Claude Opus 4.8 Lançado: O Modelo Mais Capaz da Anthropic Até Agora

A Anthropic acabou de lançar o Claude Opus 4.8 — mais rápido, mais honesto e melhor em tarefas agenticas. Veja tudo o que há de novo e por que isso é importante para os desenvolvedores.

A Anthropic lançou Claude Opus 4.8 esta semana. É o modelo mais capaz que eles disponibilizaram publicamente, construído sobre o Opus 4.7 com melhorias em codificação, raciocínio, tarefas agenticas e honestidade. O preço permanece o mesmo: US$ 5 por milhão de tokens de entrada e US$ 25 por milhão de tokens de saída.
Veja o que mudou e por que isso é importante para desenvolvedores que constroem sobre ele.
O Que Mudou Desde o Opus 4.7?
Veja o que realmente mudou:
1. Melhor Julgamento e Honestidade
O Opus 4.8 é significativamente menos propenso a fazer afirmações sem suporte ou deixar passar falhas de código sem perceber. As avaliações da Anthropic mostram que ele é cerca de quatro vezes menos propenso que seu antecessor a permitir que bugs em seu próprio código passem despercebidos. Esse é o tipo de melhoria que importa quando você confia em um modelo para trabalhar de forma autônoma.
Testadores iniciais relataram que ele faz as perguntas certas, corrige seus próprios erros e se opõe quando um plano não faz sentido.
2. Desempenho Agêntico Mais Forte
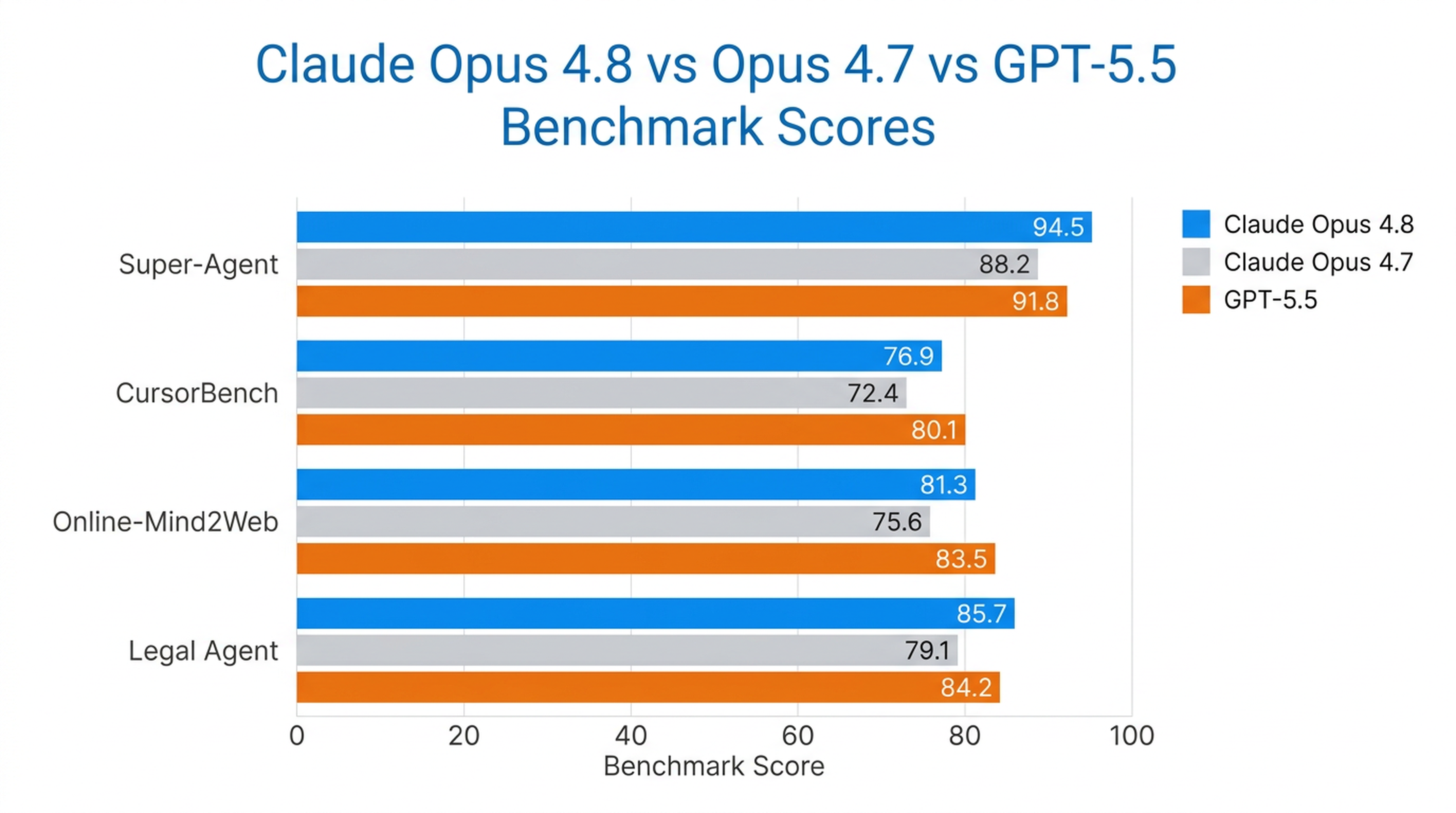
O Opus 4.8 é o único modelo a concluir todos os casos de ponta a ponta no benchmark Super-Agent da Anthropic, superando os modelos Opus anteriores e o GPT-5.5 em paridade de custo. No CursorBench, ele supera as versões anteriores do Opus em todos os níveis de esforço, usando menos chamadas de ferramentas para a mesma inteligência.
Também é o modelo mais forte em uso de computador e agente de navegador já testado pela Anthropic, alcançando 84% no Online-Mind2Web.
3. Chamadas de Ferramentas Mais Rápidas e Eficientes
O modelo é menos propenso a pular uma chamada de ferramenta necessária para uma tarefa, que era um ponto problemático conhecido no Opus 4.7. Rastreamentos longos de agentes também permanecem mais alinhados com a tarefa, com menos desvios após a compactação do contexto.
4. Pensamento Adaptativo Que Realmente Se Adapta
Com o pensamento adaptativo ativado, o Opus 4.8 decide a cada rodada se o raciocínio é necessário. Consultas simples recebem respostas diretas. Problemas complexos recebem raciocínio antes da resposta. Menos tokens desperdiçados em comparação com o Opus 4.7.
Novos Recursos Que Vale a Pena Conhecer
Controle de Esforço — Agora em Todos os Planos
Um novo controle ao lado do seletor de modelo permite que os usuários escolham quanto esforço Claude deve colocar em uma resposta. O Opus 4.8 tem como padrão o esforço high, com opções extra e max para tarefas mais difíceis. Os limites de taxa no Claude Code foram aumentados para lidar com o maior uso de tokens.
Modo Rápido — 2,5x Mais Velocidade, Menor Custo
O modo rápido agora está disponível para o Opus 4.8 como uma prévia de pesquisa na API do Claude. Ele oferece até 2,5× mais tokens de saída por segundo a um custo três vezes menor do que os modelos anteriores.
Mensagens de Sistema Durante a Conversa
A API de Mensagens agora aceita entradas role: "system" dentro do array de mensagens. Você pode atualizar as instruções do Claude no meio de uma tarefa sem quebrar o cache do prompt — útil quando permissões ou contexto mudam durante um loop agêntico.
Redução do Mínimo de Cache de Prompt
O comprimento mínimo de prompt que pode ser armazenado em cache caiu para 1.024 tokens. Prompts que eram muito curtos para serem armazenados em cache no Opus 4.7 agora criam entradas de cache sem exigir alterações de código.
Benchmarks do Mundo Real
| Benchmark | Desempenho do Opus 4.8 |
|---|---|
| Super-Agent | Todos os casos concluídos de ponta a ponta (único modelo a fazer isso) |
| CursorBench | Supera todos os modelos Opus anteriores em todos os níveis de esforço |
| Online-Mind2Web | 84% (modelo mais forte testado) |
| Benchmark de Agente Jurídico | Maior pontuação registrada; primeiro modelo a ultrapassar 10% no total |

O Opus 4.8 é mais forte onde a autonomia de longo prazo importa — agentes de codificação, agentes de pesquisa, fluxos de trabalho jurídicos e trabalhos de conhecimento corporativo.
Preços — Inalterados em Relação ao Opus 4.7
| Modo | Entrada | Saída |
|---|---|---|
| Padrão | US$ 5 / 1M tokens | US$ 25 / 1M tokens |
| Rápido | US$ 10 / 1M tokens | US$ 50 / 1M tokens |
Mesmo preço do Opus 4.7, com melhor desempenho. O ID do modelo na API é claude-opus-4-8. Ele oferece suporte à janela de contexto de 1M tokens e saída máxima de 128k tokens.
O Que Vem a Seguir: Modelos da Classe Mythos
A Anthropic também mencionou uma nova classe de modelo com “inteligência ainda maior que o Opus”. Um pequeno número de organizações já está usando o Claude Mythos Preview para trabalhos de cibersegurança através do Projeto Glasswing. A empresa planeja disponibilizar os modelos da classe Mythos para todos os clientes nas próximas semanas, assim que as proteções estiverem implementadas.
Por Que a Diversidade de Modelos Importa
Novos modelos de IA são lançados toda semana agora. Para desenvolvedores que constroem sobre eles, a verdadeira questão não é qual modelo é “o melhor” — é qual modelo é o certo para cada tarefa e como alternar entre eles sem atrito.
Esse é o problema que o Felo AI resolve. Além de sua pesquisa alimentada por IA que usa modelos avançados para respostas em tempo real, o Felo oferece um LLM Playground onde você pode chamar, testar e comparar resultados de uma ampla variedade de modelos líderes em um só lugar. Sem precisar lidar com várias chaves de API, nem alternar entre painéis. Basta escolher um modelo, executar seu prompt e ver como ele se sai.
Se você está avaliando modelos para seu fluxo de trabalho, ou apenas curioso sobre o que existe por aí, tê-los todos em uma única interface torna o processo de comparação muito menos doloroso.
Experimente o Felo AI Gratuitamente → https://felo.ai
Este post também está disponível em English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, Français, العربية, Русский, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Türkçe, Italiano, ไทย, Español and বাংলা.