AI Arama Motoru Bulanık Soru Değerlendirme Raporu (v1.3)

Bu makale, birkaç AI arama motorunun "bulanık sorgu soruları" ile başa çıkma performansını değerlendiriyor. Felo AI, %80 doğruluk oranı ile en iyi performansı gösterdi, ardından Perplexity Pro geldi. Makale, her ürünün güçlü ve zayıf yönlerini analiz ediyor ve açıklama için belirli vaka çalışmalarını sunuyor. Değerlendirme verileri ve sonuçları açık kaynak olarak sunulmuş olup, AI arama motorlarının geliştirilmesi için değerli içgörüler sağlıyor.
I. Sonuç
Günümüzün bilgiyle doygun döneminde, kullanıcı sorguları daha karmaşık hale geldikçe, AI Arama sistemleri arasındaki performans farkı giderek belirginleşiyor. Bu, özellikle yazılım yapılandırmaları, birden fazla veri kaynağı, çevrimiçi olarak kolayca erişilemeyen bilgiler veya tarih ile ilgili sorgularla başa çıkarken geçerlidir. Bu zorlu sorgulara "belirsiz soru aramaları" diyoruz. Bu değerlendirmede, Perplexity Basic, Perplexity Pro, GenSpark, Felo AI, iAsk ve You.com gibi birkaç popüler AI Arama motorunu kapsamlı bir şekilde test ettik ve bu tür sorgulara odaklandık.
Bir dizi titiz testin ardından, şu sonuçlara ulaştık:
- Felo AI, belirsiz sorguları ele alma konusunda olağanüstü bir yetenek sergileyerek öne çıktı. 80% doğruluk oranıyla grubun lideri oldu, çok kaynaklı verileri etkili bir şekilde işleyerek karmaşık sorgulara detaylı ve güvenilir yanıtlar sağladı, tıpkı deneyimli bir uzman gibi.
- Perplexity Pro, 70% puanla ikinci sırayı aldı ve bazı karmaşık sorularla başa çıkmada dayanıklılık gösterdi.
- iAsk, 60% doğruluk oranı ile yeterli bir performans sergileyerek zaman zaman belirsiz sorulara etkili yanıtlar verdi.
- Perplexity Basic, GenSpark, ve You.com bu değerlendirmede düşük performans gösterdi. Dil modelleri, belirsiz sorguları anlama ve işleme konusunda belirgin zayıflıklar sergileyerek sırasıyla 55%, 45% ve 35% doğruluk oranları elde etti, bu da tatmin edici değildi.
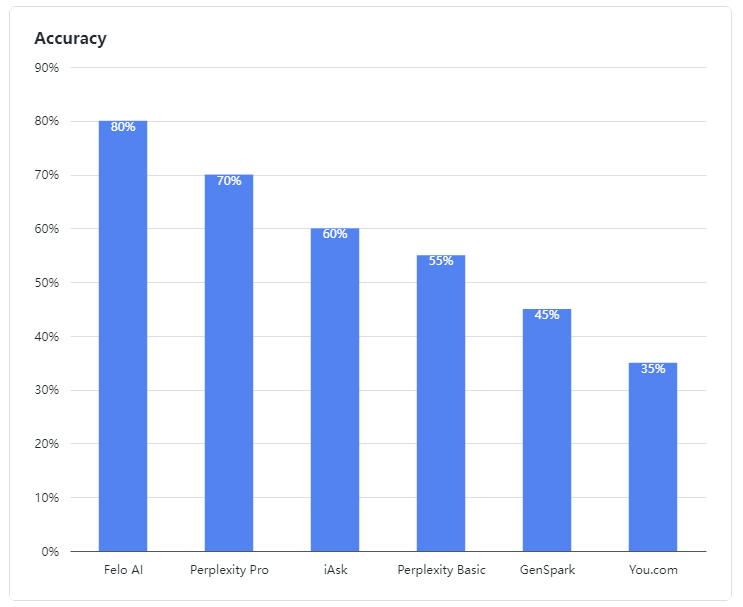
Şekil 1: Değerlendirilen ürünlerin doğruluk oranları
II. Değerlendirme Verileri
Değerlendirmemizde, belirsiz sorular yazılım yapılandırmaları, birden fazla veri kaynağı, çevrimiçi olarak mevcut olmayan bilgiler veya tarih ile ilgili bilgiler içerenler olarak tanımlandı. LLM'ler genellikle bu tür sorulara yanıt vermek için birden fazla kaynaktan içerik bir araya getirir.
Belirsiz soru test vakalarımız açık kaynaklıdır:
👉 Test vakaları: https://github.com/sparticleinc/ASEED/blob/main/datasets/ambiguity_search.csv
👉 Test sonuçları: https://github.com/sparticleinc/ASEED/tree/main/evaluations/promptfoo/ambiguity_search
III. Durum Analizi
👉 Soru: Bir sonraki Olimpiyat Oyunları nerede yapılacak?
Gerçek bilgi: 2028 Yaz Olimpiyat Oyunları, XXXIV Olimpiyat Oyunları olarak da bilinir, ABD'nin Los Angeles şehrinde yapılacaktır.
Yorum: Bir sonraki Olimpiyatların 2024'te Fransa'nın Paris şehrinde yapılacağına dair çevrimiçi bilgi bolluğu nedeniyle, Felo AI dışındaki tüm ürünler yanlış yanıt verdi.

