Выпуск Claude Opus 4.8: Самая совершенная модель Anthropic на сегодняшний день

Anthropic выпустила Claude Opus 4.8 — более быструю, более честную и лучше справляющуюся с агентными задачами модель. Рассказываем обо всех нововведениях и их значении для разработчиков.

На этой неделе Anthropic выпустила Claude Opus 4.8. Это самая мощная модель, доступная в широком доступе, основанная на Opus 4.7 и улучшенная по направлениям кодирования, рассуждений, агентных задач и честности. Цена осталась прежней: $5 за миллион входных токенов и $25 за миллион выходных токенов.
Вот что изменилось и почему это важно для разработчиков, создающих решения на её основе.
Что изменилось с Opus 4.7?
Основные изменения:
1. Улучшенные суждения и честность
Opus 4.8 значительно реже делает необоснованные утверждения или пропускает ошибки в коде. Согласно оценкам Anthropic, модель примерно в четыре раза реже, чем её предшественник, позволяет багам в собственном коде остаться незамеченными. Это именно тот тип улучшений, который важен, когда вы доверяете модели автономную работу.
Ранние тестировщики отмечают, что модель задаёт правильные вопросы, замечает собственные ошибки и возражает, если план кажется нелогичным.
2. Более высокая агентная производительность
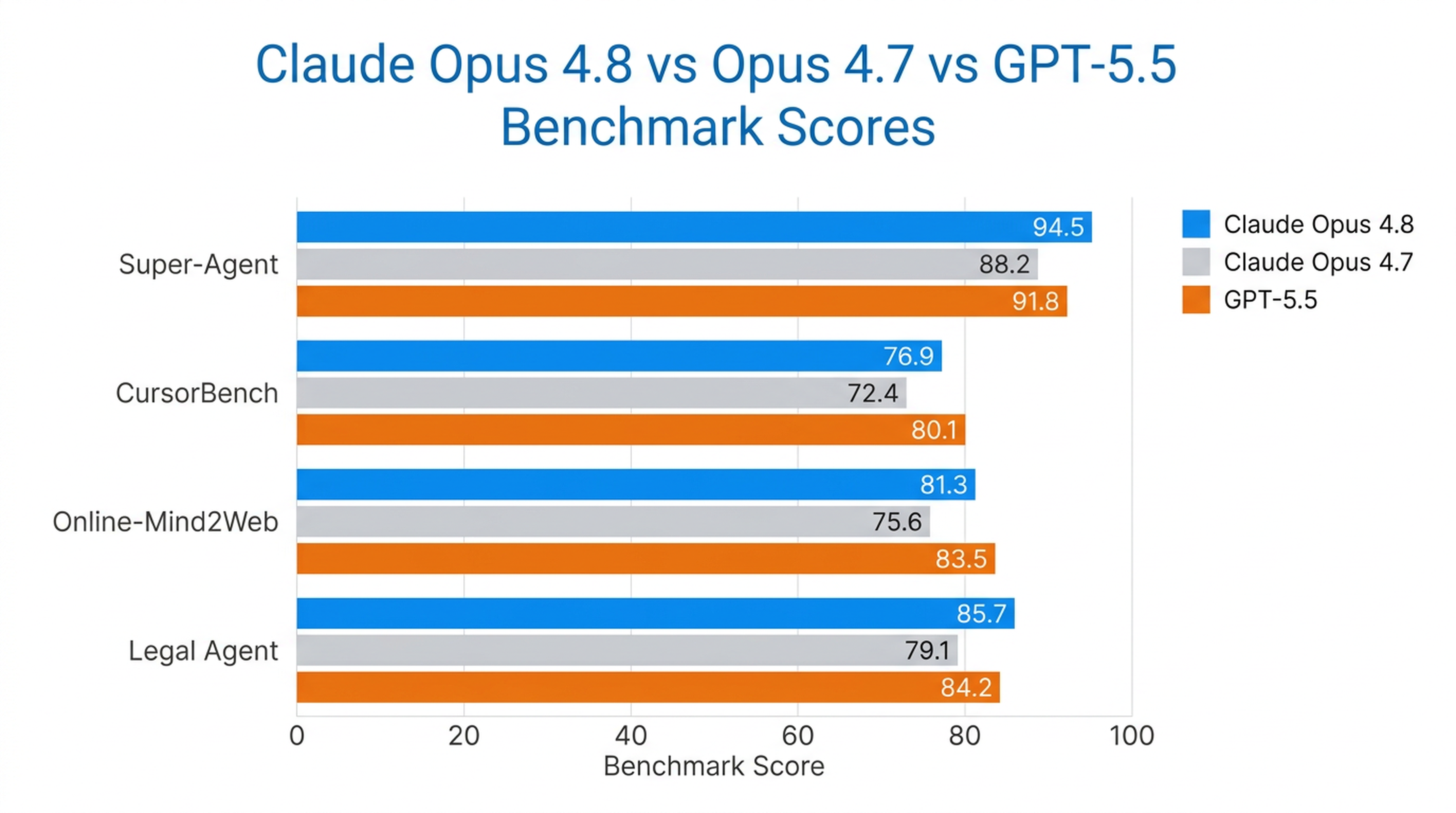
Opus 4.8 — единственная модель, выполнившая все кейсы от начала до конца в бенчмарке Super-Agent Anthropic, обойдя предыдущие версии Opus и GPT-5.5 при сопоставимой стоимости. В CursorBench она превосходит ранние версии Opus на всех уровнях усилий, используя меньше шагов вызова инструментов при той же интеллектуальной нагрузке.
Кроме того, это самая сильная модель Anthropic в задачах компьютерного использования и браузерных агентов, показавшая результат 84% в Online-Mind2Web.
3. Более быстрая и эффективная работа с инструментами
Модель теперь реже пропускает вызовы инструментов, необходимых для выполнения задачи — это была известная проблема в Opus 4.7. Долгие агентные цепочки остаются в контексте задачи с меньшим количеством сбоев после сжатия контекста.
4. Адаптивное мышление, которое действительно адаптируется
С включённым адаптивным мышлением Opus 4.8 при каждом ходе решает, нужны ли рассуждения. Простые запросы получают прямой ответ, а для сложных выполняются рассуждения перед ответом. Это экономит токены по сравнению с Opus 4.7.
Новые функции, о которых стоит знать
Контроль усилий — теперь во всех тарифах
Новый переключатель рядом с выбором модели позволяет пользователям задавать, сколько усилий Claude тратит на ответ. По умолчанию Opus 4.8 использует уровень high, с вариантами extra и max для более сложных задач. Лимиты в Claude Code повышены, чтобы учесть рост объёма токенов.
Режим быстродействия — в 2,5 раза быстрее и дешевле
Режим Fast теперь доступен для Opus 4.8 как исследовательская версия в API Claude. Он обеспечивает до 2,5× больше выходных токенов в секунду при стоимости, втрое ниже по сравнению с предыдущими моделями.
Системные сообщения в середине диалога
Теперь API сообщений поддерживает записи role: "system" внутри массива сообщений. Вы можете обновлять инструкции Claude во время выполнения задачи без сброса кэша промпта — полезно, когда во время агентного цикла меняются разрешения или контекст.
Снижение минимальной длины кэшируемого промпта
Минимальная длина промпта, который можно кэшировать, уменьшена до 1 024 токенов. Промпты, которые ранее были слишком короткими для кэширования на Opus 4.7, теперь создают записи в кэше без изменений в коде.
Результаты в реальных бенчмарках
| Бенчмарк | Производительность Opus 4.8 |
|---|---|
| Super-Agent | Все кейсы завершены от начала до конца (единственная модель, сделавшая это) |
| CursorBench | Превосходит все предыдущие модели Opus на каждом уровне усилий |
| Online-Mind2Web | 84% (самая сильная из протестированных моделей) |
| Legal Agent Benchmark | Самый высокий результат; первая модель, преодолевшая порог 10% в целом |

Opus 4.8 лучше всего показывает себя там, где важна автономия на долгих горизонтах — в агентных задачах программирования, исследовательских проектах, юридических процессах и корпоративной работе с знаниями.
Цены — без изменений по сравнению с Opus 4.7
| Режим | Ввод | Вывод |
|---|---|---|
| Стандартный | $5 / 1M токенов | $25 / 1M токенов |
| Быстрый | $10 / 1M токенов | $50 / 1M токенов |
Та же цена, что и у Opus 4.7, но с лучшей производительностью. Идентификатор модели в API — claude-opus-4-8. Поддерживается контекстное окно в 1 млн токенов и максимум 128 тыс. выходных токенов.
Что дальше: модели класса Mythos
Anthropic также намекнула на новую серию моделей с «ещё более высоким уровнем интеллекта, чем у Opus». Небольшое число организаций уже использует Claude Mythos Preview для задач кибербезопасности в рамках проекта Project Glasswing. Компания планирует предоставить модели класса Mythos всем клиентам в ближайшие недели, как только будут внедрены необходимые меры безопасности.
Почему важна диверсификация моделей
Сегодня новые модели искусственного интеллекта выходят каждую неделю. Для разработчиков реальный вопрос — не какая модель «лучшая», а какая подходит для конкретной задачи и как легко переключаться между ними без трения.
Именно эту задачу решает Felo AI. Помимо поиска на базе ИИ, который использует передовые модели для ответов в реальном времени, Felo предлагает LLM Playground — платформу, где можно вызывать, тестировать и сравнивать результаты множества ведущих моделей в одном месте. Никаких juggling API-ключей, никаких переключений между панелями. Просто выберите модель, запустите промпт и посмотрите, как она справляется.
Если вы оцениваете модели для своего рабочего процесса или просто интересуетесь возможностями рынка, единый интерфейс делает процесс сравнения намного проще.
Попробуйте Felo AI бесплатно → https://felo.ai
Эта статья также доступна на следующих языках: English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, Français, العربية, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Türkçe, Italiano, ไทย, Español, বাংলা and Português.