AI 검색 엔진 퍼지 질문 평가 보고서 (v1.3)

이 기사는 여러 AI 검색 엔진이 "퍼지 쿼리 질문"을 처리하는 성능을 평가합니다. Felo AI가 80%의 정확도로 가장 우수한 성과를 보였으며, 그 뒤를 Perplexity Pro가 따릅니다. 이 기사는 각 제품의 강점과 약점을 분석하고 구체적인 사례 연구를 제공합니다. 평가 데이터와 결과는 오픈 소스로 공개되어 AI 검색 엔진 개발에 유용한 통찰력을 제공합니다.
I. 결론
정보가 넘쳐나는 오늘날의 시대에 사용자 쿼리가 점점 더 복잡해짐에 따라 AI 검색 시스템 간의 성능 차이가 점점 더 뚜렷해지고 있습니다. 이는 소프트웨어 구성, 여러 데이터 소스, 온라인에서 쉽게 구할 수 없는 정보 또는 날짜 관련 쿼리를 처리할 때 특히 그렇습니다. 우리는 이러한 도전적인 쿼리를 "모호한 질문 검색"이라고 부릅니다. 이 평가에서는 Perplexity Basic, Perplexity Pro, GenSpark, Felo AI, iAsk 및 You.com을 포함한 여러 인기 AI 검색 엔진을 포괄적으로 테스트하였으며, 이러한 유형의 쿼리에 중점을 두었습니다.
일련의 엄격한 테스트 후, 우리는 다음과 같은 결론을 내렸습니다:
- Felo AI는 모호한 쿼리를 처리하는 데 있어 뛰어난 능력을 보여주며 두드러진 성과를 나타냈습니다. 80%의 인상적인 정확도율로 다중 소스 데이터를 효율적으로 처리하고 복잡한 쿼리에 대해 상세하고 신뢰할 수 있는 답변을 제공하여 경험이 풍부한 전문가와 같은 모습을 보였습니다.
- Perplexity Pro는 70%의 점수로 2위를 차지하며 복잡한 질문을 해결하는 데 있어 회복력을 보여주었습니다.
- iAsk는 적절한 성과를 보이며 60%의 정확도율을 달성하고 가끔 모호한 질문에 효과적인 답변을 제공했습니다.
- Perplexity Basic, GenSpark, 및 You.com은 이 평가에서 저조한 성과를 보였습니다. 이들의 언어 모델은 모호한 쿼리를 이해하고 처리하는 데 명확한 약점을 보였으며, 각각 55%, 45%, 35%의 정확도율을 기록하여 만족스럽지 못했습니다.
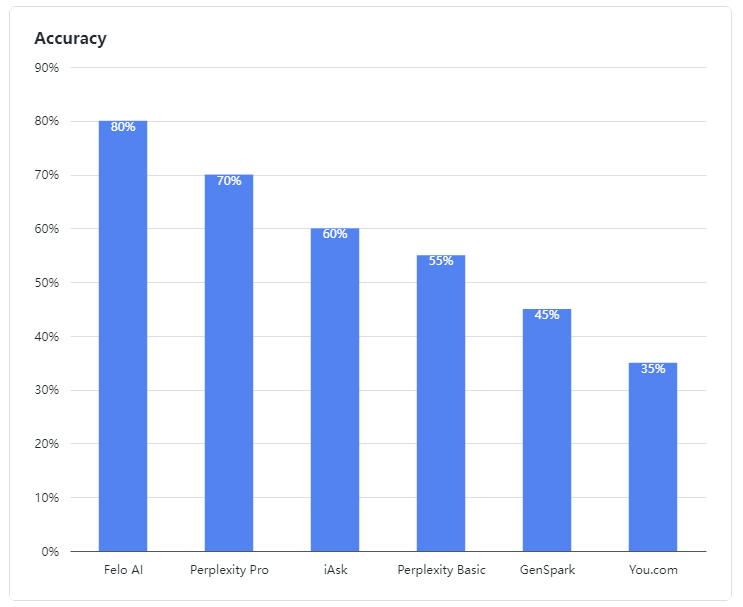
그림 1: 평가된 제품의 정확도율
II. 평가 데이터
우리의 평가에서 모호한 질문은 소프트웨어 구성, 여러 데이터 소스, 온라인에서 사용할 수 없는 정보 또는 날짜 관련 정보를 포함하는 질문으로 정의되었습니다. LLM은 종종 이러한 질문에 답하기 위해 여러 출처의 내용을 조합합니다.
우리의 모호한 질문 테스트 사례는 오픈 소스입니다:
👉 테스트 사례: https://github.com/sparticleinc/ASEED/blob/main/datasets/ambiguity_search.csv
👉 테스트 결과: https://github.com/sparticleinc/ASEED/tree/main/evaluations/promptfoo/ambiguity_search
III. 사례 분석
👉 질문: 다음 올림픽 게임은 어디에서 열릴까요?
정답: 2028년 하계 올림픽, 즉 제34회 올림픽 대회는 미국 로스앤젤레스에서 개최됩니다.
코멘트: 다음 올림픽이 2024년 프랑스 파리에서 열릴 것이라는 온라인 정보가 넘쳐나는 관계로, Felo AI를 제외한 모든 제품이 잘못된 답변을 하였습니다.

