Como Usar os Modelos de Raciocínio da OpenAI: o1-preview/o1-Mini Models - Chat AI Gratuito

O Chat AI Felo agora suporta o uso gratuito do modelo de Raciocínio O1
No cenário em rápida evolução da inteligência artificial, a OpenAI introduziu uma série inovadora de grandes modelos de linguagem conhecidos como a série o1. Esses modelos são projetados para realizar tarefas complexas de raciocínio, tornando-se uma ferramenta poderosa para desenvolvedores e pesquisadores. Neste post do blog, exploraremos como usar efetivamente os modelos de raciocínio da OpenAI, focando em suas capacidades, limitações e melhores práticas para implementação.
O Felo AI Chat agora suporta o uso gratuito do modelo de Raciocínio O1. Vá experimentar!


Compreendendo os Modelos da Série OpenAI o1
Os modelos da série o1 são distintos das iterações anteriores dos modelos de linguagem da OpenAI devido à sua metodologia de treinamento única. Eles utilizam aprendizado por reforço para aprimorar suas capacidades de raciocínio, permitindo que pensem criticamente antes de gerar respostas. Esse processo interno de pensamento permite que os modelos produzam uma longa cadeia de raciocínio, o que é particularmente benéfico para enfrentar problemas complexos.
Principais Características dos Modelos OpenAI o1
1. **Raciocínio Avançado**: Os modelos o1 se destacam em raciocínio científico, alcançando resultados impressionantes em programação competitiva e benchmarks acadêmicos. Por exemplo, eles estão no 89º percentil no Codeforces e demonstraram precisão em nível de doutorado em disciplinas como física, biologia e química.
2. **Duas Variantes**: A OpenAI oferece duas versões dos modelos o1 através de sua API:
- **o1-preview**: Esta é uma versão inicial projetada para enfrentar problemas difíceis usando amplo conhecimento geral.
- **o1-mini**: Uma variante mais rápida e econômica, particularmente adequada para tarefas de codificação, matemática e ciências que não requerem amplo conhecimento geral.
3. **Janela de Contexto**: Os modelos o1 vêm com uma janela de contexto substancial de 128.000 tokens, permitindo uma entrada e raciocínio extensivos. No entanto, é crucial gerenciar esse contexto de forma eficaz para evitar atingir os limites de tokens.
Começando com os Modelos OpenAI o1
Para começar a usar os modelos o1, os desenvolvedores podem acessá-los através do endpoint de conclusões de chat da API da OpenAI.
Você está pronto para elevar sua experiência de interação com IA? O Felo AI Chat agora oferece a oportunidade de explorar o modelo de Raciocínio O1 de ponta sem custo!
Experimente gratuitamente o modelo de raciocínio o1.
Limitações Beta dos Modelos OpenAI o1
É importante notar que os modelos o1 estão atualmente em beta, o que significa que existem algumas limitações a serem observadas:
Durante a fase beta, muitos parâmetros da API de conclusão de chat ainda não estão disponíveis. Mais notavelmente:
- Modalidades: apenas texto, imagens não são suportadas.
- Tipos de mensagens: apenas mensagens de usuário e assistente, mensagens de sistema não são suportadas.
- Streaming: não suportado.
- Ferramentas: ferramentas, chamadas de função e parâmetros de formato de resposta não são suportados.
- Logprobs: não suportado.
- Outros:
temperature,top_penestão fixos em1, enquantopresence_penaltyefrequency_penaltyestão fixos em0. - Assistentes e Lote: esses modelos não são suportados na API de Assistentes ou na API de Lote.
**Gerenciando a Janela de Contexto**:
Com uma janela de contexto de 128.000 tokens, é essencial gerenciar o espaço de forma eficaz. Cada conclusão tem um limite máximo de tokens de saída, que inclui tanto tokens de raciocínio quanto tokens de conclusão visíveis. Por exemplo:
- **o1-preview**: Até 32.768 tokens
- **o1-mini**: Até 65.536 tokens
Velocidade dos Modelos OpenAI o1
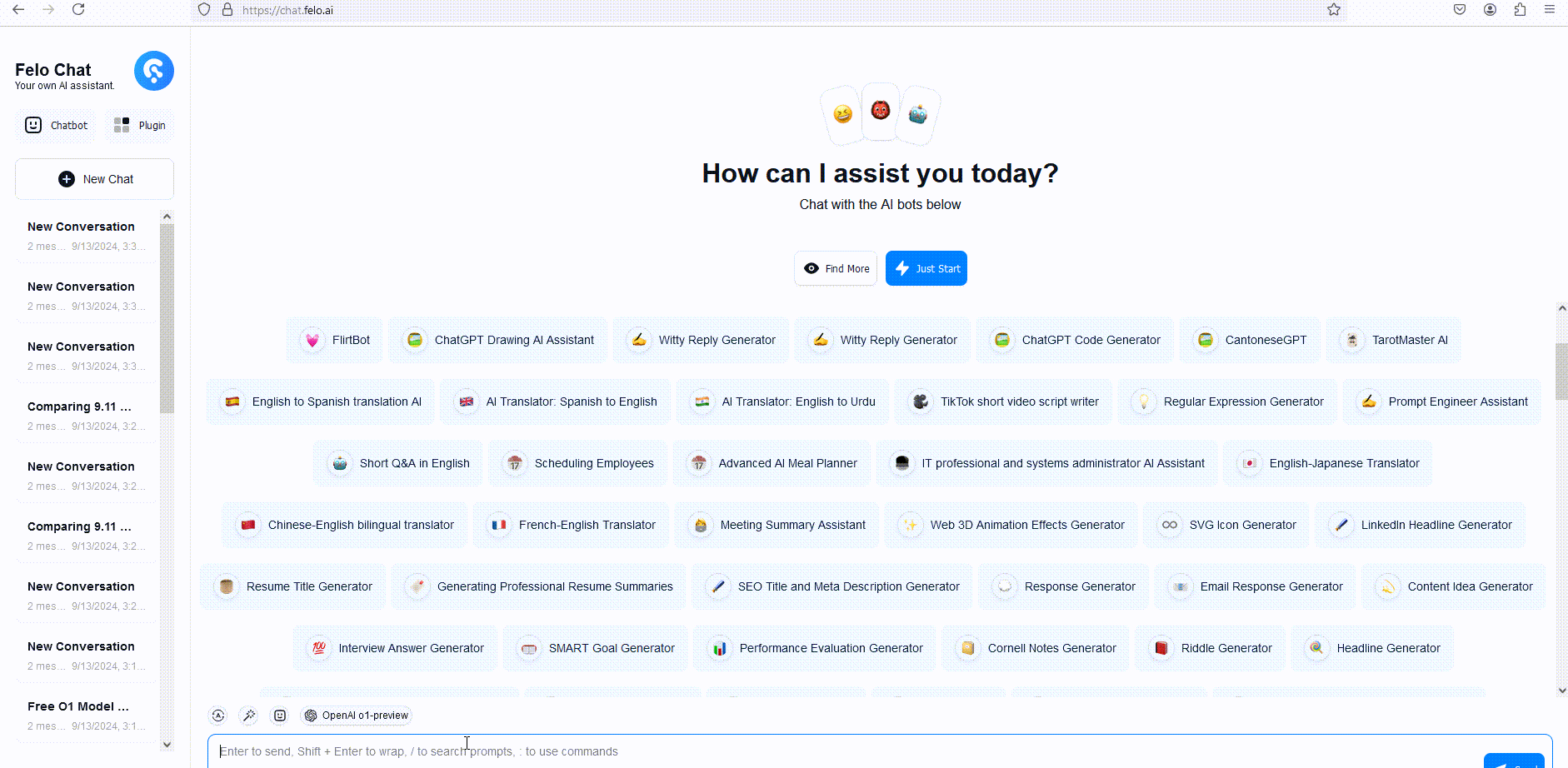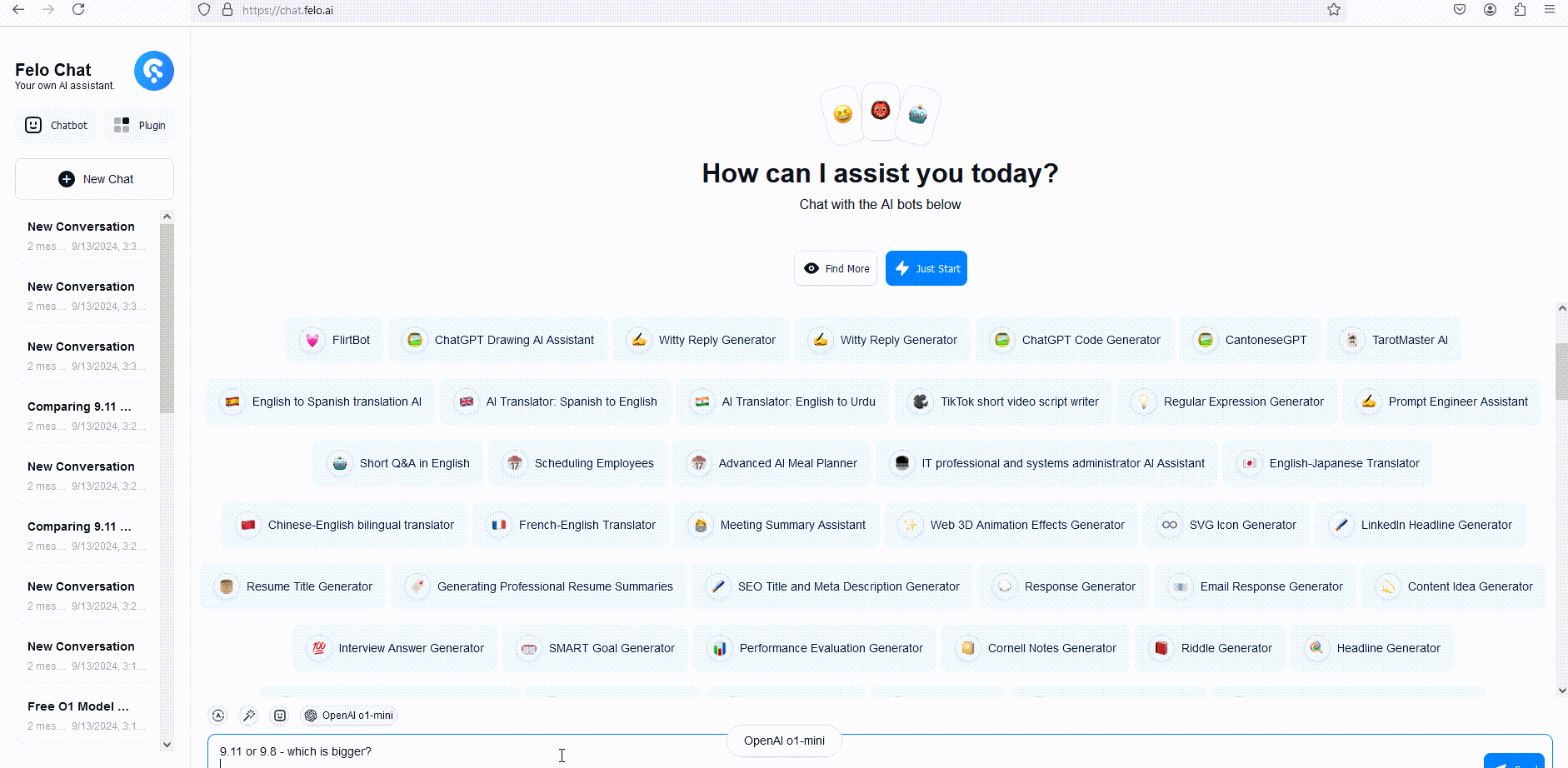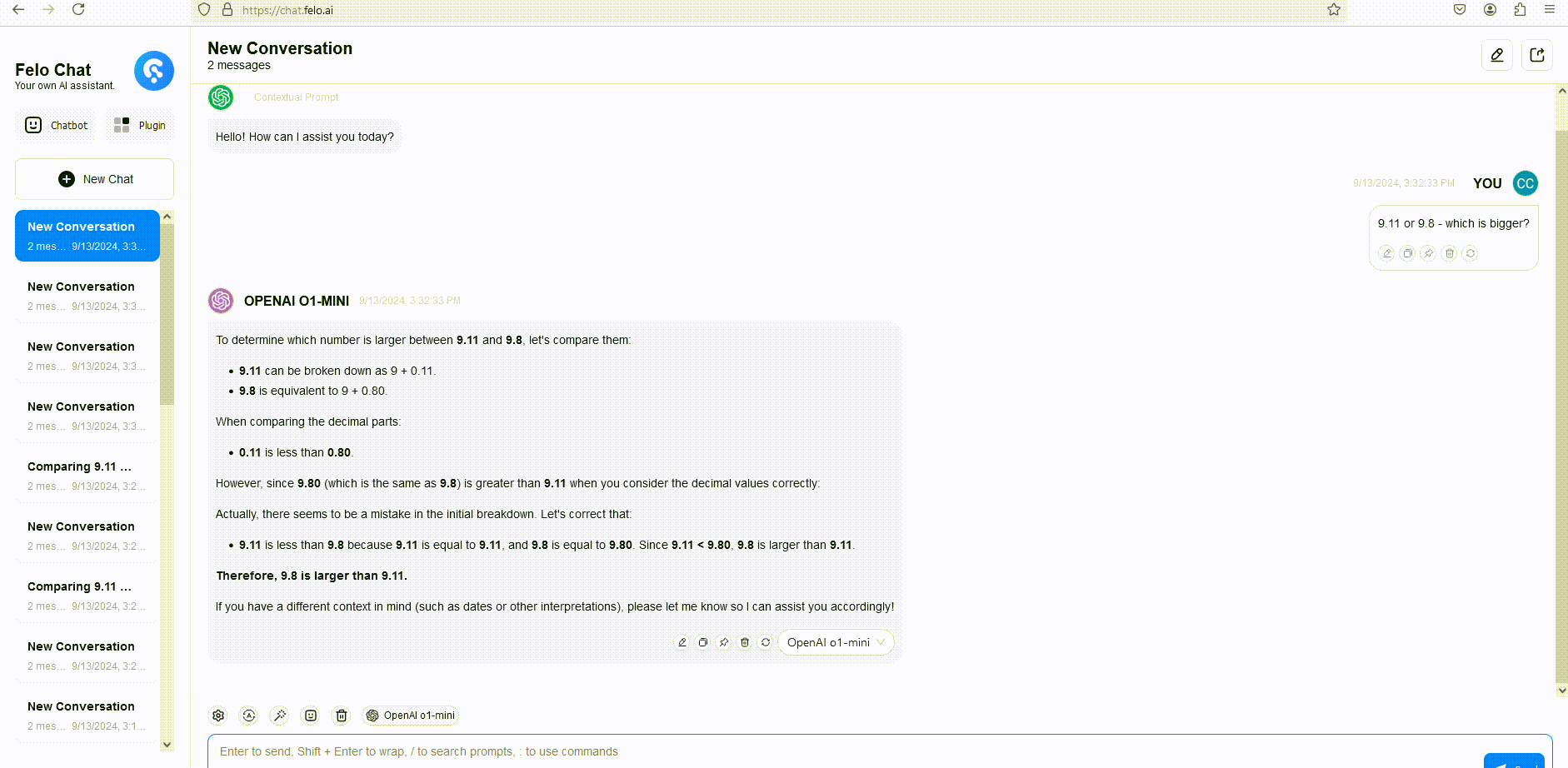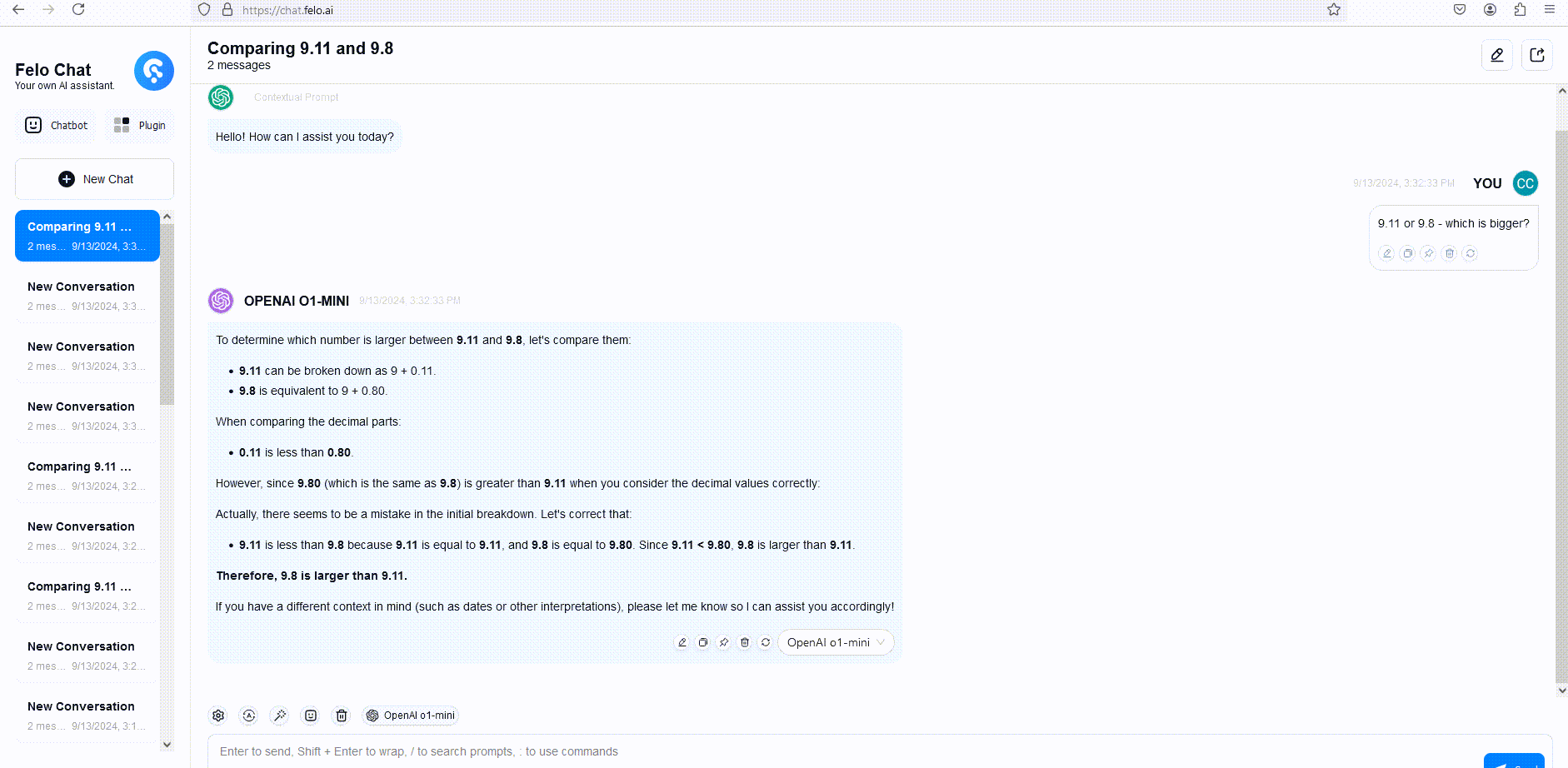
Para ilustrar, comparamos as respostas do GPT-4o, o1-mini e o1-preview a uma pergunta de raciocínio verbal. Embora o GPT-4o tenha fornecido uma resposta incorreta, tanto o o1-mini quanto o o1-preview responderam corretamente, com o o1-mini chegando à resposta correta aproximadamente 3-5 vezes mais rápido.

Como escolher entre os modelos GPT-4o, O1 Mini e O1 Preview?
**O1 Preview**: Esta é uma versão inicial do modelo OpenAI O1, projetada para aproveitar um amplo conhecimento geral para raciocinar sobre problemas complexos.
**O1 Mini**: Uma versão mais rápida e acessível do O1, particularmente boa em tarefas de codificação, matemática e ciências, ideal para situações que não requerem amplo conhecimento geral.
Os modelos O1 oferecem melhorias significativas em raciocínio, mas não são destinados a substituir o GPT-4o em todos os casos de uso.
Para aplicações que precisam de entrada de imagem, chamadas de função ou tempos de resposta consistentemente rápidos, os modelos GPT-4o e GPT-4o Mini ainda são as melhores escolhas. No entanto, se você está desenvolvendo aplicações que exigem raciocínio profundo e podem acomodar tempos de resposta mais longos, os modelos O1 podem ser uma ótima opção.
Dicas para Prompting Eficaz dos Modelos O1 Mini e O1 Preview
Os Modelos OpenAI o1 funcionam melhor com prompts claros e diretos. Algumas técnicas, como prompting de poucos exemplos ou pedir ao modelo para "pensar passo a passo", podem não melhorar o desempenho e até mesmo prejudicá-lo. Aqui estão algumas melhores práticas a seguir:
1. **Mantenha os Prompts Simples e Diretos**: Os modelos são mais eficazes quando recebem instruções breves e claras, sem necessidade de extensa elaboração.
2. **Evite Prompts de Cadeia de Pensamento**: Como esses modelos lidam com o raciocínio internamente, não há necessidade de solicitar que "pensem passo a passo" ou "explique seu raciocínio".
3. **Use Delimitadores para Clareza**: Utilize delimitadores como aspas triplas, tags XML ou títulos de seção para definir claramente diferentes partes da entrada, o que ajuda o modelo a interpretar cada seção corretamente.
4. **Limite o Contexto Adicional na Geração Aumentada por Recuperação (RAG)**: Ao fornecer contexto ou documentos extras, inclua apenas as informações mais pertinentes para evitar complicar a resposta do modelo.
Preços para os modelos o1 Mini e 1 Preview.
O cálculo de custo para os modelos o1 Mini e 1 Preview é diferente de outros modelos, pois inclui um custo adicional para tokens de raciocínio.
Preços do o1-mini
$3,00 / 1M tokens de entrada
$12,00 / 1M tokens de saída
Preços do o1-preview
$15,00 / 1M tokens de entrada
$60,00 / 1M tokens de saída
Gerenciando Custos do Modelo o1-preview/ o1-mini
Para controlar despesas com os modelos da série o1, você pode usar o parâmetro `max_completion_tokens` para definir um limite no número total de tokens que o modelo gera, abrangendo tanto tokens de raciocínio quanto tokens de conclusão.
Nos modelos anteriores, o parâmetro `max_tokens` gerenciava tanto o número de tokens gerados quanto o número de tokens visíveis para o usuário, que eram sempre os mesmos. No entanto, com a série o1, o total de tokens gerados pode ultrapassar o número de tokens mostrados ao usuário devido aos tokens de raciocínio internos.
Como algumas aplicações dependem de `max_tokens` correspondendo ao número de tokens recebidos da API, a série o1 introduz `max_completion_tokens` para controlar especificamente o número total de tokens produzidos pelo modelo, incluindo tanto tokens de raciocínio quanto tokens de conclusão visíveis. Essa opção explícita garante que as aplicações existentes permaneçam compatíveis com os novos modelos. O parâmetro `max_tokens` continua a funcionar como funcionava para todos os modelos anteriores.
Conclusão
Os modelos da série o1 da OpenAI representam um avanço significativo no campo da inteligência artificial, particularmente em sua capacidade de realizar tarefas complexas de raciocínio. Ao entender suas capacidades, limitações e melhores práticas para uso, os desenvolvedores podem aproveitar o poder desses modelos para criar aplicações inovadoras. À medida que a OpenAI continua a refinar e expandir a série o1, podemos esperar desenvolvimentos ainda mais empolgantes no reino do raciocínio impulsionado por IA. Seja você um desenvolvedor experiente ou esteja apenas começando, os modelos o1 oferecem uma oportunidade única de explorar o futuro dos sistemas inteligentes. Boa codificação!
O Felo AI Chat sempre oferece uma experiência gratuita com modelos de IA avançados de todo o mundo. Clique aqui para experimentar!