Relatório de Avaliação de Perguntas Fuzzy de Motores de Busca de IA (v1.3)

Este artigo avalia o desempenho de vários motores de busca de IA no tratamento de "perguntas de consulta fuzzy." O Felo AI teve o melhor desempenho com uma taxa de precisão de 80%, seguido pelo Perplexity Pro. O artigo analisa os pontos fortes e fracos de cada produto e fornece estudos de caso específicos para ilustração. Os dados e resultados da avaliação foram tornados open source, oferecendo insights valiosos para o desenvolvimento de motores de busca de IA.
I. Conclusão
Na era saturada de informações de hoje, à medida que as consultas dos usuários se tornam mais complexas, a diferença de desempenho entre os sistemas de busca de IA se torna cada vez mais evidente. Isso é especialmente verdadeiro ao lidar com configurações de software, múltiplas fontes de dados, informações não disponíveis online ou consultas relacionadas a datas. Nos referimos a essas consultas desafiadoras como "buscas de perguntas ambíguas." Nesta avaliação, testamos de forma abrangente vários motores de busca de IA populares, incluindo Perplexity Basic, Perplexity Pro, GenSpark, Felo AI, iAsk e You.com, focando nesse tipo de consulta.
Após uma série de testes rigorosos, concluímos:
- Felo AI destacou-se como o melhor desempenho, demonstrando uma habilidade excepcional em lidar com consultas ambíguas. Ele liderou o grupo com uma impressionante taxa de precisão de 80%, processando eficientemente dados de múltiplas fontes e fornecendo respostas detalhadas e confiáveis para consultas complexas, muito parecido com um especialista experiente.
- Perplexity Pro garantiu o segundo lugar com uma pontuação de 70%, mostrando resiliência ao enfrentar algumas perguntas complexas.
- iAsk teve um desempenho adequado, alcançando uma taxa de precisão de 60% e ocasionalmente fornecendo respostas eficazes para perguntas ambíguas.
- Perplexity Basic, GenSpark, e You.com tiveram um desempenho abaixo do esperado nesta avaliação. Seus modelos de linguagem mostraram fraquezas claras na compreensão e processamento de consultas ambíguas, alcançando taxas de precisão de 55%, 45% e 35%, respectivamente, o que foi menos do que satisfatório.
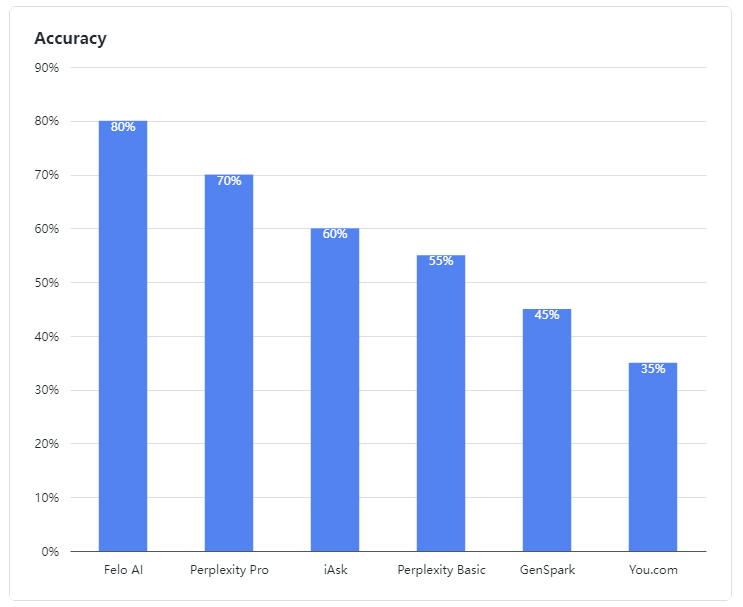
Figura 1: Taxas de precisão dos produtos avaliados
II. Dados da Avaliação
Em nossa avaliação, perguntas ambíguas foram definidas como aquelas que envolvem configurações de software, múltiplas fontes de dados, informações não disponíveis online ou informações relacionadas a datas. Os LLMs frequentemente juntam conteúdo de múltiplas fontes para responder a tais perguntas.
Nossos casos de teste de perguntas ambíguas são de código aberto:
👉 Casos de teste: https://github.com/sparticleinc/ASEED/blob/main/datasets/ambiguity_search.csv
👉 Resultados dos testes: https://github.com/sparticleinc/ASEED/tree/main/evaluations/promptfoo/ambiguity_search
III. Análise de Caso
👉 Pergunta: Onde serão realizados os próximos Jogos Olímpicos?
Verdade fundamental: Os Jogos Olímpicos de Verão de 2028, também conhecidos como Jogos da XXXIV Olimpíada, serão realizados em Los Angeles, EUA.
Comentário: Devido à abundância de informações online afirmando que os próximos Jogos Olímpicos serão realizados em Paris, França, em 2024, todos os produtos, exceto o Felo AI, responderam incorretamente.

