2026년 텍스트-투-비디오 AI: 모든 도구와 혁신을 아우르는 완벽한 뉴스 가이드

OpenAI Sora부터 Google Veo, Runway Gen-3, Kling까지, 그리고 Felo Video가 근본적으로 다른 접근 방식을 취하는 이유까지 — 2026년 텍스트-투-비디오 AI 생태계를 종합 정리합니다.
올해 AI 뉴스를 꾸준히 팔로우해 왔다면, 하나 분명한 점을 느꼈을 겁니다. 텍스트-투-비디오 분야는 불과 1년 만에 “유망하다”에서 “혼잡하다”로 바뀌었습니다.
OpenAI의 Sora가 마침내 일반 공개되었고, Google은 영화 수준의 품질을 자랑하는 Veo 3을 출시해 인터넷을 떠들썩하게 만들었습니다. Runway는 계속해서 Gen-3 업데이트를 내놓고 있으며, Kling, Luma Dream Machine, Pika 등 수많은 서비스가 경쟁에 뛰어들었습니다.
이제 질문은 “AI가 비디오를 만들 수 있을까?”에서
“어떤 도구를 실제로 사용해야 할까?”로 바뀌었습니다.
그리고 아직 아무도 묻지 않은 세 번째 질문이 있습니다:
우리는 정말로 올바른 종류의 텍스트-투-비디오 도구를 사용하고 있을까?

2026년 텍스트-투-비디오 AI 생태계
현재 상황을 살펴봅시다.
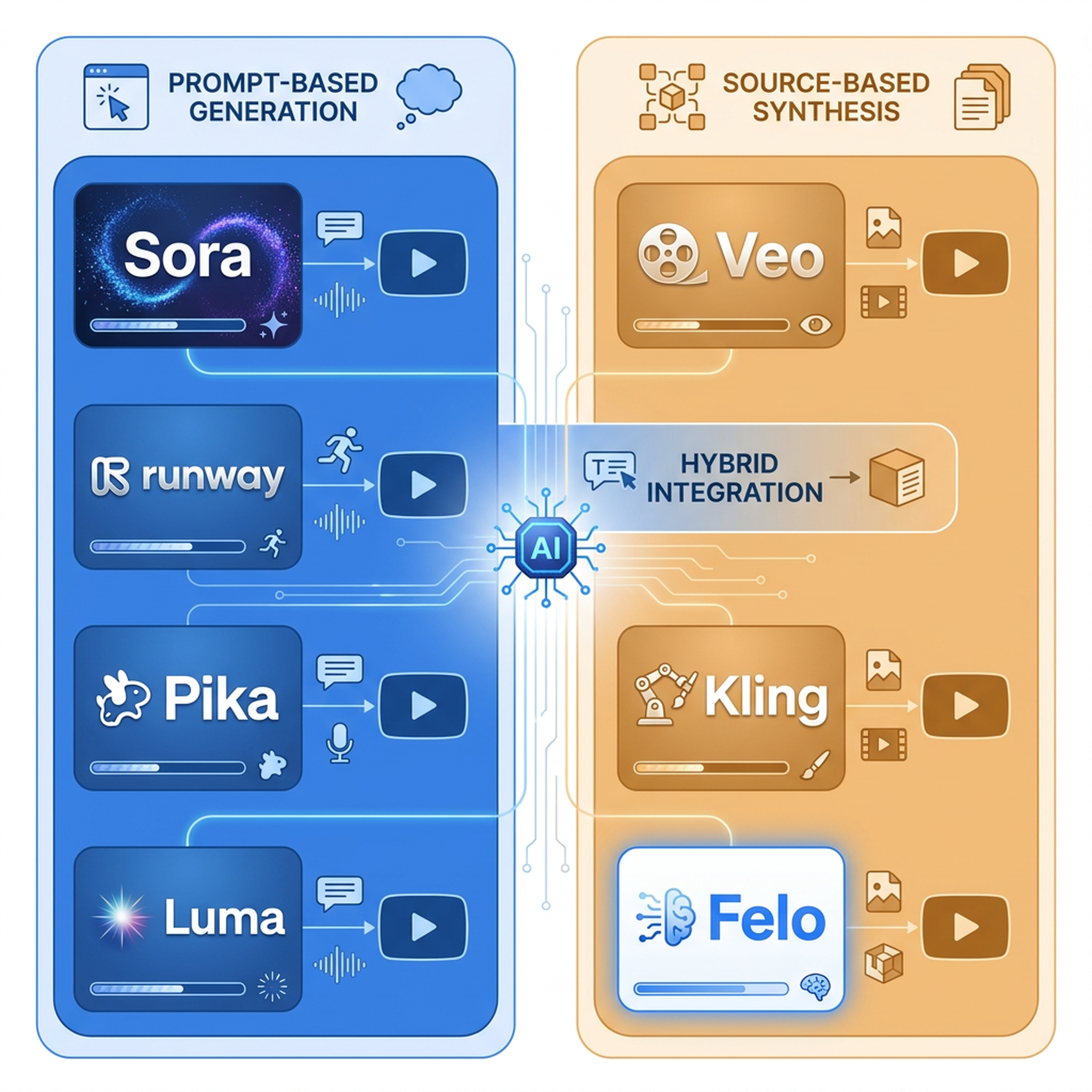
OpenAI Sora
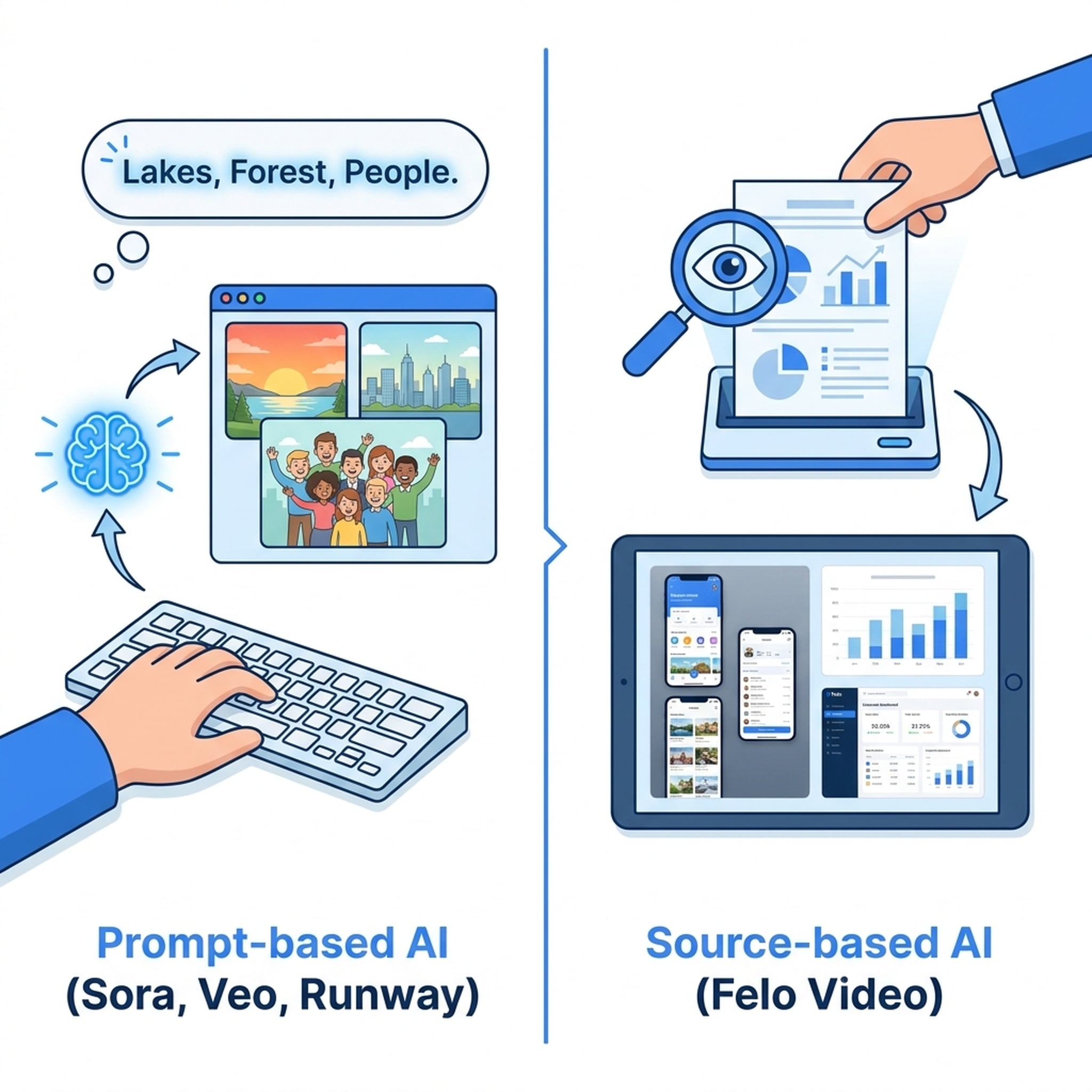
Sora는 현재의 열풍을 시작한 도구입니다. 몇 달간의 클로즈 베타 이후, OpenAI는 계층형 가격제와 함께 Sora를 공개했습니다. 품질은 의심할 여지가 없습니다 — 사실적인 장면, 일관된 캐릭터, 대부분 자연스러운 물리효과까지. 그러나 Sora는 한 가지 목적만을 위해 만들어졌습니다: 텍스트 설명으로부터 영화 같은 영상을 생성하는 것. 예를 들어 “해질녘 들판을 달리는 골든 리트리버”를 입력하면 그대로 영상을 얻습니다.
하지만 얻지 못하는 것도 있습니다. 바로 제품 홍보 영상, 보고서 영상, 블로그 콘텐츠 영상입니다. Sora는 사용자의 콘텐츠를 ‘이해하지’ 않습니다. 단지 프롬프트로 장면을 생성할 뿐입니다.
Google Veo 3
Google의 Veo 3은 한 단계 기준을 끌어올렸습니다. 오디오 생성이 통합되어 영상이 사실적으로 보일 뿐 아니라, 실제처럼 들립니다. 영화 수준의 품질은 업계 최고 수준이라 할 수 있습니다. Sora와 마찬가지로 Veo도 프롬프트 기반입니다 — 장면을 설명하면 영상을 생성합니다. Google 생태계와의 통합으로 YouTube나 Google Workspace와 연계된 워크플로우도 가능하지만, 핵심 원리는 동일합니다 — 프롬프트 입력, 영화형 출력.
Runway Gen-3 Alpha
Runway는 현재 열풍 이전부터 AI 비디오 분야의 실질적인 중심이었습니다. Gen-3 Alpha는 동작 품질이 뛰어나고, 프롬프트 반응성이 좋으며, 이미지-투-비디오 및 비디오-투-비디오 편집을 포함하는 풍부한 툴킷을 제공합니다. 창작 전문가들이 가장 먼저 찾는 도구이기도 합니다. 그러나 여전히 생성형 AI 도구입니다. 원하는 장면을 설명하면, 그 내용을 생성할 뿐입니다. 실제 콘텐츠는 방정식에 포함되지 않습니다.
Kling AI
Kling은 중국에서 등장해 놀라운 동작 품질과 무료 요금제로 빠르게 인기를 끌었습니다. 결과물은 시각적으로 강력하며 특히 캐릭터 애니메이션과 복잡한 동작에서 두드러집니다. 하지만 다른 도구들과 마찬가지로 프롬프트 기반입니다 — 설명, 생성, 반복.
Luma Dream Machine
Luma의 Dream Machine은 빠른 생성 속도와 접근 가능한 가격대에서 괜찮은 품질로 자신만의 틈새 시장을 확보했습니다. 여러 프롬프트를 빠르게 테스트해야 하는 경우 속도는 매우 중요합니다. 이 역시 프롬프트를 입력해 영상을 생성하는 모델입니다.
Pika
Pika는 창의적 통제에 초점을 맞춥니다 — 스타일 변환, 모션 브러시, 특정 영역 편집 등. 생성형 도구 중에서도 가장 “편집기 같은” 인터페이스를 제공해 세부 조정이 가능합니다. 하지만 근본적으로는 여전히 생성형 도구입니다. 콘텐츠를 ‘이해’하지는 않습니다.
아무도 이야기하지 않는 문제
2026년의 주요 텍스트-투-비디오 AI 도구들은 모두 같은 모델을 따릅니다:
프롬프트 → 생성형 비디오
사용자가 원하는 모습을 설명하면, AI가 ‘상상’해 만듭니다.
결과물은 시각적으로 멋지지만, 모두 ‘창작된’ 것입니다.
이 방식은 창의적인 장면, 감성 표현, 시네마틱 샷에는 훌륭합니다.
하지만 실제로 사람들이 필요로 하는 영상 작업에는 맞지 않습니다:
- 게시된 글을 공유 가능한 영상으로 전환하기
- 제품 페이지를 프로모션 영상으로 바꾸기
- 월간 보고서를 브리핑 영상으로 전환하기
- 교육용 슬라이드를 강의 영상으로 바꾸기
- 기술 문서를 설명 영상으로 변환하기
이런 용도에서 병목은 시각 생성이 아닙니다.
병목은 원본 콘텐츠의 이해입니다 — 글, 보고서, 제품 페이지, 슬라이드 등을 그대로 유지하면서 실제 정보, 그래프, 스크린샷을 포함한 영상을 만들어내는 것입니다.
이 바로 다음 텍스트-투-비디오 논의가 나아가야 할 방향입니다.
다른 접근법: 프롬프트가 아닌 콘텐츠에서 시작하기
Felo Video는 텍스트-투-비디오를 근본적으로 다르게 접근합니다.
사용자에게 원하는 영상을 설명하라고 요구하는 대신, 실제 콘텐츠를 읽고 그로부터 영상을 생성합니다.
차이는 구조적입니다:
| 기존 텍스트-투-비디오 AI | 원본 기반 비디오 AI | |
|---|---|---|
| 입력 | 장면을 설명하는 텍스트 프롬프트 | 실제 콘텐츠: 글, 보고서, 슬라이드, 웹페이지 |
| 과정 | AI가 허구의 비주얼을 생성 | AI가 사용자의 자료를 이해하고 추출 |
| 비주얼 | AI 생성, 흔히 스톡 이미지 유사 | 실제 스크린샷, 차트, 다이어그램, 제품 UI |
| 용도 | 창의적 장면, 분위기 영상 | 비즈니스 콘텐츠, 교육, 마케팅, 문서화 |
| 출력 | 영화적이지만 일반적 | 사용자의 콘텐츠와 브랜드에 특화 |
이것은 Sora나 Veo를 대체하겠다는 이야기가 아닙니다. 그들은 다른 문제를 해결하고 있습니다. 하지만 기존 콘텐츠를 영상으로 전환하려는 목적이라면, 프롬프트 기반 모델은 애초에 적합하지 않았던 것입니다.
왜 원본 기반 비디오가 지금 중요한가
세 가지 흐름이 동시에 일어나고 있습니다.
1. 콘텐츠 과잉.
팀들은 그 어느 때보다 많은 글 콘텐츠를 제작합니다 — 블로그, 보고서, 제품 업데이트, 교육 자료. 하지만 대부분은 제작 비용 때문에 영상으로 만들지 못합니다. 원본 기반 비디오 AI가 그 격차를 메워줍니다.
2. 비디오 중심 배포.
소셜 플랫폼은 영상을 우선시합니다. LinkedIn, Twitter, TikTok, YouTube — 영상 콘텐츠는 더 넓은 도달 범위와 높은 참여율, 공유율을 얻습니다. 영상으로 바꾸면 더 효과적일 콘텐츠가 여전히 페이지 속에 머물러 있습니다.
3. 다국어 수요.
글로벌 팀은 다국어 콘텐츠를 필요로 합니다. 영상 번역은 전체 제작 과정을 다시 해야 하지만, 원본 기반 비디오는 동일한 구조의 영상을 자동으로 다른 내레이션과 자막으로 생성할 수 있습니다.
실제로 도움이 되는 텍스트-투-비디오 비교
2026년에 텍스트-투-비디오 AI 도구를 평가할 때, 올바른 질문은
“어떤 도구가 가장 멋진 비주얼을 만들까?”가 아닙니다.
바로 “나는 무엇을 만들려는가?”입니다.
시네마틱 장면이 필요하다면 — 제품 콘셉트, 무드 영상, 크리에이티브 샷 등에서는 Sora, Veo 3, Runway Gen-3가 최적입니다. 그 부문에서는 이들이 최고입니다.
기존 콘텐츠를 영상으로 변환해야 한다면 — 글, 보고서, 프레젠테이션, 제품 페이지 등에는 Felo Video 같은 원본 기반 도구가 필요합니다. 생성형 도구는 콘텐츠를 읽지 않기 때문에 이 작업은 불가능합니다.
Felo Video가 다르게 하는 일
Felo Video는 프롬프트를 요구하지 않습니다. 대신 여러분의 콘텐츠를 입력받습니다:
- URL 붙여넣기 — 블로그 글, 제품 페이지, 기사
- 파일 업로드 — PDF 보고서, PPT 프레젠테이션, Keynote 자료
- 텍스트 입력 — 출시 노트, 대본, 소셜 게시글
Felo Video는 이를 읽고, 맥락을 이해하며, 핵심 포인트를 추출합니다. 그리고 실제 자산 — 스크린샷, 차트, 제품 UI, 다이어그램 —을 활용해 영상을 생성합니다. 내레이션, 자막, 모션, 음악은 모두 자동 생성되지만, 콘텐츠는 전적으로 사용자로부터 나옵니다.
초안은 10~20분 내에 생성됩니다. 이후 검토하고, 수정하고, 내보내면 됩니다.
결론
2026년의 텍스트-투-비디오 AI 분야는 인상적입니다.
생성형 도구들은 나날이 발전하고 있습니다.
하지만 프롬프트 기반 AI가 결코 해결하도록 설계되지 않았던 한 가지 영역이 있습니다 —
바로 기존의 가치 있고 정보가 풍부한 콘텐츠를 영상 형식으로 전환하는 것입니다.
그 공백을 채우는 것이 바로 Felo Video입니다.
Sora와 영화적 품질로 경쟁하는 대신,
Sora, Veo, Runway, Kling이 다루지 않는 문제를 해결함으로써 말이죠.
여러분의 콘텐츠는 이미 존재합니다.
이제 영상이 될 차례입니다.
이 글은 다음 언어로도 읽을 수 있습니다: English, 简体中文, 日本語, 繁體中文, हिन्दी, Français, العربية, Русский, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Türkçe, Italiano, ไทย, Español, বাংলা, Português.