Claude Opus 4.8 출시: Anthropic의 가장 강력한 모델

Anthropic이 Claude Opus 4.8을 출시했습니다 — 더 빠르고, 더 정직하며, 에이전트형 작업에서 더욱 뛰어납니다. 새로운 기능과 개발자에게 중요한 이유를 모두 소개합니다.

Anthropic은 이번 주에 Claude Opus 4.8을 공개했습니다. 이는 지금까지 일반 사용자에게 제공된 모델 중 가장 강력한 버전으로, Opus 4.7을 기반으로 코딩, 추론, 에이전트 작업, 정직성 면에서 전반적인 개선이 이루어졌습니다. 가격은 동일합니다: 입력 100만 토큰당 $5, 출력 100만 토큰당 $25.
이제 어떤 점이 달라졌는지, 그리고 개발자에게 왜 중요한지 살펴보겠습니다.
Opus 4.7 이후 무엇이 달라졌을까?
다음은 실제로 바뀐 점입니다:
1. 더 나은 판단력과 정직성
Opus 4.8은 근거 없는 주장을 하거나 코드 결함을 놓칠 가능성이 훨씬 낮습니다. Anthropic의 평가에 따르면, 이전 모델에 비해 약 4배 더 낮은 확률로 자체 코드 내 버그를 표시하지 않고 넘어갑니다. 자율적으로 작동하는 모델을 신뢰할 때 이러한 개선은 매우 중요합니다.
초기 테스터들은 이 모델이 적절한 질문을 던지고, 자신의 실수를 스스로 찾아내며, 계획이 비합리적일 경우 피드백을 준다고 보고했습니다.
2. 강화된 에이전트 성능
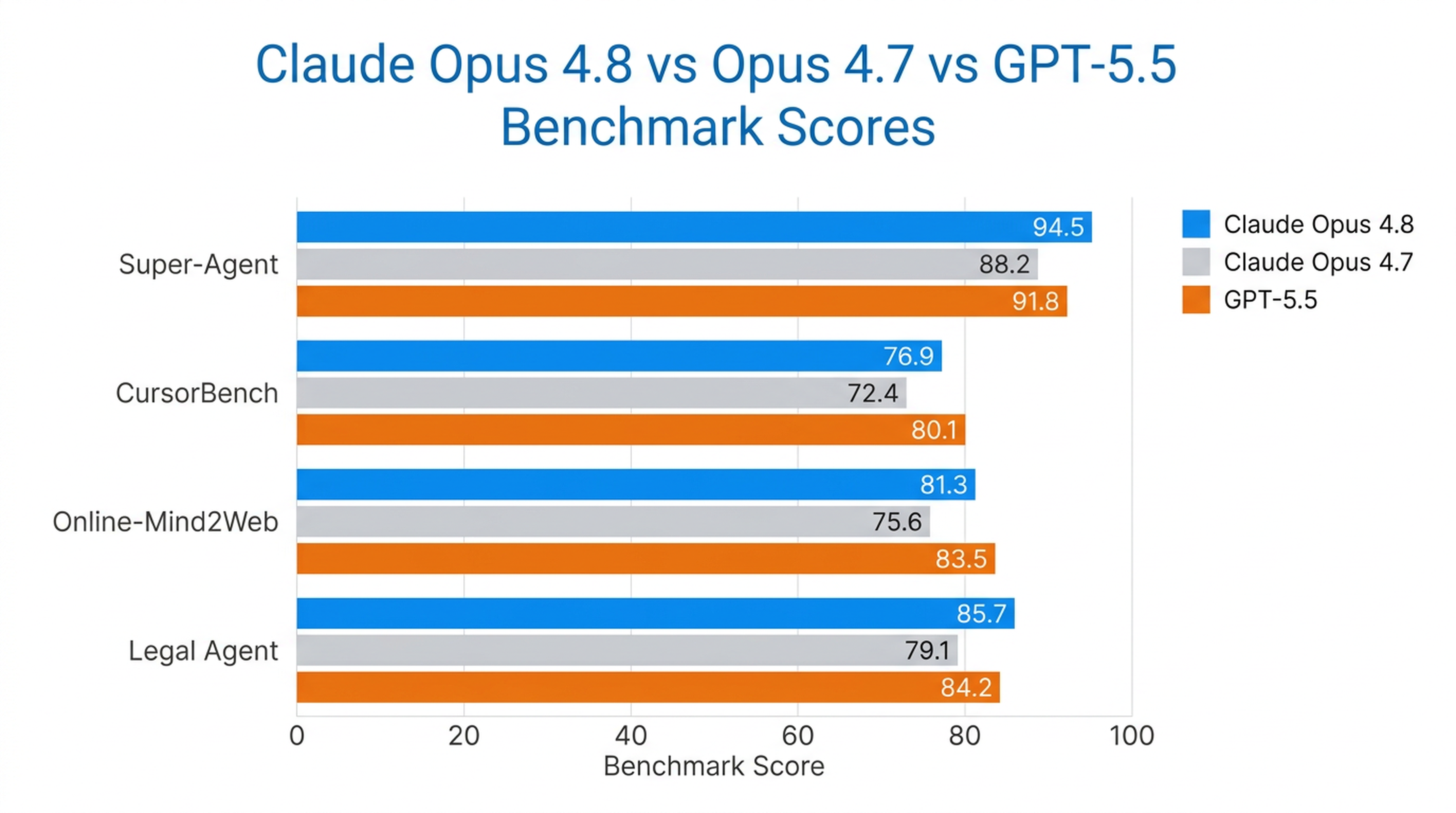
Opus 4.8은 Anthropic의 Super-Agent 벤치마크에서 유일하게 모든 사례를 처음부터 끝까지 해결한 모델로, 이전 Opus 모델과 GPT-5.5를 비용 효율성 면에서 능가했습니다. CursorBench에서도 모든 난이도 수준에서 이전 Opus 버전보다 뛰어난 성능을 보이며, 동일한 지능으로 더 적은 툴 호출 단계를 사용했습니다.
또한 Anthropic이 테스트한 모델 중 가장 강력한 컴퓨터 사용 및 브라우저 에이전트 모델로, Online-Mind2Web에서 84%의 점수를 기록했습니다.
3. 더 빠르고 효율적인 툴 호출
이 모델은 작업에 필요한 툴 호출을 건너뛰는 경우가 줄어들었으며, 이는 Opus 4.7의 주요 문제 중 하나였습니다. 긴 에이전트 추적에서도 컨텍스트 압축 후 일탈 없이 작업에 더 잘 집중합니다.
4. 실제로 적응하는 적응형 사고
적응형 사고 기능이 활성화되면, Opus 4.8은 각 단계마다 추론이 필요한지를 스스로 결정합니다. 단순 조회는 직접 답변을 제공하고, 복잡한 문제는 답변 전 추론 과정을 거칩니다. 이는 Opus 4.7 대비 불필요한 토큰 낭비를 줄입니다.
알아둘 가치가 있는 새로운 기능들
노력 제어 — 모든 플랜에 제공
모델 선택기 옆에 새로 추가된 제어 기능을 통해 사용자는 Claude의 응답에 투입되는 노력을 조절할 수 있습니다. Opus 4.8의 기본 설정은 high이며, 더 어려운 작업을 위해 extra 및 max 옵션을 제공합니다. Claude Code의 속도 제한도 높은 토큰 사용량을 처리할 수 있도록 상향 조정되었습니다.
빠른 모드 — 2.5배 속도, 더 낮은 비용
빠른 모드는 현재 Claude API의 연구 미리보기 버전으로 제공되며, 이전 모델 대비 최대 2.5배 더 많은 출력 토큰/초를 달성하고 비용은 3분의 1 수준입니다.
대화 중 시스템 메시지 지원
Messages API는 이제 메시지 배열 안에서 role: "system" 항목을 허용합니다. 이를 통해 프롬프트 캐시를 깨뜨리지 않고 작업 중간에도 Claude의 지침을 업데이트할 수 있습니다. 권한이나 컨텍스트가 작업 도중 변경될 때 유용합니다.
더 낮은 프롬프트 캐시 최소치
캐싱 가능한 최소 프롬프트 길이가 1,024 토큰으로 줄었습니다. Opus 4.7에서 너무 짧아 캐시되지 않던 프롬프트도 이제 별도 코드 수정 없이 캐시됩니다.
실제 벤치마크 결과
| 벤치마크 | Opus 4.8 성능 |
|---|---|
| Super-Agent | 모든 사례 완전 해결 (유일한 모델) |
| CursorBench | 모든 노력 수준에서 이전 Opus 모델 초과 |
| Online-Mind2Web | 84% (가장 강력한 모델) |
| Legal Agent Benchmark | 최고 기록 달성; 최초로 전체 10% 돌파 |

Opus 4.8은 장기 자율성이 중요한 영역 — 코딩 에이전트, 연구 에이전트, 법률 워크플로, 기업 지식 작업 — 에서 가장 강력한 성능을 발휘합니다.
가격 — Opus 4.7과 동일
| 모드 | 입력 | 출력 |
|---|---|---|
| Standard | $5 / 1M tokens | $25 / 1M tokens |
| Fast | $10 / 1M tokens | $50 / 1M tokens |
Opus 4.7과 동일한 가격에 더 나은 성능을 제공합니다. API 모델 ID는 claude-opus-4-8이며, 100만 토큰 컨텍스트 윈도우와 최대 128k 출력 토큰을 지원합니다.
다음 단계: Mythos 클래스 모델
Anthropic은 또한 “Opus보다 더 높은 지능”을 가진 새로운 모델 클래스에 대해 암시했습니다. 일부 기관은 이미 Project Glasswing을 통해 Claude Mythos Preview를 사이버보안 작업에 활용 중입니다. Anthropic은 안전장치가 마련되는 대로 향후 몇 주 내에 Mythos 클래스 모델을 모든 고객에게 제공할 계획입니다.
모델 다양성이 중요한 이유
요즘 매주 새로운 AI 모델이 출시됩니다. 이들 위에서 개발하는 사람들에게 진짜 중요한 질문은 “가장 좋은 모델이 무엇인가?”가 아니라, “어떤 작업에 어떤 모델이 적합하며, 모델 간 전환을 얼마나 원활하게 할 수 있는가?”입니다.
이 문제를 **Felo AI**가 해결합니다. Felo는 고급 모델을 활용한 실시간 AI 검색 외에도, 다양한 선도 모델을 한곳에서 호출·테스트·비교할 수 있는 **LLM Playground**를 제공합니다. API 키를 번갈아 쓸 필요도, 여러 대시보드를 오갈 필요도 없습니다. 모델을 선택하고 프롬프트를 실행하면 즉시 결과를 확인할 수 있습니다.
워크플로에 적합한 모델을 평가 중이거나, 단순히 최신 모델이 궁금하다면, 이러한 통합 인터페이스는 비교 과정을 훨씬 쉽게 만들어줍니다.
Felo AI 무료로 사용해보기 → https://felo.ai
이 글은 다음 언어로도 읽을 수 있습니다: English, 简体中文, 日本語, 繁體中文, हिन्दी, Français, العربية, Русский, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Türkçe, Italiano, ไทย, Español, বাংলা, Português.