Claude Opus 4.8 เปิดตัวแล้ว: โมเดลที่ทรงพลังที่สุดจาก Anthropic จนถึงตอนนี้

Anthropic เพิ่งเปิดตัว Claude Opus 4.8 — เร็วขึ้น ซื่อสัตย์ขึ้น และเก่งขึ้นในงานเชิงตัวแทน (agentic tasks) มาดูกันว่ามีอะไรใหม่บ้างและเหตุใดจึงสำคัญสำหรับนักพัฒนา

Anthropic เปิดตัว Claude Opus 4.8 ในสัปดาห์นี้ ซึ่งเป็นโมเดลที่ทรงพลังที่สุดที่ปล่อยให้ใช้งานได้ทั่วไป โดยพัฒนาต่อจาก Opus 4.7 ทั้งในด้านการเขียนโค้ด การให้เหตุผล งานเชิงตัวแทน และความซื่อสัตย์ ราคายังคงเดิม: 5 ดอลลาร์ต่อหนึ่งล้านโทเคนอินพุต และ 25 ดอลลาร์ต่อหนึ่งล้านโทเคนเอาต์พุต
ต่อไปนี้คือสิ่งที่เปลี่ยนแปลง และเหตุผลที่สำคัญสำหรับนักพัฒนาที่สร้างบนแพลตฟอร์มนี้
มีอะไรเปลี่ยนไปจาก Opus 4.7?
ต่อไปนี้คือสิ่งที่เปลี่ยนแปลงจริง ๆ:
1. การตัดสินใจและความซื่อสัตย์ที่ดีขึ้น
Opus 4.8 มีแนวโน้มที่จะไม่กล่าวอ้างโดยไม่มีข้อมูลสนับสนุน หรือปล่อยให้ข้อบกพร่องในโค้ดหลุดไปโดยไม่ตรวจพบมากกว่ารุ่นก่อน ผลการทดสอบของ Anthropic แสดงว่า มันมีแนวโน้มให้บั๊กผ่านไปโดยไม่แจ้งเตือนน้อยกว่ารุ่นก่อนถึง 4 เท่า การปรับปรุงแบบนี้มีความสำคัญมากเมื่อคุณต้องพึ่งโมเดลให้ทำงานอย่างอัตโนมัติ
ผู้ทดสอบกลุ่มแรก ๆ รายงานว่า มันถามคำถามได้ตรงจุด จับความผิดพลาดของตัวเองได้ และแสดงข้อโต้แย้งเมื่อแผนการไม่สมเหตุสมผล
2. ประสิทธิภาพเชิงตัวแทน (Agentic Performance) ที่แข็งแกร่งขึ้น
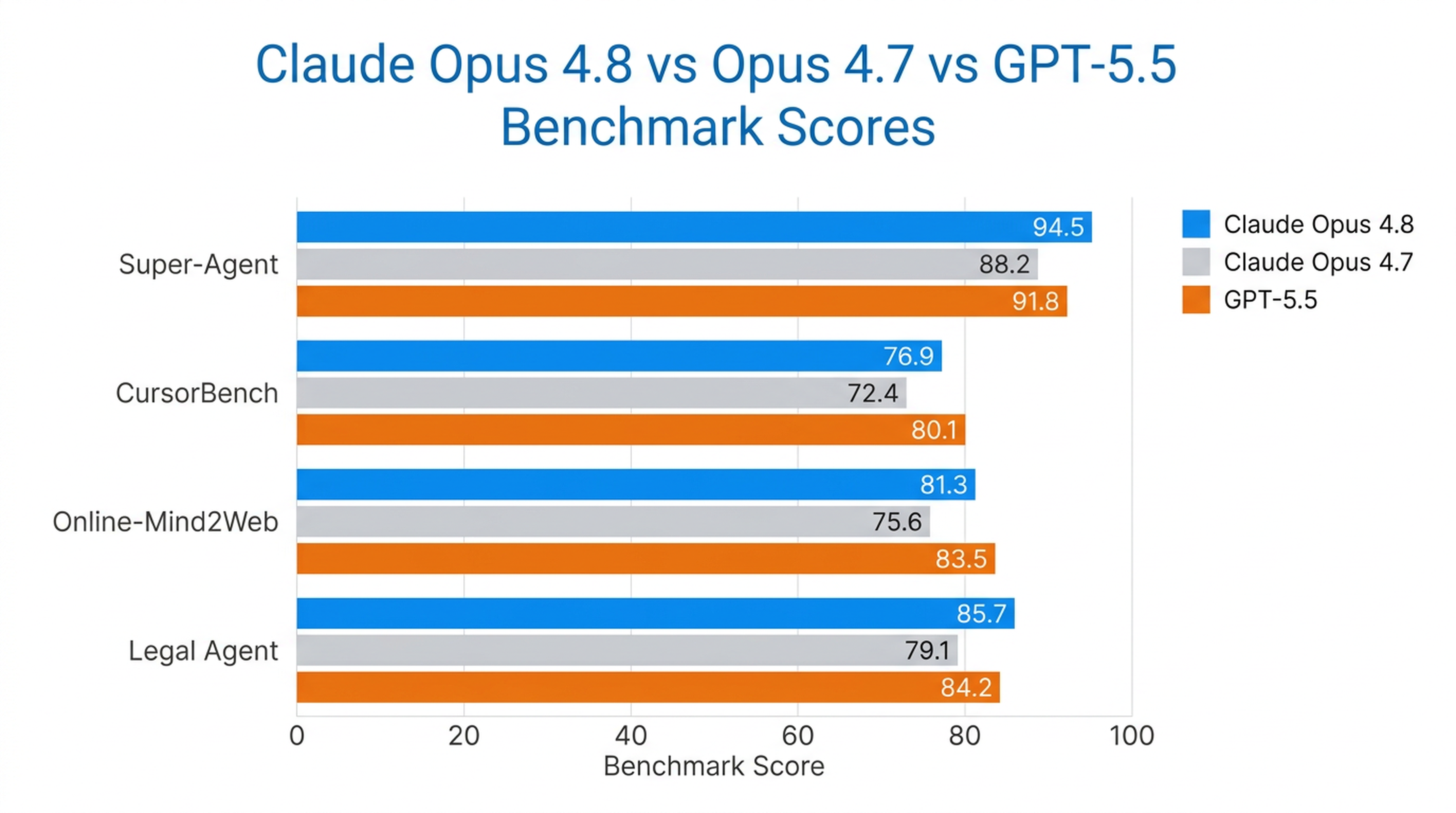
Opus 4.8 เป็นโมเดลเดียวที่ทำทุกเคสจนจบในฐานข้อมูล Super-Agent ของ Anthropic เอาชนะทั้งรุ่นก่อนหน้าและ GPT-5.5 ที่ต้นทุนเท่ากัน บน CursorBench มันทำได้ดีกว่าทุกรุ่นก่อนหน้าของ Opus ในทุกระดับความพยายาม โดยใช้ขั้นตอนเรียกใช้เครื่องมือน้อยลงสำหรับความฉลาดในระดับเดียวกัน
นอกจากนี้ มันยังเป็นโมเดลด้านการใช้คอมพิวเตอร์และเบราว์เซอร์ตัวแทนที่แข็งแกร่งที่สุดที่ Anthropic ทดสอบ โดยได้คะแนน 84% บน Online-Mind2Web
3. การเรียกใช้เครื่องมือที่เร็วและมีประสิทธิภาพยิ่งขึ้น
โมเดลนี้มีแนวโน้มที่จะไม่ข้ามการเรียกใช้เครื่องมือที่งานต้องใช้ ซึ่งเคยเป็นปัญหาใน Opus 4.7 ร่องรอยการทำงานแบบตัวแทนที่ยาวนานก็มีแนวโน้มไม่หลุดจากงานหลังการบีบอัดบริบท
4. การคิดแบบ Adaptive ที่ปรับได้จริง
เมื่อเปิดใช้งานโหมด adaptive thinking, Opus 4.8 จะตัดสินใจในแต่ละรอบว่าจำเป็นต้องให้เหตุผลหรือไม่ การค้นหาง่าย ๆ จะได้คำตอบโดยตรง ส่วนปัญหาซับซ้อนจะได้รับการให้เหตุผลก่อนคำตอบ ใช้โทเคนน้อยลงเมื่อเทียบกับ Opus 4.7
ฟีเจอร์ใหม่ที่น่าสนใจ
ควบคุมระดับความพยายาม — มีให้ในทุกแผน
มีตัวควบคุมใหม่อยู่ข้างตัวเลือกโมเดล ให้ผู้ใช้เลือกได้ว่า Claude จะใช้ความพยายามมากน้อยเพียงใดในการตอบกลับ ค่าเริ่มต้นของ Opus 4.8 คือ high โดยมีตัวเลือก extra และ max สำหรับงานที่ยากกว่า ระบบจำกัดอัตราใน Claude Code ถูกขยายเพื่อรองรับการใช้โทเคนที่มากขึ้น
โหมดเร็ว — ความเร็วเพิ่ม 2.5 เท่า ราคาถูกลง
โหมดเร็ว (Fast mode) พร้อมใช้งานแล้วสำหรับ Opus 4.8 ในฐานะเวอร์ชันพรีวิวเพื่อการวิจัยบน Claude API โดยให้ผลลัพธ์ที่มี ความเร็วในการสร้างโทเคนเอาต์พุตสูงขึ้นถึง 2.5 เท่า และมีต้นทุนต่ำกว่ารุ่นก่อนถึงสามเท่า
ข้อความระบบระหว่างการสนทนา
Messages API ตอนนี้รองรับการเพิ่ม role: "system" ในอาร์เรย์ข้อความ คุณสามารถอัปเดตคำแนะนำของ Claude ระหว่างงานได้โดยไม่ทำให้ prompt cache เสียประโยชน์ เหมาะสำหรับเมื่อต้องเปลี่ยนสิทธิ์หรือบริบทระหว่างลูปเชิงตัวแทน
ลดขนาดขั้นต่ำของ Prompt Cache
ความยาวขั้นต่ำของพรอมต์ที่สามารถแคชได้ลดลงเหลือเพียง 1,024 โทเคน พรอมต์ที่สั้นเกินไปใน Opus 4.7 ตอนนี้สามารถสร้างแคชได้โดยไม่ต้องแก้ไขโค้ด
การทดสอบในสภาพแวดล้อมจริง
| การทดสอบ | ประสิทธิภาพของ Opus 4.8 |
|---|---|
| Super-Agent | ทำครบทุกเคสตั้งแต่ต้นจนจบ (โมเดลเดียวที่ทำได้) |
| CursorBench | ทำได้ดีกว่าทุกรุ่นก่อนหน้าของ Opus ในทุกระดับ |
| Online-Mind2Web | 84% (โมเดลที่แข็งแกร่งที่สุดในการทดสอบ) |
| Legal Agent Benchmark | ได้คะแนนสูงสุด และเป็นโมเดลแรกที่ทะลุ 10% โดยรวม |

Opus 4.8 แข็งแกร่งที่สุดในงานที่ต้องการความอิสระระยะยาว — เช่น ตัวแทนเขียนโค้ด ตัวแทนวิจัย งานด้านกฎหมาย และการจัดการความรู้ภายในองค์กร
ราคา — ไม่เปลี่ยนจาก Opus 4.7
| โหมด | อินพุต | เอาต์พุต |
|---|---|---|
| มาตรฐาน | $5 / 1M tokens | $25 / 1M tokens |
| เร็ว | $10 / 1M tokens | $50 / 1M tokens |
ราคายังคงเท่า Opus 4.7 แต่มีประสิทธิภาพดีกว่า รหัสโมเดลใน API คือ claude-opus-4-8 รองรับขนาดหน้าต่างบริบท 1 ล้านโทเคน และเอาต์พุตสูงสุด 128k โทเคน
สิ่งที่จะตามมา: โมเดลระดับ Mythos
Anthropic ยังได้บอกใบ้ถึงโมเดลระดับใหม่ที่ “ฉลาดกว่า Opus” องค์กรจำนวนน้อยกำลังใช้งาน Claude Mythos Preview สำหรับงานด้านความปลอดภัยทางไซเบอร์ผ่านโครงการ Project Glasswing บริษัทมีแผนจะเปิดให้ลูกค้าทุกคนเข้าถึงโมเดลระดับ Mythos ในอีกไม่กี่สัปดาห์ข้างหน้า เมื่อระบบความปลอดภัยพร้อมแล้ว
ทำไมความหลากหลายของโมเดลจึงสำคัญ
ทุกวันนี้ โมเดล AI ใหม่ออกมาทุกสัปดาห์ สำหรับนักพัฒนาที่สร้างบนโมเดลเหล่านี้ คำถามจริง ๆ ไม่ใช่ว่า “โมเดลไหนดีที่สุด” แต่คือ “โมเดลไหนเหมาะกับงานไหน” และ “จะสลับระหว่างโมเดลได้อย่างไรโดยไม่ยุ่งยาก”
นั่นคือสิ่งที่ Felo AI เข้ามาช่วยได้ นอกจากระบบค้นหาที่ขับเคลื่อนด้วย AI ซึ่งใช้โมเดลล้ำสมัยในการตอบคำถามแบบเรียลไทม์แล้ว Felo ยังมี LLM Playground ที่ให้คุณเรียกใช้ ทดสอบ และเปรียบเทียบผลลัพธ์จากโมเดลชั้นนำหลากหลายได้ในที่เดียว ไม่ต้องสลับ API key หรือแดชบอร์ดให้ยุ่งยาก แค่เลือกโมเดล รันพรอมต์ แล้วดูผลลัพธ์ได้เลย
หากคุณกำลังประเมินว่าโมเดลไหนเหมาะกับเวิร์กโฟลว์ของคุณ หรือแค่อยากรู้ว่ามีอะไรออกใหม่บ้าง การมีทุกโมเดลอยู่ในอินเทอร์เฟซเดียว ทำให้กระบวนการเปรียบเทียบง่ายขึ้นมาก
ลองใช้ Felo AI ฟรี → https://felo.ai
บทความนี้มีให้อ่านในภาษาต่อไปนี้ด้วย: English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, Français, العربية, Русский, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Türkçe, Italiano, Español, বাংলা and Português