🙆♀️Conquista revolucionária da Felo AI: precisão de 91,2% no teste de benchmark SimpleQA, estabelecendo novos padrões para a busca em IA

A Felo AI alcançou um avanço revolucionário no teste de benchmark SimpleQA, liderando o campo da busca em IA com uma precisão de 91,2%. Descubra como tecnologias inovadoras, como a reescrita de consultas entre idiomas, melhoram a experiência de busca.
Inovando o mecanismo de busca AI com precisão incomparável
Estamos empolgados em anunciar que Felo superou todos os concorrentes em seu desempenho mais recente no benchmark SimpleQA. O SimpleQA foi desenvolvido pela OpenAI para avaliar a precisão factual em perguntas e respostas de IA. Com uma impressionante 91,2% de precisão, o Felo Pro (modo rápido) estabelece um novo padrão para mecanismos de busca AI, superando significativamente concorrentes como Perplexity e Gemini.
Benchmark SimpleQA: A pedra de toque para mecanismos de busca AI
SimpleQA é um benchmark desenvolvido pela OpenAI, projetado para medir a eficácia dos sistemas de IA em responder a perguntas factuais concisas utilizando dados da web. Ao contrário das métricas de busca tradicionais, o SimpleQA foca na precisão e confiabilidade dos fatos, enfatizando a redução de problemas de alucinação em sistemas de IA — um desafio de longa data no campo da IA. O desempenho excepcional do Felo neste benchmark demonstra nosso compromisso em fornecer soluções de ponta para mecanismos de busca AI.
Método de teste: Um quadro de avaliação rigoroso
A avaliação do Felo no benchmark SimpleQA utilizou um quadro padronizado para garantir equidade e transparência. O método inclui os seguintes passos:
- Pergunta: Submeter diretamente as perguntas do conjunto de dados SimpleQA ao Felo.
- Geração de respostas: Utilizar o Felo Pro (modo rápido) para gerar respostas.
Todos os testes foram realizados utilizando o mesmo conjunto de perguntas e critérios de pontuação, que estão definidos no protocolo original do SimpleQA, garantindo uma comparação justa entre todos os participantes.
Resultados do teste: Felo alcança uma precisão líder na indústria
Os resultados do benchmark SimpleQA destacam a posição de liderança do Felo no campo da busca inteligente em IA:
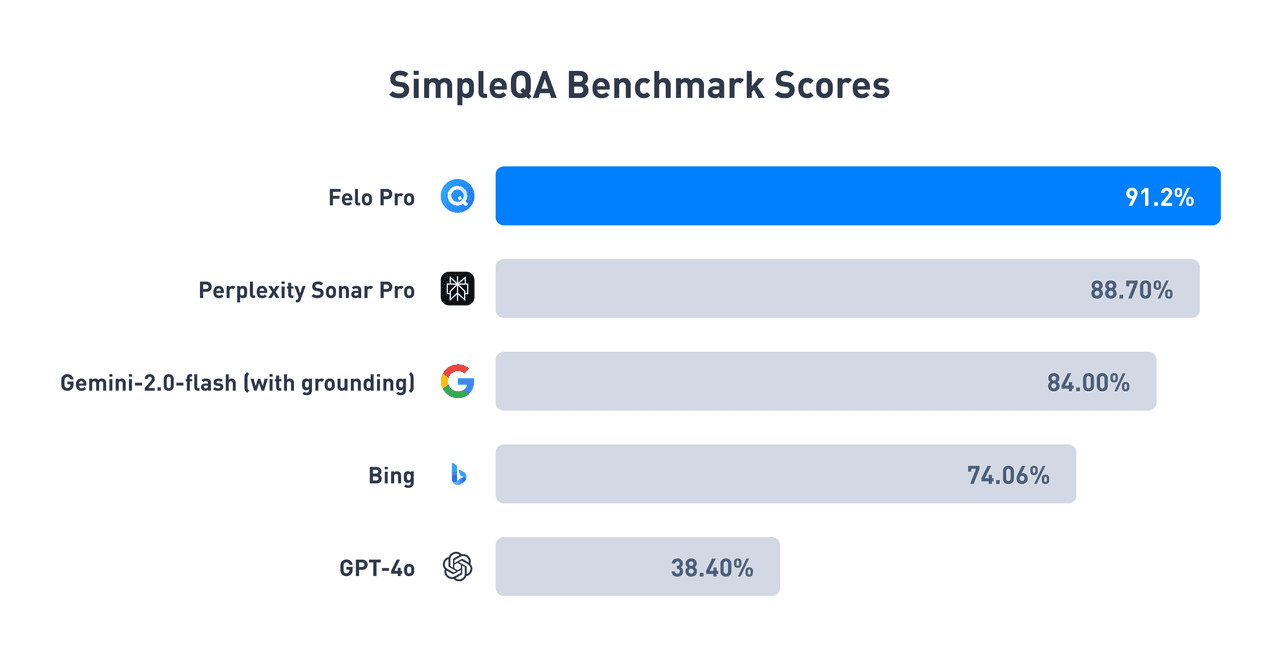
Nós tornamos os resultados dos testes do Felo de código aberto, você pode acessar aqui para mais detalhes.
O que torna o Felo único?
Felo deve seu desempenho excepcional no benchmark SimpleQA à sua arquitetura e design inovadores, com diferenças chave incluindo:
- Reescrita de consultas avançada entre idiomas O Felo é capaz de dividir inteligentemente a consulta original em subconsultas mais granulares, escolhendo até mesmo o ambiente linguístico mais adequado para a busca com base nas perguntas dos usuários, otimizando essas subconsultas para busca em mecanismos tradicionais e sistemas RAG. Isso permite que o Felo obtenha mais páginas relevantes.
- Tecnologia de índice híbrido O Felo utiliza uma tecnologia de busca híbrida que combina palavras-chave e semântica, aplicando compressão semântica sensível ao modelo ao conteúdo da web, permitindo que o Felo remova ruídos irrelevantes enquanto preserva a densidade factual crítica. Isso garante que o LLM (modelo de linguagem grande) receba apenas as informações mais relevantes e de alta qualidade.
- Treinamento focado em busca Ao contrário dos mecanismos de busca genéricos, o Felo é ajustado especificamente para a maneira única como os modelos de linguagem grandes processam informações, desenvolvendo internamente 7 LLMs, proporcionando resultados de busca mais precisos e contextualizados.