Cách sử dụng các mô hình lập luận OpenAI: mô hình o1-preview/o1-Mini - Trò chuyện AI miễn phí

Felo AI Chat hiện hỗ trợ sử dụng miễn phí mô hình lập luận O1
Trong bối cảnh trí tuệ nhân tạo đang phát triển nhanh chóng, OpenAI đã giới thiệu một loạt mô hình ngôn ngữ lớn mang tính đột phá được gọi là loạt o1. Những mô hình này được thiết kế để thực hiện các nhiệm vụ suy luận phức tạp, khiến chúng trở thành công cụ mạnh mẽ cho cả nhà phát triển và nhà nghiên cứu. Trong bài viết trên blog này, chúng ta sẽ khám phá cách sử dụng hiệu quả các mô hình suy luận của OpenAI, tập trung vào khả năng, giới hạn và các phương pháp tốt nhất để triển khai.
Felo AI Chat hiện hỗ trợ sử dụng miễn phí mô hình Suy luận O1. Hãy thử ngay!!


Hiểu về các Mô hình OpenAI o1
Các mô hình loạt o1 khác biệt so với các phiên bản trước của mô hình ngôn ngữ OpenAI nhờ phương pháp đào tạo độc đáo của chúng. Chúng sử dụng học tăng cường để nâng cao khả năng suy luận, cho phép chúng suy nghĩ một cách phản biện trước khi tạo ra phản hồi. Quy trình tư duy nội bộ này cho phép các mô hình tạo ra một chuỗi suy luận dài, điều này đặc biệt có lợi cho việc giải quyết các vấn đề phức tạp.
Các Tính năng Chính của Mô hình OpenAI o1
1. **Suy luận Nâng cao**: Các mô hình o1 xuất sắc trong suy luận khoa học, đạt được kết quả ấn tượng trong lập trình cạnh tranh và các tiêu chuẩn học thuật. Ví dụ, chúng đứng ở phần trăm 89 trên Codeforces và đã thể hiện độ chính xác ở cấp độ Tiến sĩ trong các môn như vật lý, sinh học và hóa học.
2. **Hai Biến thể**: OpenAI cung cấp hai phiên bản của các mô hình o1 thông qua API của họ:
- **o1-preview**: Đây là phiên bản đầu tiên được thiết kế để giải quyết các vấn đề khó khăn bằng cách sử dụng kiến thức tổng quát rộng.
- **o1-mini**: Một biến thể nhanh hơn và tiết kiệm chi phí hơn, đặc biệt phù hợp cho các nhiệm vụ lập trình, toán học và khoa học không yêu cầu kiến thức tổng quát rộng lớn.
3. **Cửa sổ Ngữ cảnh**: Các mô hình o1 đi kèm với một cửa sổ ngữ cảnh lớn 128.000 token, cho phép nhập liệu và suy luận rộng rãi. Tuy nhiên, việc quản lý ngữ cảnh này một cách hiệu quả là rất quan trọng để tránh chạm vào giới hạn token.
Bắt đầu với các Mô hình OpenAI o1
Để bắt đầu sử dụng các mô hình o1, các nhà phát triển có thể truy cập chúng thông qua điểm hoàn thành trò chuyện của API OpenAI.
Bạn đã sẵn sàng nâng cao trải nghiệm tương tác AI của mình chưa? Felo AI Chat hiện cung cấp cơ hội khám phá mô hình Suy luận O1 tiên tiến mà không tốn phí!
Hãy thử miễn phí mô hình suy luận o1.
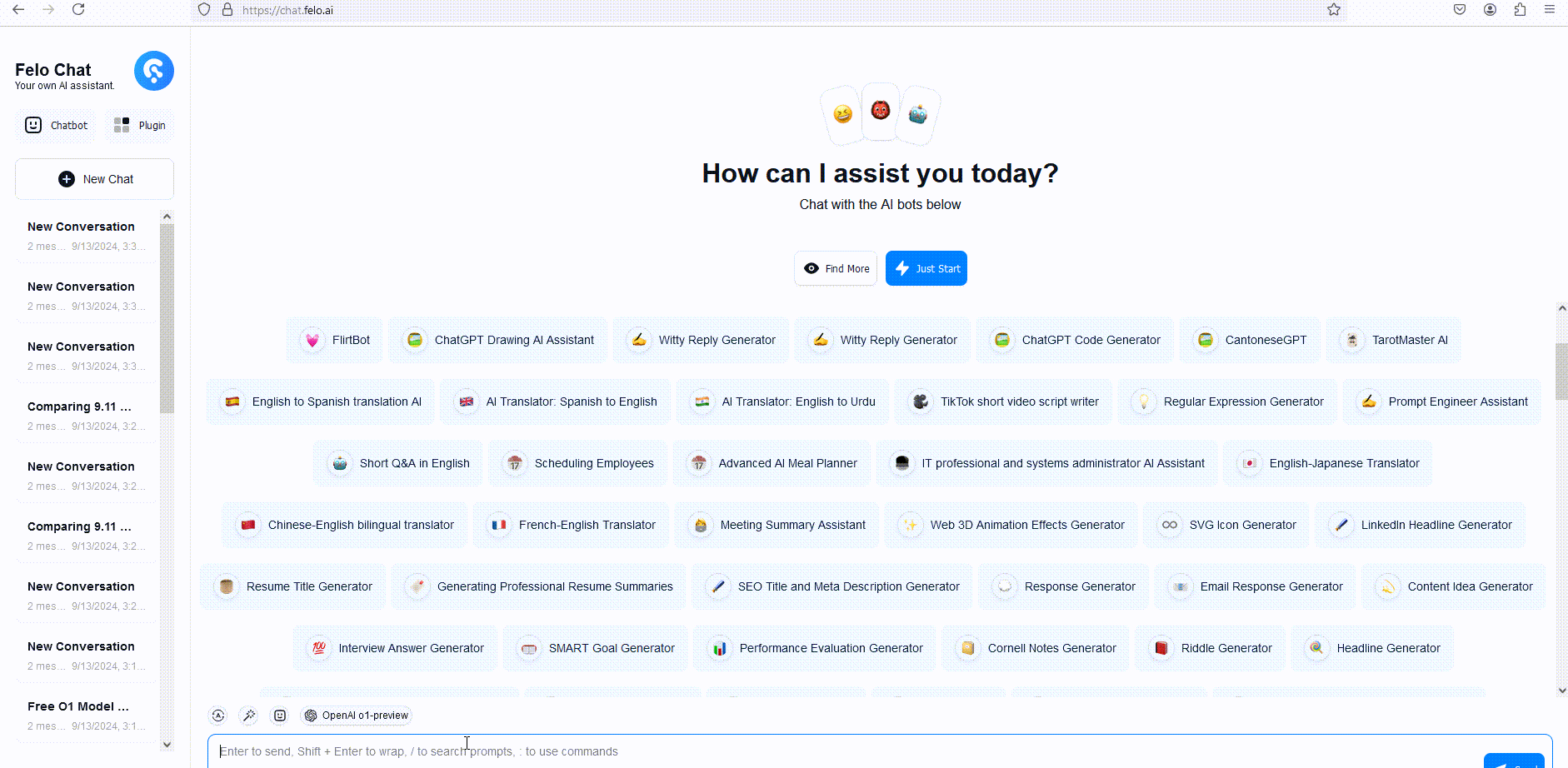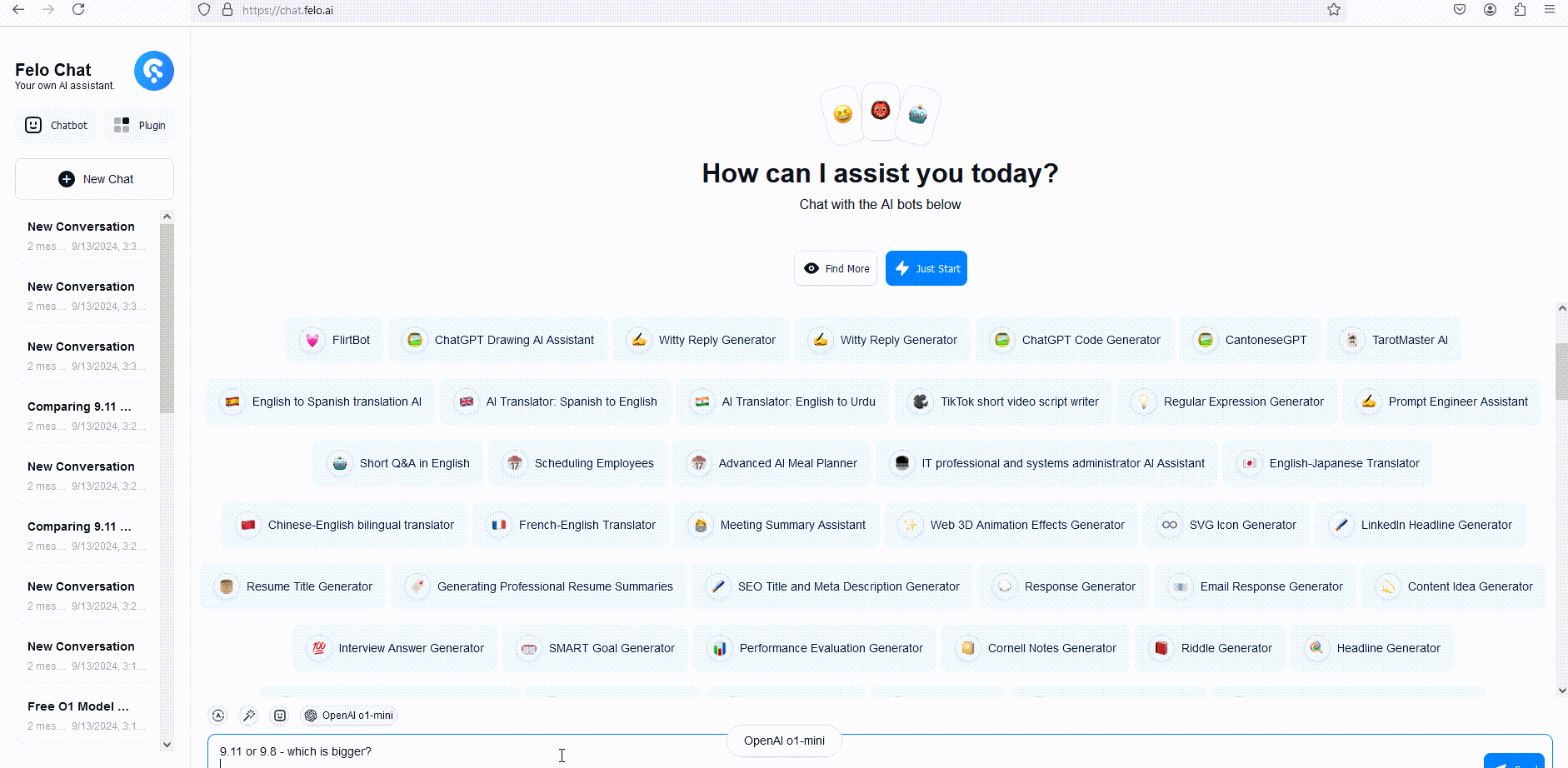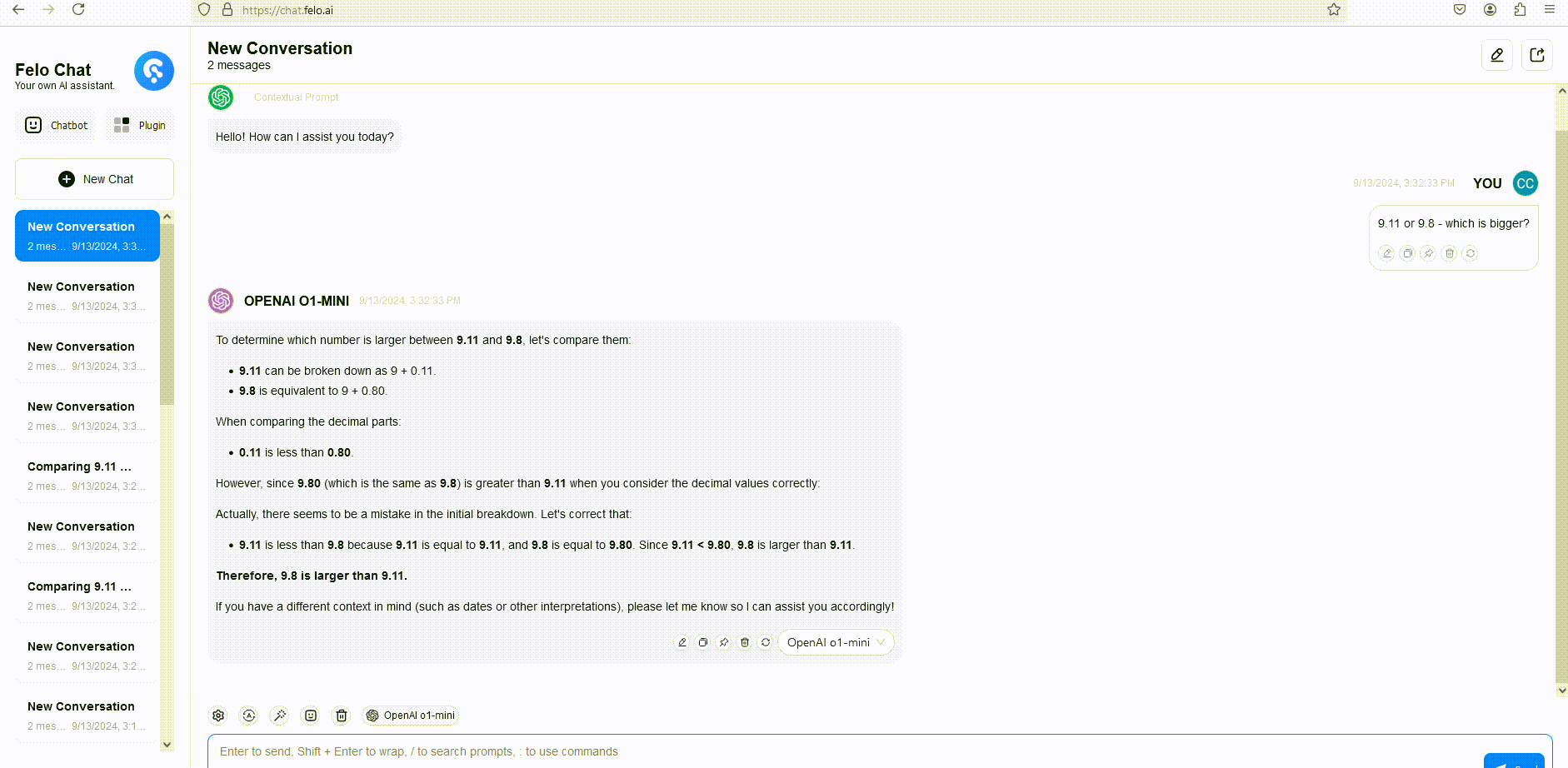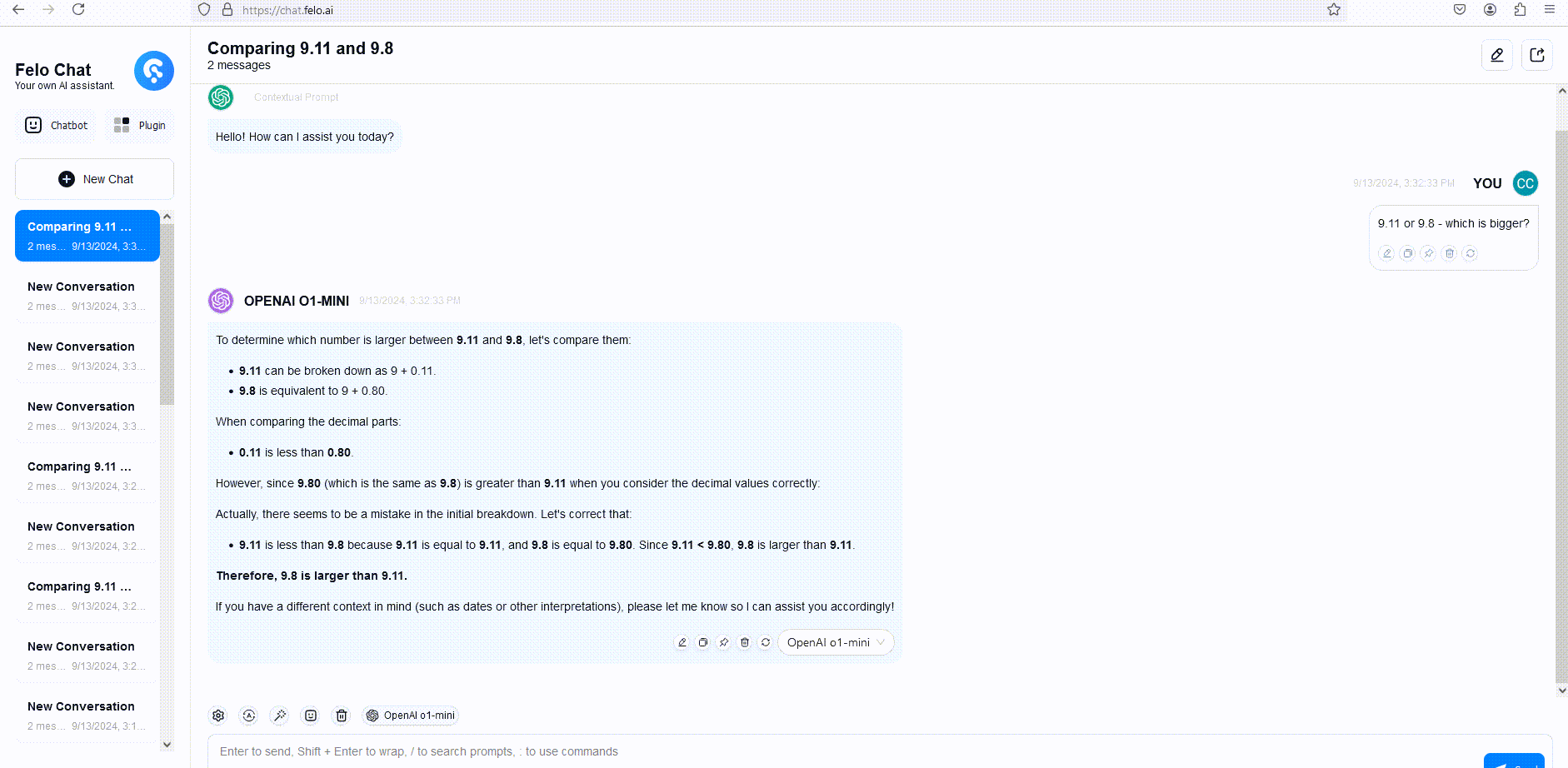
Giới hạn Beta của Mô hình OpenAI o1
Điều quan trọng cần lưu ý là các mô hình o1 hiện đang trong giai đoạn beta, có nghĩa là có một số giới hạn cần lưu ý:
Trong giai đoạn beta, nhiều tham số API hoàn thành trò chuyện vẫn chưa có sẵn. Đặc biệt:
- Chế độ: chỉ văn bản, hình ảnh không được hỗ trợ.
- Loại tin nhắn: chỉ tin nhắn của người dùng và trợ lý, tin nhắn hệ thống không được hỗ trợ.
- Phát trực tiếp: không được hỗ trợ.
- Công cụ: các tham số công cụ, gọi hàm và định dạng phản hồi không được hỗ trợ.
- Logprobs: không được hỗ trợ.
- Khác:
temperature,top_pvànđược cố định ở1, trong khipresence_penaltyvàfrequency_penaltyđược cố định ở0. - Trợ lý và Lô: các mô hình này không được hỗ trợ trong API Trợ lý hoặc API Lô.
**Quản lý Cửa sổ Ngữ cảnh**:
Với một cửa sổ ngữ cảnh 128.000 token, việc quản lý không gian một cách hiệu quả là rất cần thiết. Mỗi hoàn thành có giới hạn token đầu ra tối đa, bao gồm cả token suy luận và token hoàn thành hiển thị. Ví dụ:
- **o1-preview**: Tối đa 32.768 token
- **o1-mini**: Tối đa 65.536 token
Tốc độ của Mô hình OpenAI o1
Để minh họa, chúng tôi đã so sánh phản hồi của GPT-4o, o1-mini và o1-preview với một câu hỏi suy luận từ vựng. Mặc dù GPT-4o đã cung cấp một câu trả lời không chính xác, cả o1-mini và o1-preview đều trả lời đúng, với o1-mini đến được câu trả lời đúng nhanh hơn khoảng 3-5 lần.

Cách chọn giữa các mô hình GPT-4o, O1 Mini và O1 Preview?
**O1 Preview**: Đây là phiên bản đầu tiên của mô hình O1 OpenAI, được thiết kế để tận dụng kiến thức tổng quát rộng lớn cho việc suy luận qua các vấn đề phức tạp.
**O1 Mini**: Một phiên bản nhanh hơn và tiết kiệm hơn của O1, đặc biệt tốt cho các nhiệm vụ lập trình, toán học và khoa học, lý tưởng cho các tình huống không yêu cầu kiến thức tổng quát rộng lớn.
Các mô hình O1 cung cấp những cải tiến đáng kể trong suy luận nhưng không nhằm thay thế GPT-4o trong tất cả các trường hợp sử dụng.
Đối với các ứng dụng cần đầu vào hình ảnh, gọi hàm, hoặc thời gian phản hồi nhanh liên tục, các mô hình GPT-4o và GPT-4o Mini vẫn là lựa chọn tốt nhất. Tuy nhiên, nếu bạn đang phát triển các ứng dụng yêu cầu suy luận sâu và có thể chấp nhận thời gian phản hồi lâu hơn, các mô hình O1 có thể là sự lựa chọn tuyệt vời.
Mẹo cho việc Gợi ý Hiệu quả với các mô hình O1 Mini và O1 Preview
Các Mô hình OpenAI o1 hoạt động tốt nhất với các gợi ý rõ ràng và đơn giản. Một số kỹ thuật, chẳng hạn như gợi ý ít-shot hoặc yêu cầu mô hình "suy nghĩ từng bước một," có thể không cải thiện hiệu suất và thậm chí có thể cản trở nó. Dưới đây là một số phương pháp tốt nhất để thực hiện:
1. **Giữ Gợi ý Đơn giản và Trực tiếp**: Các mô hình hiệu quả nhất khi được cung cấp các hướng dẫn ngắn gọn, rõ ràng mà không cần giải thích dài dòng.
2. **Tránh Gợi ý Chuỗi Suy nghĩ**: Vì các mô hình này xử lý suy luận nội bộ, không cần phải yêu cầu chúng "suy nghĩ từng bước một" hoặc "giải thích lý do của bạn."
3. **Sử dụng Dấu phân cách để Rõ ràng**: Sử dụng các dấu phân cách như dấu ngoặc kép ba, thẻ XML, hoặc tiêu đề phần để xác định rõ ràng các phần khác nhau của đầu vào, điều này giúp mô hình diễn giải mỗi phần một cách chính xác.
4. **Giới hạn Ngữ cảnh Bổ sung trong Tạo ra Dữ liệu Tăng cường (RAG)**: Khi cung cấp ngữ cảnh hoặc tài liệu bổ sung, chỉ bao gồm thông tin quan trọng nhất để tránh làm phức tạp phản hồi của mô hình.
Giá cho các mô hình o1 Mini và 1 Preview.
Cách tính chi phí cho các mô hình o1 Mini và 1 Preview khác với các mô hình khác, vì nó bao gồm một chi phí bổ sung cho các token suy luận.
Giá o1-mini
$3.00 / 1M token đầu vào
$12.00 / 1M token đầu ra
Giá o1-preview
$15.00 / 1M token đầu vào
$60.00 / 1M token đầu ra
Quản lý Chi phí Mô hình o1-preview/ o1-mini
Để kiểm soát chi phí với các mô hình loạt o1, bạn có thể sử dụng tham số `max_completion_tokens` để đặt giới hạn cho tổng số token mà mô hình tạo ra, bao gồm cả token suy luận và token hoàn thành.
Trong các mô hình trước đây, tham số `max_tokens` quản lý cả số lượng token được tạo ra và số lượng token hiển thị cho người dùng, mà luôn giống nhau. Tuy nhiên, với loạt o1, tổng số token được tạo ra có thể vượt quá số token hiển thị cho người dùng do các token suy luận nội bộ.
Bởi vì một số ứng dụng phụ thuộc vào việc `max_tokens` khớp với số token nhận được từ API, loạt o1 giới thiệu `max_completion_tokens` để kiểm soát cụ thể tổng số token được sản xuất bởi mô hình, bao gồm cả token suy luận và token hoàn thành hiển thị. Việc chọn tham số này một cách rõ ràng đảm bảo rằng các ứng dụng hiện có vẫn tương thích với các mô hình mới. Tham số `max_tokens` tiếp tục hoạt động như đã làm cho tất cả các mô hình trước đây.
Kết luận
Các mô hình loạt o1 của OpenAI đại diện cho một bước tiến đáng kể trong lĩnh vực trí tuệ nhân tạo, đặc biệt là trong khả năng thực hiện các nhiệm vụ suy luận phức tạp. Bằng cách hiểu rõ khả năng, giới hạn và các phương pháp tốt nhất để sử dụng, các nhà phát triển có thể khai thác sức mạnh của những mô hình này để tạo ra các ứng dụng sáng tạo. Khi OpenAI tiếp tục hoàn thiện và mở rộng loạt o1, chúng ta có thể mong đợi nhiều phát triển thú vị hơn trong lĩnh vực suy luận dựa trên AI. Dù bạn là một nhà phát triển dày dạn kinh nghiệm hay mới bắt đầu, các mô hình o1 cung cấp một cơ hội độc đáo để khám phá tương lai của các hệ thống thông minh. Chúc bạn lập trình vui vẻ!
Felo AI Chat luôn mang đến cho bạn trải nghiệm miễn phí với các mô hình AI tiên tiến từ khắp nơi trên thế giới. Nhấn vào đây để thử ngay!