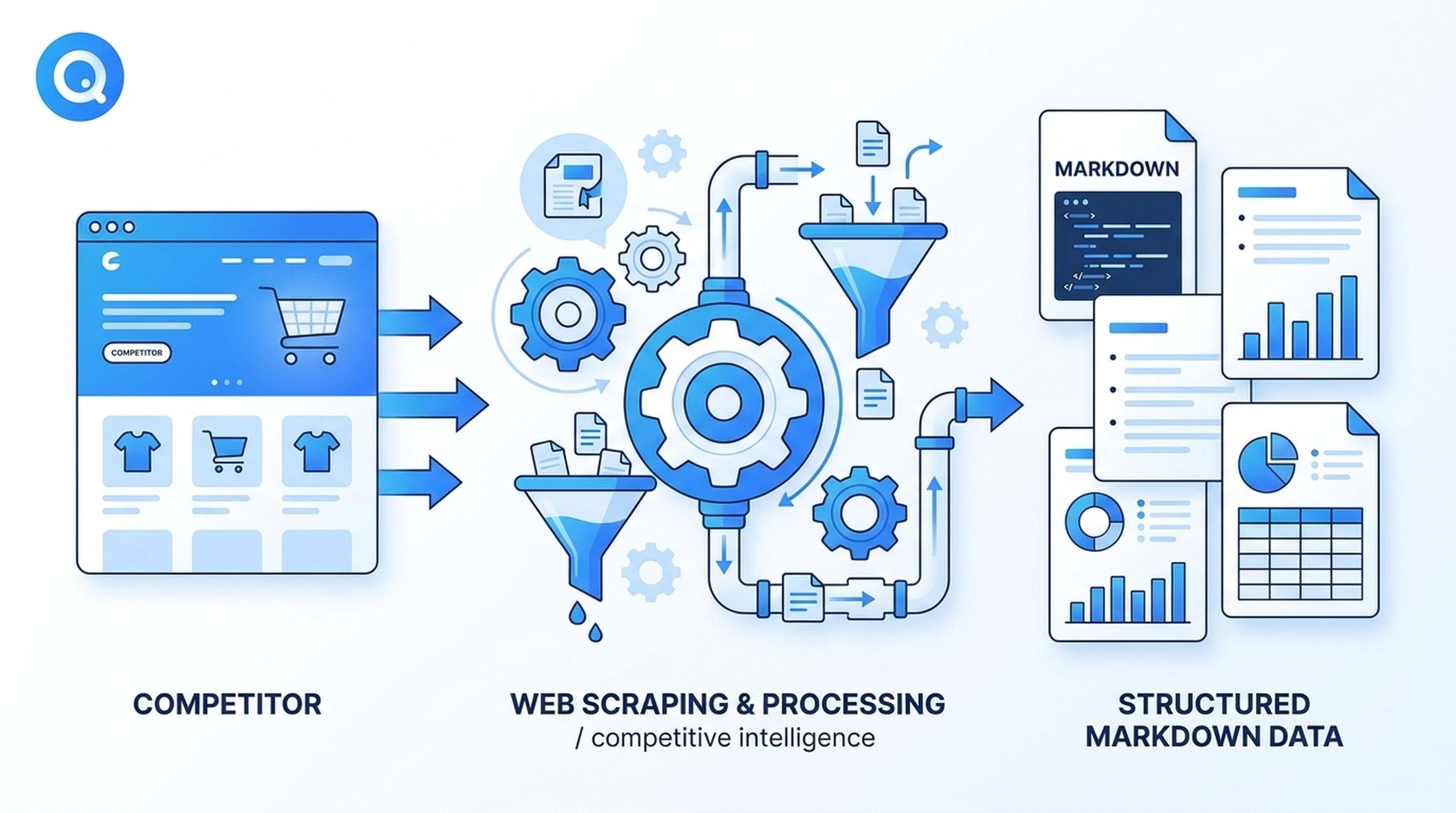
大規模な競合インテリジェンス
あなたの Antigravity エージェントが、3 社の競合製品ページを毎週モニタリングするタスクを与えられたとします。Felo Web Fetch を導入すれば、エージェントは次のように動作します。
- 各競合の料金ページに自動的にアクセス
- コンテンツをクリーンな Markdown として抽出
- 機能、料金階層、新要素をベースラインと比較
- 前回の抽出以降の変更をフラグ化
手動でページを取得する必要はありません。スキルがタスクに一致した際に自動的にトリガーされ、データを抽出してエージェントの推論パイプラインに戻します。
製品リサーチと購入判断
ツールやサービス、プラットフォームの評価タスクにおいて、Felo Web Fetch はエージェントに 最新の 製品ページへのアクセスを与えます。仕様、価格、統合リスト、顧客の声などをソースから直接抽出し、最新情報に基づいたレポートを作成します。
コンテンツ作成のための素材収集
コンテンツチームは Antigravity を使ってブリーフィング、マーケット分析、リサーチレポートを作成します。Felo Web Fetch はオリジナルのウェブページから抽出した信頼性のあるソース素材を供給し、エージェントが近似ではなく一次情報に基づいて出力を生成できるようにします。
ドキュメントと API 変更検知
エンジニアリングチームにとって、API ドキュメント、SDK リファレンス、開発者ポータルの変更検知は重要です。Felo Web Fetch はドキュメントを Markdown として抽出し、エージェントが以前のバージョンと比較して破壊的変更や新しいエンドポイント、廃止機能を検出します。
開発者向け API リファレンス
Antigravity 外で Felo Web Fetch をプログラム的に統合する場合、API は非常にシンプルです。
curl -X POST "https://openapi.felo.ai/v2/web/extract" \
-H "Authorization: Bearer $FELO_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"url": "https://example.com/product",
"output_format": "markdown",
"with_readability": true,
"crawl_mode": "fast"
}'
主なリクエストパラメータ:
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
url | string | — | 抽出対象のウェブページ URL |
output_format | string | html | html、markdown、または text |
crawl_mode | string | fast | fast または fine |
with_readability | boolean | — | メインコンテンツのみを抽出 |
target_selector | string | — | 特定要素の CSS セレクター |
wait_for_selector | string | — | 抽出前に要素を待機 |
timeout | integer | — | タイムアウト(ミリ秒) |
set_cookies | array | — | 認証ページ用の Cookie 情報 |
成功時のレスポンスは、選択した output_format に基づいて構造化された data.content 内の抽出コンテンツを返します。
Antigravity チームにとっての重要性
Felo Web Fetch の価値は抽出そのものだけでなく、抽出が エージェントワークフローに何を可能にするか にあります。
1. エージェントはキャッシュ情報ではなく最新データで動作。
Gemini 3 はウェブを閲覧できません。Felo Web Fetch がそのギャップを埋め、抽出時点で任意の URL コンテンツにアクセス可能にします。
2. 構造化された出力は構造化された推論を生む。
クリーンな Markdown 形式で内容が届くため、エージェントは見出し、リスト、テーブル、コードブロックを解析し、ページ構造に根ざした分析を行えます。
3. 設定ずれゼロ。
スキルは .agent/skills/ に存在し Git にコミットされるため、チーム全員が同じ機能を利用可能。ユーザーごとの設定や環境依存の回避策は不要です。
4. 他の Felo Skills と連携。
Felo Search と組み合わせてライブリサーチ検証を行ったり、Felo Slides と連携して抽出コンテンツをプレゼン資料化したりできます。Agent Manager がスキル間の連携を自動で調整します。
はじめ方
Felo Web Fetch を Antigravity ワークフローに導入するのは数分で完了します。
- felo.ai にアクセスし、API キーを作成(Settings → API Keys)
- 環境変数を設定:
export FELO_API_KEY="your-api-key-here" - スキルフォルダをコピー:
.agent/skills/ディレクトリに配置 - Git にコミット: チームのエージェントが自動的に取得
以上です。次にウェブページ読取を含むタスクが発生すると、Felo Web Fetch が自動的にトリガーされ、手動操作もコンテキスト切り替えも不要です。
より広い視点で見ると
Felo Web Fetch は Google Antigravity 向け Felo Skills エコシステムの一部です。これらのスキル群により、Antigravity の Agent Manager は有能なプランナーから、知識ギャップを埋め、チームメモリを保持し、成果物を出荷できる本格的なリサーチ/プロダクションツールに変わります。
Felo Web Fetch が提供する抽出レイヤーは、多くのチームが最初に導入するスキルです。なぜなら、一番差し迫った問題 — 「エージェントがウェブを読めない」 — を解決するからです。抽出が機能すれば、ライブ検索、ナレッジベースの永続化、出力生成の追加は自然な次のステップとなります。
あなたの Antigravity エージェントに、実際のウェブコンテンツを抽出・分析・活用する力を与える準備はできていますか?まずは Felo Web Fetch から始めましょう。無料で、フォルダを置くだけ、チーム全体ですぐに利用できます。
この記事は次の言語でもお読みいただけます:English、简体中文、한국어、繁體中文、हिन्दी、Français、العربية、Русский、اردو、Bahasa Indonesia、Deutsch、Tiếng Việt、Türkçe、Italiano、ไทย、Español、বাংলা、Português。