Claude Opus 4.8 Yayınlandı: Anthropic'in Şimdiye Kadarki En Yetkin Modeli

Anthropic, Claude Opus 4.8’i yayınladı — daha hızlı, daha dürüst ve ajan görevlerinde daha iyi. İşte yenilikler ve geliştiriciler için neden önemli oldukları.

Anthropic bu hafta Claude Opus 4.8’i yayınladı. Bu, genel kullanıma sundukları en yetkin model ve kodlama, mantık yürütme, ajan görevleri ve dürüstlük alanlarında Opus 4.7’nin üzerine inşa edilmiş durumda. Fiyat değişmedi: milyon girdi token’ı başına 5$, milyon çıktı token’ı başına 25$.
İşte nelerin değiştiği ve bu değişimlerin üzerine inşa eden geliştiriciler için neden önemli olduğu.
Opus 4.7’den Bu Yana Ne Değişti?
Gerçek değişiklikler şunlar:
1. Daha İyi Yargı ve Dürüstlük
Opus 4.8’in, desteklenmeyen iddialarda bulunma veya kod hatalarını fark etmeden geçirme olasılığı belirgin şekilde daha düşük. Anthropic’in değerlendirmeleri, modelin selefine kıyasla yaklaşık dört kat daha az hata görmezden geldiğini gösteriyor. Bu, bir modele özerk bir şekilde çalışma güvenini emanet ederken büyük önem taşıyan bir gelişme.
Erken test kullanıcıları, modelin doğru soruları sorduğunu, kendi hatalarını fark ettiğini ve mantıksız planlara itiraz ettiğini bildiriyor.
2. Daha Güçlü Ajan Performansı
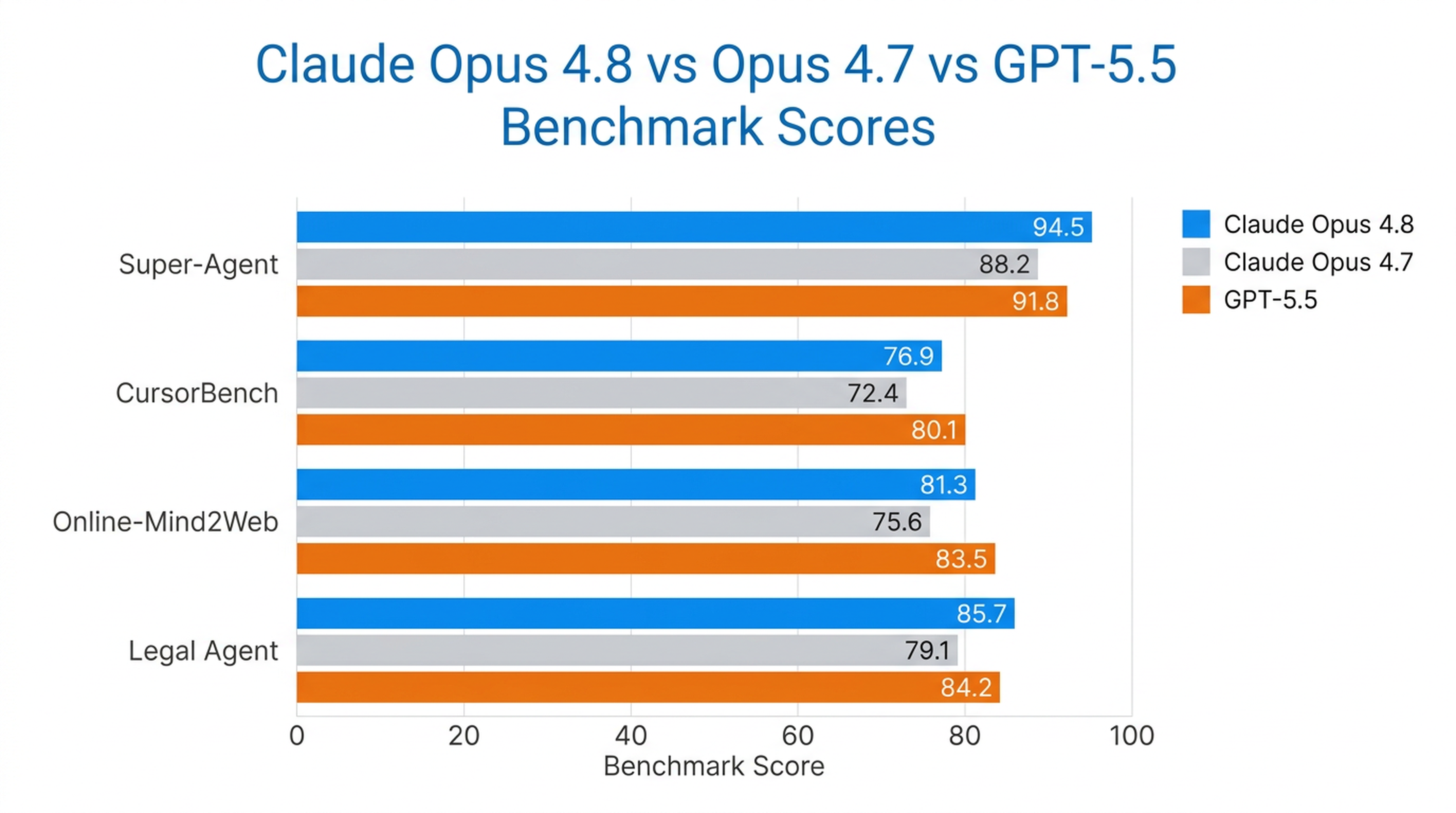
Opus 4.8, Anthropic’in Super-Agent testinde tüm senaryoları uçtan uca tamamlayan tek model oldu; önceki Opus sürümlerini ve GPT-5.5’i aynı maliyet düzeyinde geride bıraktı. CursorBench’te, her emek seviyesinde önceki Opus sürümlerini geçti ve aynı zeka düzeyi için daha az araç çağırma adımı kullandı.
Ayrıca Online-Mind2Web testinde %84 puan alarak Anthropic’in şimdiye kadar test ettiği en güçlü bilgisayar ve tarayıcı ajanı modeli oldu.
3. Daha Hızlı, Daha Verimli Araç Kullanımı
Model, bir görevin gerektirdiği araç çağrılarını atlama olasılığı açısından daha az hataya açık — bu, Opus 4.7’de bilinen bir zorluktu. Uzun ajan izleri de bağlam sıkıştırmasından sonra daha az sapmayla göreve odaklı kalıyor.
4. Gerçekten Uyarlanabilir Düşünme
Uyarlanabilir düşünme etkinleştirildiğinde, Opus 4.8 her turda akıl yürütmenin gerekip gerekmediğine karar verir. Basit aramalar doğrudan yanıtlanır. Karmaşık problemler önce akıl yürütmeyi, sonra yanıtı alır. Opus 4.7’ye göre daha az boşa harcanan token.
Bilinmeye Değer Yeni Özellikler
Efor Kontrolü — Artık Tüm Planlarda
Model seçiciyle birlikte yeni bir kontrol, kullanıcıların Claude’un yanıtına ne kadar çaba harcayacağını seçmesine olanak tanıyor. Opus 4.8 varsayılan olarak high (yüksek) eforla gelir; zorlu görevler için extra ve max seçenekleri mevcuttur. Claude Code’daki oran sınırları, artırılmış token kullanımıyla başa çıkmak için yükseltildi.
Hızlı Mod — 2.5x Hız, Daha Düşük Maliyet
Hızlı mod artık Claude API’sinde araştırma önizlemesi olarak Opus 4.8 için kullanılabilir. Önceki modellere kıyasla saniye başına 2,5 kat daha fazla çıktı token’ı üretirken üçte bir maliyetle çalışır.
Konuşma Ortasında Sistem Mesajları
Messages API artık mesaj dizisi içinde role: "system" girdilerini kabul ediyor. Bu sayede Claude’un talimatlarını görev sırasında, önbelleği bozmadan güncelleyebilirsiniz — bağlam veya izinler değiştiğinde faydalıdır.
Daha Düşük Ön Bellek Eşiği
Önbelleğe alınabilir minimum prompt uzunluğu 1.024 token’a düştü. Opus 4.7’de önbelleğe alınamayacak kadar kısa olan prompt’lar artık herhangi bir kod değişikliği olmadan önbelleğe kaydediliyor.
Gerçek Dünya Testleri
| Kıyaslama | Opus 4.8 Performansı |
|---|---|
| Super-Agent | Tüm senaryoları uçtan uca tamamladı (bunu yapan tek model) |
| CursorBench | Her efor seviyesinde tüm önceki Opus modellerini geçti |
| Online-Mind2Web | %84 (test edilen en güçlü model) |
| Legal Agent Benchmark | En yüksek puan; %10 toplam başarı eşiğini geçen ilk model |

Opus 4.8, uzun vadeli özerkliğin önemli olduğu yerlerde en güçlü performansı gösteriyor — kodlama ajanları, araştırma ajanları, hukuki iş akışları ve kurumsal bilgi çalışmaları.
Fiyatlandırma — Opus 4.7 ile Aynı
| Mod | Girdi | Çıktı |
|---|---|---|
| Standart | 1M token başına 5$ | 1M token başına 25$ |
| Hızlı | 1M token başına 10$ | 1M token başına 50$ |
Opus 4.7 ile aynı fiyat, ancak daha iyi performans. API üzerindeki model kimliği claude-opus-4-8. 1M token bağlam penceresini ve 128k maksimum çıktı token’ını destekliyor.
Sırada Ne Var: Mythos Sınıfı Modeller
Anthropic ayrıca “Opus’tan bile daha yüksek zekaya sahip” yeni bir model sınıfına da değindi. Az sayıda kuruluş, Claude Mythos Preview’u Project Glasswing aracılığıyla siber güvenlik çalışmalarında zaten kullanıyor. Şirket, gerekli güvenlik önlemleri tamamlandıktan sonra Mythos sınıfı modelleri önümüzdeki haftalarda tüm müşterilere sunmayı planlıyor.
Model Çeşitliliği Neden Önemli?
Artık her hafta yeni yapay zeka modelleri çıkıyor. Bu modellerin üzerine inşa eden geliştiriciler için asıl soru, “hangi model en iyisi” değil — “hangi model hangi görev için doğru” ve “bunlar arasında sorunsuz şekilde nasıl geçiş yapılır” olmalı.
İşte Felo AI bu sorunu çözüyor. Gelişmiş modellerden gerçek zamanlı yanıtlar çeken yapay zeka destekli aramasının ötesinde, Felo ayrıca LLM Playground adlı bir ortam sunuyor. Burada, önde gelen birçok modeli tek bir yerde çağırabilir, test edebilir ve sonuçlarını karşılaştırabilirsiniz. API anahtarlarıyla uğraşmak yok, paneller arasında geçiş yok. Sadece bir modeli seçin, prompt’unuzu çalıştırın ve performansını görün.
İş akışınıza uygun modelleri değerlendirirken veya sadece mevcut seçenekleri merak ederken, hepsini tek bir arayüzde görmek karşılaştırma sürecini çok daha kolaylaştırır.
Felo AI’yi Ücretsiz Dene → https://felo.ai
Bu yazı şu dillerde de mevcut: English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, Français, العربية, Русский, اردو, Bahasa Indonesia, Deutsch, Tiếng Việt, Italiano, ไทย, Español, বাংলা and Português.