LLM ナレッジベース vs 永続ワークスペース|AI エージェントに必要なのはどちらか
LLM ナレッジベース(RAG)と永続ワークスペースは解決する課題が異なります。AI エージェントのワークフローに合うアーキテクチャの選び方と、両方が必要になるケースを解説します。
LLM ナレッジベース vs 永続ワークスペース:AI エージェントが本当に必要としているもの
開示: この記事は MemClaw チームが執筆しています。比較はできる限り公平に行っていますが、MemClaw は永続ワークスペース製品であるため、その点をご了承のうえお読みください。
AI エージェントの世界で「ナレッジベース」という言葉は、まったく異なる 2 つの仕組みを指して使われています。この混同が、アーキテクチャ選定の誤りにつながります。
1 つ目は検索システムです。ドキュメント、エンベディング、構造化データの集合体をエージェントがクエリし、回答に必要な情報を取得します。RAG パイプライン、ベクトルデータベース、社内 Wiki などがこれにあたります。
2 つ目はプロジェクトメモリシステムです。特定のプロジェクトで何が起きたか――下された判断、進捗状況、蓄積されたコンテキスト――を記録します。エージェントはデータベースのように検索するのではなく、セッション開始時にまるごと読み込み、作業の進行に合わせて書き戻します。
どちらも「ナレッジベース」と呼ばれますが、解決する課題はまったく別物です。ユースケースに合わない方を選ぶと、時間を浪費し、成果の質も下がります。
従来の LLM ナレッジベースとは
従来の LLM ナレッジベースは、大規模な情報検索のために構築されます。ドキュメント、サポートチケット、製品仕様書、研究論文など大量のコーパスがあり、エージェントがオンデマンドで関連情報を見つける必要がある場合に使います。
一般的なアーキテクチャは次のとおりです。
- ドキュメントをチャンクに分割し、ベクトルストアにエンベディングする
- クエリ時にエージェントがクエリをエンベディングし、意味的に類似したチャンクを取得する
- 取得したチャンクをプロンプトにコンテキストとして注入する
- エージェントが取得コンテンツに基づいて回答を生成する
これが RAG(Retrieval-Augmented Generation)です。以下のようなケースに適しています。
- 製品ナレッジベースから質問に回答するカスタマーサポートエージェント
- 大量のドキュメントコレクションを検索するリサーチアシスタント
- コードベースや API ドキュメントにアクセスするコードアシスタント
- 社内 Wiki やドキュメントを横断検索するエンタープライズ検索
重要な特徴は、ナレッジベースが静的、もしくは更新頻度が低いことです。事実、ドキュメント、参照資料を格納します。エージェントはそこから読み取りますが、実質的に書き戻すことはありません。
永続ワークスペースとは
永続ワークスペースは、プロジェクトの継続性のために構築されます。特定のプロジェクトを複数セッションにわたって進めており、前回何が起きたか、どんな判断が下されたか、今どこまで進んでいるかをエージェントに覚えておいてほしい場合に使います。
アーキテクチャは異なります。
- セッション開始時にエージェントがワークスペースを読み込む(現在の状態を取得)
- セッション中にエージェントが作業を行う
- セッション終了時(または作業中随時)にエージェントが書き戻す――判断を記録し、ステータスを更新し、成果物を保存する
- 次のセッションは更新された状態から始まる
これは読み書きのループです。以下のようなケースに適しています。
- 複数のクライアントプロジェクトを管理するフリーランサー
- 長期にわたるコードベースで作業する開発者
- スプリントをまたいで機能を追跡するプロダクトマネージャー
- AI エージェントでマルチセッションのワークフローを実行するすべてのユーザー
重要な特徴は、ワークスペースが動的かつプロジェクトスコープであることです。参照資料ではなく、運用コンテキスト――進捗、判断、履歴――を格納します。そしてセッションごとに成長していきます。
核心的な違い:参照メモリ vs 運用メモリ
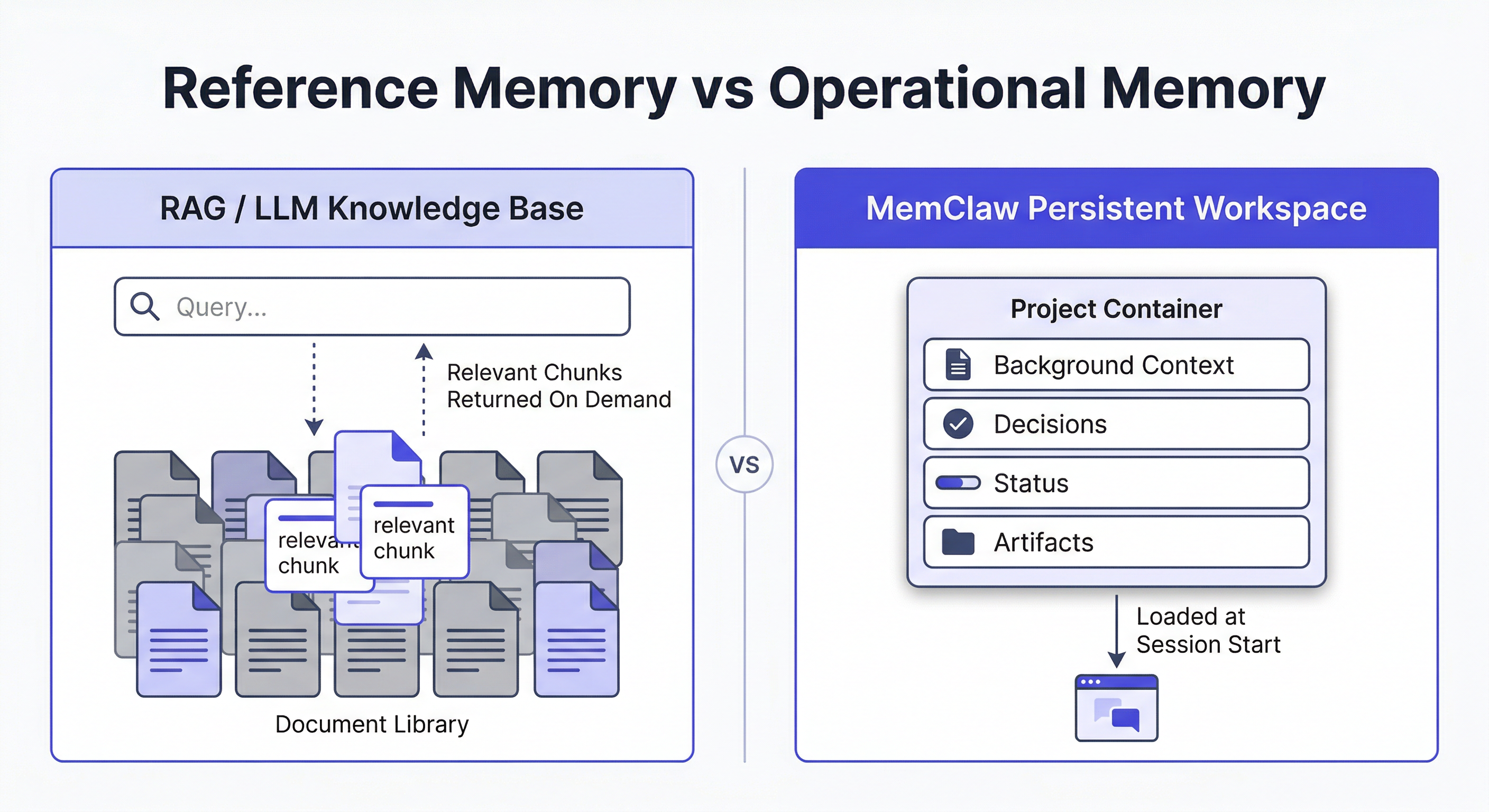
| LLM ナレッジベース | 永続ワークスペース | |
|---|---|---|
| 格納するもの | 事実、ドキュメント、参照資料 | 判断、進捗、プロジェクト履歴 |
| エージェントの使い方 | クエリ → 取得 → コンテキストに利用 | 開始時に読み込み → 作業 → 書き戻し |
| 更新頻度 | 低頻度(バッチ更新) | 毎セッション |
| スコープ | プロジェクト/ユーザー間で共有 | 1 プロジェクトに限定 |
| 主なユースケース | コーパスから質問に回答 | セッションをまたいで作業を継続 |
| 失敗パターン | 誤ったチャンクの取得、ハルシネーション | セッション間でコンテキストが消失 |
どちらが優れているということではありません。解決する課題が異なるのです。混乱が生じるのは、どちらも「ナレッジベース」と呼ばれるためであり、また多くのチームが RAG システムでプロジェクト継続性の問題を解決しようとする(あるいはその逆)ためです。
RAG ナレッジベースが必要なケース
検索ベースのナレッジベースを使うべき場面は次のとおりです。
- 大規模で比較的安定した参照資料のコーパスがある
- トレーニングデータだけでは回答できない質問にエージェントが答える必要がある
- 複数のユーザーやエージェントが同じ情報にアクセスする必要がある
- 情報が事実ベースかつドキュメントベースである(運用情報ではない)
具体例:
- 500 ページの製品ドキュメントから質問に回答するサポートエージェント
- 判例法や契約書を検索するリーガルアシスタント
- 社内 API 仕様書にアクセスする開発者エージェント
エージェントはナレッジベースをオンデマンドでクエリします。ナレッジベースを「覚えておく」必要はなく、そこから取得するだけです。
永続ワークスペースが必要なケース
永続ワークスペースを使うべき場面は次のとおりです。
- 特定のプロジェクトを複数セッションにわたって進めている
- 前回のセッションで何が起きたかをエージェントに知っておいてほしい
- 複数のプロジェクトを管理しており、プロジェクト間の分離が必要
- コンテキストが運用情報(判断、ステータス、履��)であり、参照資料ではない
具体例:
- 数週間にわたってコードベースで作業する開発者エージェント
- 5 つのクライアントプロジェクトを同時に管理するフリーランサーのエージェント
- 仕様策定からローンチまで機能を追跡する PM のエージェント
エージェントはセッション開始時にワークスペースを読み込みます。検索するのではなく、現在の状態を読み取り、前回の続きから作業を再開します。
How To Build A Knowledge Base With Openclaw
両方が必要なケース
実際のワークフローの多くは両方を必要とします。それぞれが異なる役割を果たすからです。
クライアントプロジェクトで作業する開発者エージェントを考えてみましょう。
- RAG ナレッジベース: コードベース、API ドキュメント、社内スタイルガイドなど、エージェントが何かを調べるときにクエリする参照資料
- 永続ワークスペース: プロジェクト履歴――何が構築されたか、どんな判断が下されたか、今スプリントで何が進行中か
ナレッジベースは「この API エンドポイントは何をするのか?」に答えます。ワークスペースは「先週の火曜日にどこまで進んで、認証フローについて何を決めたか?」に答えます。
この 2 つは補完関係にあり、競合するものではありません。
MemClaw はプロジェクトメモリ(ワークスペース)に特化しています。RAG システムと併用することで、参照資料の検索とプロジェクト状態の管理を両立できます。詳しくは memclaw.me をご覧ください。
マルチプロジェクト問題:RAG の限界
実務上、この区別が最も重要になるのがここです。
AI エージェントで複数のプロジェクトを運用している場合、共有 RAG ナレッジベースにはコンテキストの混入という問題が生じます。クライアント A のドキュメントとクライアント B のドキュメントが同じベクトルストアに入っています。エージェントは両方からチャンクを取得します。あるプロジェクトの判断が別のプロジェクトに表面化します。
メタデータフィルタリングで解決を試みることもできます。各ドキュメントにプロジェクト ID をタグ付けし、クエリ時にフィルタリングする方法です。機能はしますが、脆弱であり、慎重なメンテナンスが必要です。
永続ワークスペースはこれを別の方法で解決します。各プロジェクトが完全に分離された環境になります。プロジェクト A のワークスペースを読み込めば、エージェントにはプロジェクト A のコンテキストだけが渡されます。分離が構造的であるため、フィルタリングは不要です。
ただし、永続ワークスペースにも限界はあります。大規模な参照資料の検索には向いていませんし、プロジェクトをまたいだ横断的な情報検索が必要な場合は RAG の方が適しています。あくまで、マルチプロジェクトの文脈分離という課題においては、プロジェクトスコープのワークスペースが共有ナレッジベースよりも効果的に機能するということです。
Managing Multiple Projects With Openclaw
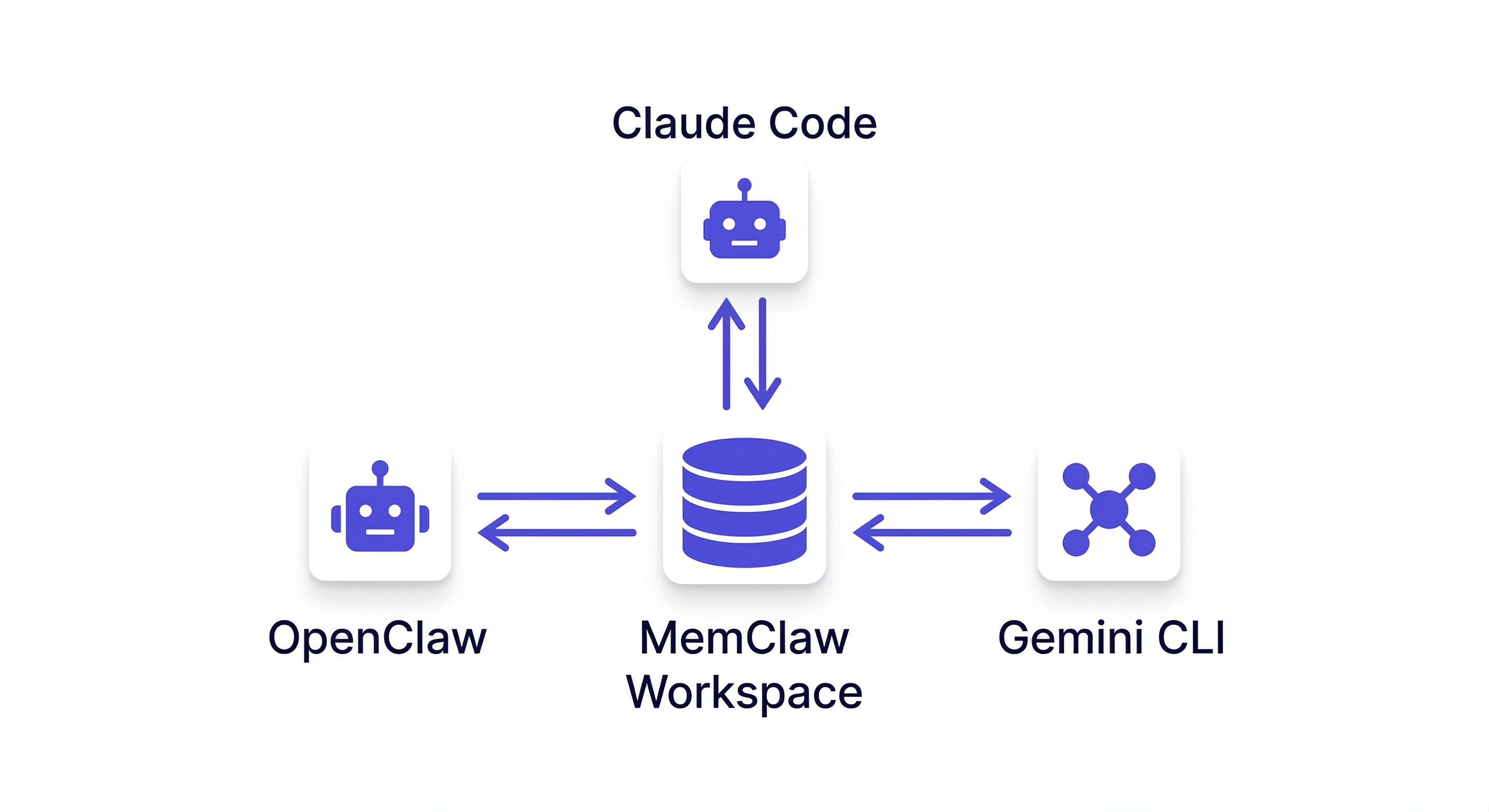
MemClaw が OpenClaw 向けに永続ワークスペースを実装する方法
MemClaw は永続ワークスペースのユースケースに特化して構築されています。複数のプロジェクトを管理する OpenClaw および Claude Code ユーザーのためのプロジェクト継続性ツールです。
各ワークスペースには以下が格納されます。
- Living README — 背景コンテキスト、設定、現在の進捗、重要な判断
- Artifacts — プロジェクト中に作成されたドキュメント、レポート、URL、ファイル
- Tasks — エージェントの作業に合わせて自動追跡
- Decision log — アーキテクチャ上の選択、合意されたアプローチ、解決済みの論点
エージェントはセッション開始時にこれを読み込み(8 秒でコンテキスト復元)、作業の進行に合わせて書き戻します。手動メンテナンスは不要です。毎回のブリーフィングも不要です。
なお、MemClaw はプロジェクトメモリに特化しているため、大量のドキュメント検索や RAG 的な用途には対応していません。その場合は専用の RAG システムとの併用をおすすめします。
インストール方法:
/plugin marketplace add Felo-Inc/memclaw
/plugin install memclaw@memclaw
API キーを設定します。
export FELO_API_KEY="your-api-key-here"
API キーは felo.ai/settings/api-keys で取得できます。
プロジェクトごとにワークスペースを作成します。
Create a workspace called Project Alpha
セットアップは以上です。JSON 設定ファイルも、ベクトルデータベースも、エンベディングパイプラインも不要です。
適切なアーキテクチャの選び方
判断のためのフレームワークを整理します。
RAG ナレッジベースを選ぶべき場合:
- 検索対象となる大規模なドキュメントコーパスがある
- エージェントがオンデマンドで事実ベースの参照資料を必要とする
- 複数のエージェントやユーザーが同じ情報を共有する
永続ワークスペースを選ぶべき場合:
- 特定のプロジェクトを複数セッションにわたって進めている
- 前回の作業内容をエージェントに覚えておいてほしい
- 複数のプロジェクトを管理しており、分離が必要
両方を使うべき場合:
- エージェントがクエリすべき参照資料がある(RAG)
- かつ、複数セッションにまたがる進行中のプロジェクトがある(ワークスペース)
本格的な AI エージェントワークフローでは、最終的に両方が必要になるケースがほとんどです。片方でもう片方の役割を代替しようとすることが、よくある失敗パターンです。
「コンテキストウィンドウを大きくすれば解決する」が通用しない理由
メモリの問題に対するよくある反応は、「すべてをコンテキストウィンドウに入れればいい」というものです。ロングコンテキストモデルの登場で、これは実現可能に見えます。しかし、いくつかの理由でスケールしません。
コスト: プロジェクト履歴とドキュメントをすべて毎セッションのコンテキストに読み込むのは高コストです。その大部分は現在のタスクに関係ありません。
ノイズ: 関連性の低い情報で埋め尽くされた大きなコンテキストウィンドウは、回答品質を低下させます。モデルはコンテキスト内のすべてに注意を向けます。今関係のないものも含めてです。
マルチプロジェクトの分離: 共有コンテキストウィンドウではプロジェクト間の分離ができません。すべてが同時に見える状態になり、まさにコンテキスト混入の問題そのものです。
運用メモリ vs 参照メモリ: コンテキストが無制限であっても、参照資料(クエリするドキュメント)と運用メモリ(維持すべきプロジェクト状態)を区別する必要があります。目的が異なるため、異なるアーキテクチャが有効です。
永続ワークスペースは、コンテキストウィンドウの制限に対する回避策ではありません。コンテキストウィンドウのサイズに関係なく、運用的なプロジェクトメモリに適したアーキテクチャです。
実践例:同じエージェント、2 つの異なるメモリニーズ
SaaS 製品のローンチを管理するために OpenClaw を使うプロダクトマネージャーを考えてみましょう。
彼女には 2 つの異なるメモリニーズが同時に存在します。
ニーズ 1:参照資料 エージェントは製品仕様書、競合調査、ユーザーインタビューの書き起こし、エンジニアリングチームの技術的制約にアクセスする必要があります。これは参照資料です。大規模で比較的安定しており、オンデマンドでクエリされます。
RAG ナレッジベースがこれをうまく処理します。ドキュメントをインデックス化すれば、「オンボーディングフローについてユーザーは何と言っていたか?」や「通知システムの技術的制約は何か?」といった質問にエージェントが関連セクションを取得して回答できます。
ニーズ 2:プロジェクトメモリ エージェントは、ローンチ日が 3 月から 4 月に変更されたこと、料金チームが当初のフリーミアム階層の決定を覆したこと、Salesforce 連携が v2 に先送りされたこと、前回のセッションがメールキャンペーンのコピー作成途中で終わったことを知っている必要があります。
RAG ナレッジベースはこれをうまく処理できません。これらは取得すべきドキュメントではなく、特定のプロジェクトの現在の状態に関する運用上の事実です。頻繁に変わります。類似性検索で取得するのではなく、セッション開始時にまるごと読み込む必要があります。
永続ワークスペースがこれをうまく処理します。
彼女は最終的に両方を使うことになります。ドキュメントコーパスには RAG システム、プロジェクト状態には MemClaw。それぞれが設計された目的を果たします。
よくある質問
MemClaw を RAG システムと併用できますか? はい。MemClaw はプロジェクトメモリ(ワークスペース)を担当します。RAG システムはドキュメント検索を担当します。それぞれ独立して動作し、互いを補完します。
MemClaw はベクトルエンベディングを使用していますか? いいえ。MemClaw は構造化されたプロジェクトコンテキスト(判断、ステータス、成果物)を格納します。ドキュメントエンベディングではありません。検索システムではなく、プロジェクトメモリシステムです。
プロジェクトに参照ドキュメントと進行中の作業の両方がある場合は? 両方を使いましょう。参照ドキュメントは RAG システムに格納し、プロジェクト履歴と判断は MemClaw ワークスペースに格納します。それぞれが設計された目的を果たします。
MemClaw は OpenClaw だけでなく Claude Code でも動作しますか? はい。MemClaw は OpenClaw、Claude Code、Gemini CLI、Codex に対応しており、すべて同じワークスペースを共有できます。