Báo cáo Đánh giá Câu hỏi Mờ của Công cụ Tìm kiếm AI (v1.3)

Bài viết này đánh giá hiệu suất của một số công cụ tìm kiếm AI trong việc xử lý "câu hỏi truy vấn mờ." Felo AI đã thực hiện tốt nhất với tỷ lệ chính xác 80%, tiếp theo là Perplexity Pro. Bài viết phân tích những điểm mạnh và điểm yếu của từng sản phẩm và cung cấp các nghiên cứu trường hợp cụ thể để minh họa. Dữ liệu và kết quả đánh giá đã được mã nguồn mở, cung cấp những hiểu biết quý giá cho sự phát triển của các công cụ tìm kiếm AI.
I. Kết luận
Trong thời đại thông tin bão hòa ngày nay, khi các truy vấn của người dùng trở nên phức tạp hơn, khoảng cách hiệu suất giữa các hệ thống Tìm kiếm AI ngày càng rõ rệt. Điều này đặc biệt đúng khi xử lý các cấu hình phần mềm, nhiều nguồn dữ liệu, thông tin không có sẵn trực tuyến, hoặc các truy vấn liên quan đến ngày tháng. Chúng tôi gọi những truy vấn khó khăn này là "tìm kiếm câu hỏi mơ hồ." Trong đánh giá này, chúng tôi đã thử nghiệm toàn diện một số công cụ Tìm kiếm AI phổ biến, bao gồm Perplexity Basic, Perplexity Pro, GenSpark, Felo AI, iAsk, và You.com, tập trung vào loại truy vấn này.
Sau một loạt các bài kiểm tra nghiêm ngặt, chúng tôi đã kết luận:
- Felo AI nổi bật như là người thực hiện xuất sắc, thể hiện khả năng vượt trội trong việc xử lý các truy vấn mơ hồ. Nó dẫn đầu với tỷ lệ chính xác ấn tượng 80%, xử lý hiệu quả dữ liệu từ nhiều nguồn và cung cấp các câu trả lời chi tiết, đáng tin cậy cho các truy vấn phức tạp, giống như một chuyên gia dày dạn kinh nghiệm.
- Perplexity Pro đứng thứ hai với điểm số 70%, cho thấy khả năng kiên cường trong việc giải quyết một số câu hỏi phức tạp.
- iAsk thực hiện ở mức độ chấp nhận được, đạt tỷ lệ chính xác 60% và đôi khi cung cấp các câu trả lời hiệu quả cho các câu hỏi mơ hồ.
- Perplexity Basic, GenSpark, và You.com thể hiện hiệu suất kém trong đánh giá này. Các mô hình ngôn ngữ của họ cho thấy những điểm yếu rõ rệt trong việc hiểu và xử lý các truy vấn mơ hồ, đạt tỷ lệ chính xác lần lượt là 55%, 45%, và 35%, điều này không đạt yêu cầu.
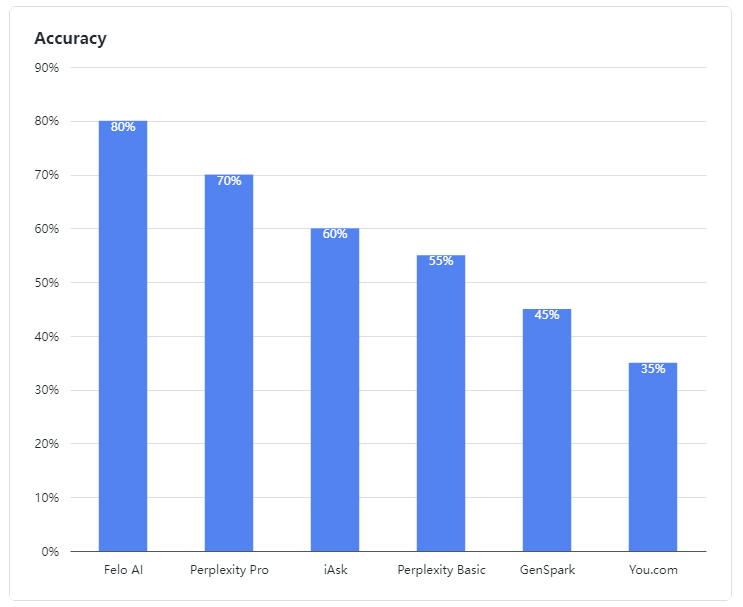
Hình 1: Tỷ lệ chính xác của các sản phẩm được đánh giá
II. Dữ liệu đánh giá
Trong đánh giá của chúng tôi, các câu hỏi mơ hồ được định nghĩa là những câu hỏi liên quan đến cấu hình phần mềm, nhiều nguồn dữ liệu, thông tin không có sẵn trực tuyến, hoặc thông tin liên quan đến ngày tháng. Các LLM thường kết hợp nội dung từ nhiều nguồn để trả lời những câu hỏi như vậy.
Các trường hợp thử nghiệm câu hỏi mơ hồ của chúng tôi là mã nguồn mở:
👉 Các trường hợp thử nghiệm: https://github.com/sparticleinc/ASEED/blob/main/datasets/ambiguity_search.csv
👉 Kết quả thử nghiệm: https://github.com/sparticleinc/ASEED/tree/main/evaluations/promptfoo/ambiguity_search
III. Phân tích trường hợp
👉 Câu hỏi: Các kỳ Olympic tiếp theo sẽ được tổ chức ở đâu?
Sự thật cơ bản: Các kỳ Olympic Mùa hè 2028, còn được gọi là Thế vận hội XXXIV, sẽ được tổ chức tại Los Angeles, Hoa Kỳ.
Bình luận: Do sự phong phú của thông tin trực tuyến cho biết rằng Olympic tiếp theo sẽ được tổ chức tại Paris, Pháp vào năm 2024, tất cả các sản phẩm ngoại trừ Felo AI đã trả lời sai.

