Claude Opus 4.8 ra mắt: Mô hình mạnh mẽ nhất của Anthropic cho đến nay

Anthropic vừa ra mắt Claude Opus 4.8 — nhanh hơn, trung thực hơn và tốt hơn trong các tác vụ tác nhân. Dưới đây là tất cả những điểm mới và lý do tại sao điều đó quan trọng với các nhà phát triển.

Anthropic đã phát hành Claude Opus 4.8 trong tuần này. Đây là mô hình mạnh mẽ nhất mà họ từng phát hành rộng rãi, được phát triển dựa trên Opus 4.7 với những cải tiến trong lập trình, suy luận, tác vụ tác nhân và độ trung thực. Mức giá vẫn giữ nguyên: $5 cho mỗi triệu token đầu vào và $25 cho mỗi triệu token đầu ra.
Dưới đây là những thay đổi và lý do chúng quan trọng đối với các nhà phát triển xây dựng trên nền tảng này.
Những thay đổi so với Opus 4.7
Dưới đây là những gì thực sự đã thay đổi:
1. Đánh giá và trung thực tốt hơn
Opus 4.8 giảm đáng kể khả năng đưa ra các tuyên bố vô căn cứ hoặc để lọt lỗi mã mà không nhận ra. Các đánh giá nội bộ của Anthropic cho thấy nó ít có khả năng cho phép lỗi trong mã của chính mình hơn khoảng bốn lần so với phiên bản trước. Đây là loại cải tiến quan trọng khi bạn cần tin tưởng một mô hình hoạt động tự động.
Những người thử nghiệm sớm báo cáo rằng mô hình này đặt ra những câu hỏi đúng, tự phát hiện lỗi của mình và phản biện lại khi một kế hoạch không hợp lý.
2. Hiệu suất tác nhân mạnh mẽ hơn
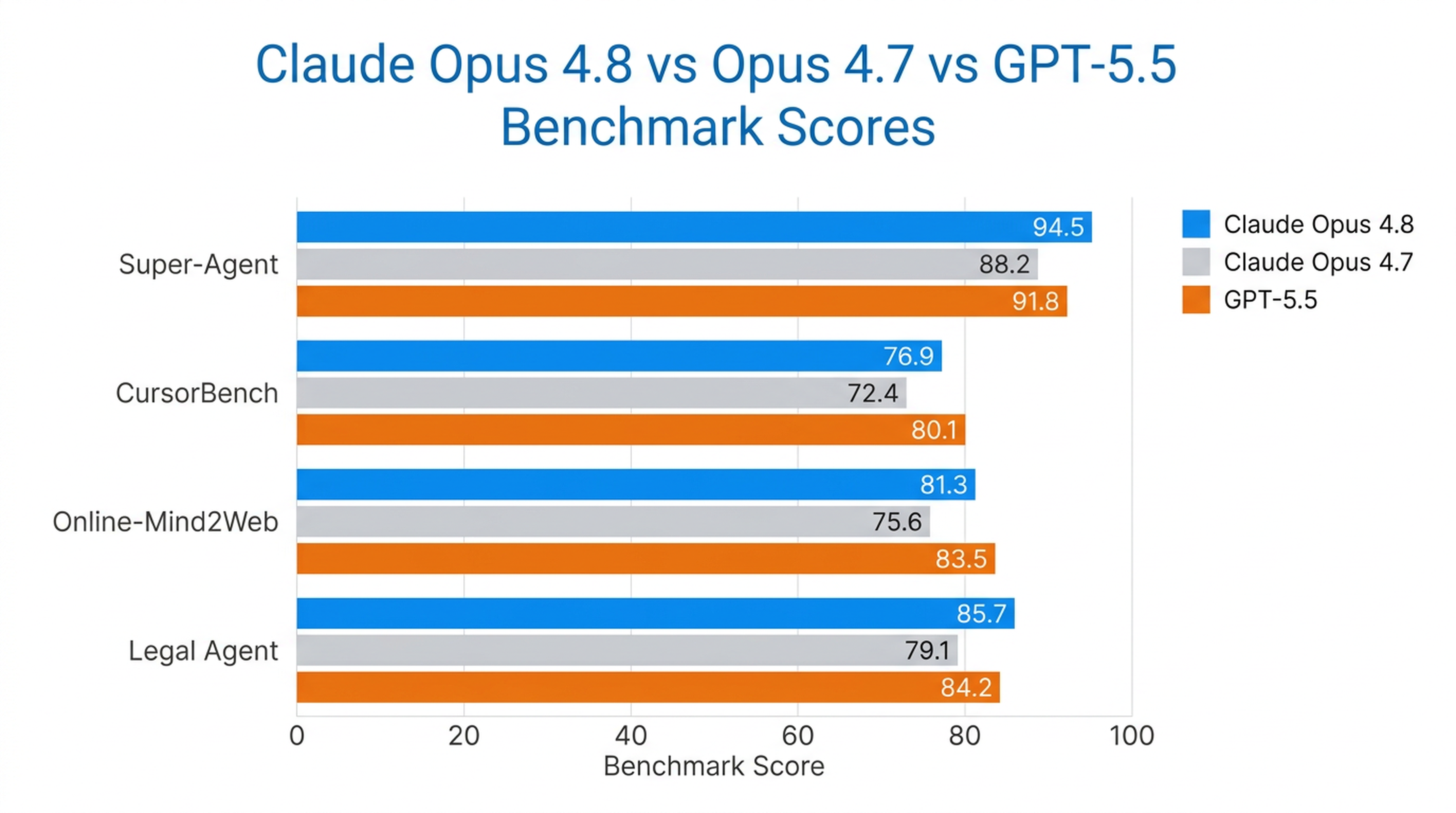
Opus 4.8 là mô hình duy nhất hoàn thành mọi trường hợp từ đầu đến cuối trong bài kiểm tra Super-Agent của Anthropic, vượt qua các phiên bản Opus trước và GPT-5.5 với chi phí tương đương. Ở CursorBench, nó vượt trội hơn các phiên bản Opus trước trong mọi mức độ nỗ lực, sử dụng ít bước gọi công cụ hơn cho cùng một mức thông minh.
Đây cũng là mô hình sử dụng máy tính và trình duyệt mạnh mẽ nhất mà Anthropic từng thử nghiệm, đạt 84% trong Online-Mind2Web.
3. Gọi công cụ nhanh hơn và hiệu quả hơn
Mô hình ít bỏ qua các bước gọi công cụ cần thiết hơn — vấn đề từng tồn tại ở Opus 4.7. Các chuỗi tác vụ tác nhân dài cũng duy trì mục tiêu tốt hơn, ít bị chệch hướng sau khi nén ngữ cảnh.
4. Tư duy thích ứng thực sự linh hoạt
Khi bật tư duy thích ứng, Opus 4.8 sẽ quyết định theo từng lượt xem có cần suy luận hay không. Các truy vấn đơn giản được trả lời trực tiếp, trong khi vấn đề phức tạp sẽ được suy luận trước khi trả lời. Giảm lãng phí token so với Opus 4.7.
Các tính năng mới đáng chú ý
Điều khiển mức độ nỗ lực — có sẵn trên mọi gói
Một tùy chọn mới bên cạnh trình chọn mô hình cho phép người dùng chọn mức độ nỗ lực mà Claude bỏ ra cho một phản hồi. Opus 4.8 mặc định ở mức high, với các lựa chọn extra và max cho các tác vụ khó hơn. Giới hạn tốc độ trong Claude Code đã được tăng lên để đáp ứng việc sử dụng token cao hơn.
Chế độ nhanh — tốc độ gấp 2.5 lần, chi phí thấp hơn
Chế độ nhanh hiện có sẵn cho Opus 4.8 dưới dạng bản thử nghiệm trong Claude API. Nó cung cấp tốc độ sinh token đầu ra cao hơn đến 2.5× với chi phí rẻ hơn ba lần so với các mô hình trước.
Tin nhắn hệ thống trong giữa cuộc hội thoại
API Messages hiện hỗ trợ các mục có role: "system" trong mảng tin nhắn. Bạn có thể cập nhật hướng dẫn của Claude giữa quá trình thực hiện tác vụ mà không làm mất bộ nhớ đệm gợi ý — rất hữu ích khi quyền hạn hoặc ngữ cảnh thay đổi trong vòng lặp tác nhân.
Giảm chiều dài tối thiểu của bộ nhớ đệm gợi ý
Chiều dài gợi ý tối thiểu có thể lưu bộ nhớ đệm được giảm xuống 1.024 token. Các gợi ý quá ngắn để lưu trong Opus 4.7 giờ đây có thể tạo bộ nhớ đệm mà không cần thay đổi mã.
Hiệu suất thực tế
| Bài kiểm tra | Hiệu suất của Opus 4.8 |
|---|---|
| Super-Agent | Hoàn thành tất cả trường hợp từ đầu đến cuối (mô hình duy nhất làm được) |
| CursorBench | Vượt qua tất cả các phiên bản Opus trước ở mọi mức độ nỗ lực |
| Online-Mind2Web | 84% (mô hình được thử nghiệm mạnh nhất) |
| Legal Agent Benchmark | Điểm số cao nhất từng ghi nhận; mô hình đầu tiên vượt mốc 10% tổng thể |

Opus 4.8 hoạt động mạnh nhất trong các tình huống yêu cầu tự chủ dài hạn — tác nhân lập trình, nghiên cứu, quy trình pháp lý và công việc tri thức doanh nghiệp.
Giá — giữ nguyên như Opus 4.7
| Chế độ | Đầu vào | Đầu ra |
|---|---|---|
| Tiêu chuẩn | $5 / 1M token | $25 / 1M token |
| Nhanh | $10 / 1M token | $50 / 1M token |
Giá không đổi so với Opus 4.7, nhưng hiệu suất tốt hơn. ID mô hình trên API là claude-opus-4-8. Nó hỗ trợ cửa sổ ngữ cảnh 1 triệu token và đầu ra tối đa 128 nghìn token.
Tiếp theo: Dòng mô hình Mythos-Class
Anthropic cũng hé lộ một dòng mô hình mới với “trí thông minh còn cao hơn Opus.” Một số tổ chức đã sử dụng Claude Mythos Preview cho các tác vụ an ninh mạng thông qua Dự án Glasswing. Công ty có kế hoạch mở rộng dòng mô hình Mythos đến tất cả khách hàng trong vài tuần tới, sau khi hoàn tất các biện pháp bảo vệ.
Vì sao sự đa dạng mô hình lại quan trọng
Các mô hình AI mới ra mắt gần như mỗi tuần. Với các nhà phát triển, câu hỏi thực sự không phải là mô hình nào “tốt nhất” — mà là mô hình nào phù hợp nhất với từng tác vụ, và cách chuyển đổi giữa chúng một cách mượt mà.
Đó chính là vấn đề mà Felo AI giải quyết. Ngoài công cụ tìm kiếm do AI hỗ trợ, cung cấp câu trả lời theo thời gian thực từ các mô hình tiên tiến, Felo còn mang đến LLM Playground — nơi bạn có thể gọi, thử nghiệm và so sánh đầu ra từ nhiều mô hình hàng đầu ở cùng một chỗ. Không cần xoay vòng API key hay thay đổi bảng điều khiển. Chỉ cần chọn một mô hình, nhập gợi ý và xem kết quả.
Nếu bạn đang đánh giá các mô hình cho quy trình làm việc, hoặc chỉ đơn giản tò mò về những gì đang có, việc có tất cả trong cùng một giao diện sẽ giúp quá trình so sánh dễ dàng hơn nhiều.
Dùng thử Felo AI miễn phí → https://felo.ai
Bài viết này cũng có sẵn bằng English, 简体中文, 日本語, 한국어, 繁體中文, हिन्दी, Français, العربية, Русский, اردو, Bahasa Indonesia, Deutsch, Türkçe, Italiano, ไทย, Español, বাংলা and Português.