在 Felo LLM Playground 免费试用 DeepSeek V4

Felo LLM Playground 在上线当天新增了 DeepSeek V4-Pro 和 V4-Flash。与万亿参数的开源模型免费聊天——无需 API 密钥。
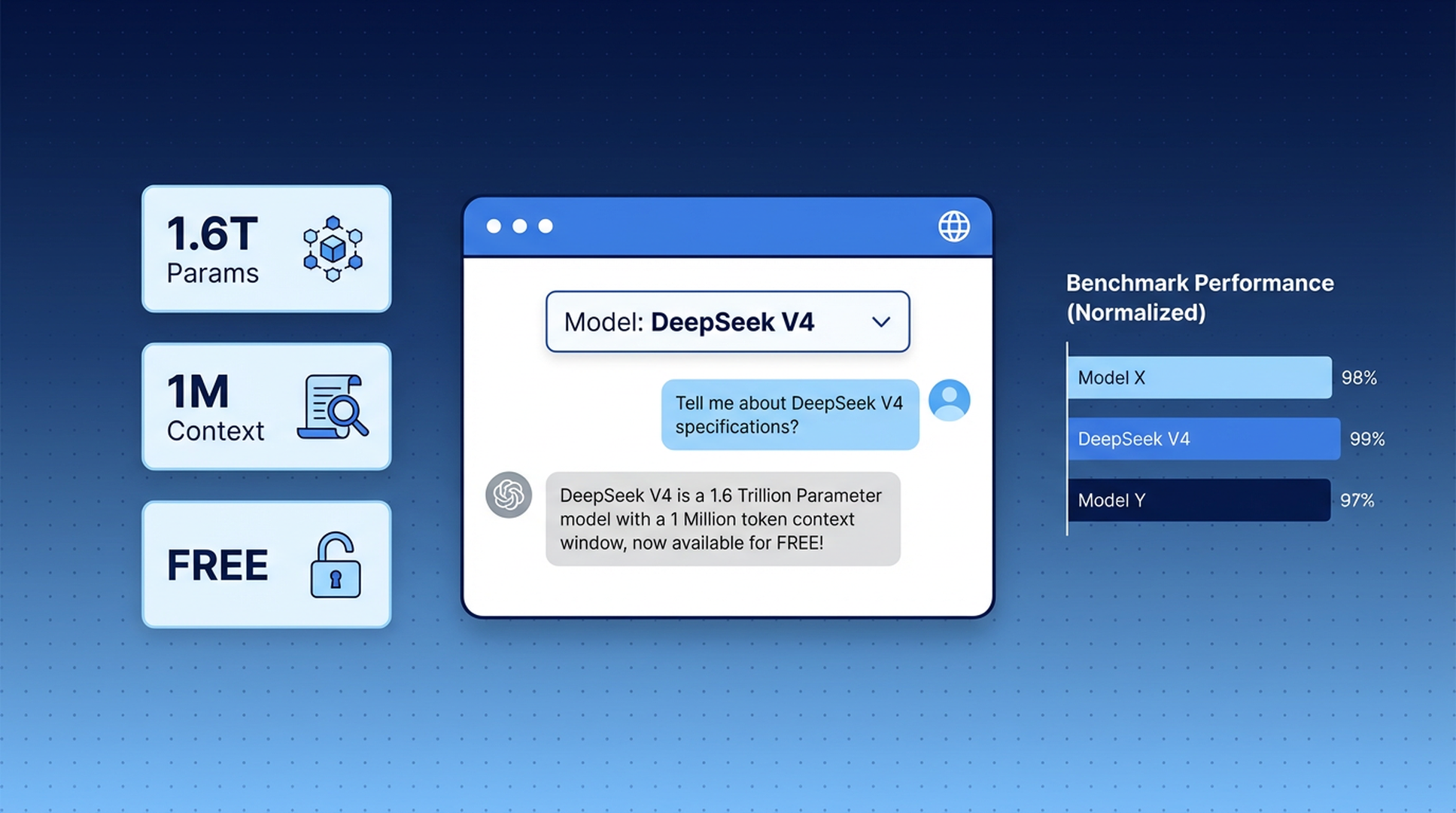
DeepSeek V4 于本周发布——这是一款拥有万亿参数的开源模型,在大多数基准测试中可与 GPT-5.4 和 Claude Opus 4.6 媲美。它是迄今为止发布的最强开源权重模型。
你现在就可以在 Felo LLM Playground 上免费与它聊天。无需 API 密钥、积分或账户。只需选择模型并开始对话。
什么是 Felo LLM Playground?
Felo LLM Playground 是一个免费的、基于浏览器的聊天界面,您可以在这里与全球领先的 AI 模型并排交流。可以把它看作是 LLM 的测试厨房——你提出问题,然后选择哪个模型来回答。
Playground 目前支持来自 OpenAI、Anthropic、Google,以及现在的 DeepSeek 的模型。你可以在对话中切换模型、比较回答,并找出哪个模型最适合你的特定任务——这一切都不需要注册单独的 API 账户或管理账单。
它为任何想要无障碍体验最新模型的人而设计。无论是为项目评估模型的开发者,比较推理质量的研究人员,需要强大 AI 助手但又不想为每个服务提供商每月支付 20 美元的学生,还是只是对使用万亿参数模型的感觉感到好奇的任何人。
DeepSeek V4:你将获得的访问权限
DeepSeek V4 提供两个版本,两个版本都可在 Playground 上使用:
DeepSeek V4-Pro 是完整型号。总参数为 1.6 万亿,每次查询激活 490 亿个参数,基于 32 万亿个 token 进行训练。它在复杂推理、编程、数学以及长文档分析方面的表现可与最优秀的闭源模型直接竞争。
DeepSeek V4-Flash 是高速版本。总参数为 2840 亿,激活参数为 130 亿。它能为日常问题提供快速且高质量的回答,而无须承受大型模型带来的延迟。
两者均拥有一百万 token 的上下文窗口——足以在一次对话中处理整个代码库、一份书籍长度的文档,或数月的会议记录。
性能对比
以下是 V4-Pro 与当前顶级模型的对比表现:
| 基准测试 | DeepSeek V4-Pro | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|---|
| MMLU | 90.1% | 约 91% | 约 89% |
| HumanEval | 76.8% | 约 78% | 约 77% |
| SWE-bench Verified | 80.6% | 约 82% | 约 80% |
| Codeforces 评分 | 3,206 | 约 3,100 | 约 2,900 |
| MATH | 64.5% | 约 66% | 约 63% |
V4-Pro 在竞赛编程中领先,并在多个编程任务上与 GPT-5.4 相当或优于它。其扩展推理模式(V4-Pro-Max)在 LiveCodeBench 上获得 93.5%,在 IMOAnswerBench 上获得 89.8% 的成绩。
开源模型和闭源模型之间的差距从未如此之小。在某些任务上,这种差距甚至完全消失。
如何在 Playground 上使用 DeepSeek V4
大约只需五秒钟:
1. 打开 Playground。
在浏览器中访问 playground.felo.ai。无需登录。
2. 在模型选择器中选择 DeepSeek V4。
你会看到一个包含所有可用模型的下拉菜单。对于复杂任务,选择 V4-Pro;若想快速获得答案,选择 V4-Flash。
3. 开始聊天。
自然地输入你的问题。模型会实时响应,就像你之前使用过的任何聊天界面一样。
这就是整个设置。无需配置 API 密钥、令牌预算或账单页面。
值得一试的几件事
如果你不确定从哪里开始,以下是一些展示 V4 能力的提示:
- 粘贴一份较长的代码文件,让 V4-Pro 查找错误或提出重构建议
- 给它出一道数学题——如果想挑战它,可以试试竞赛级别的问题
- 让它以特定的方式解释一个技术概念(例如:“像我是数据库工程师一样解释 Transformer”)
- 输入一篇研究论文的摘要,让它进行批判性分析
- 在 V4-Pro 和 GPT-5.4 上使用相同的提示并排比较——Playground 让这一切变得简单
何时选择 V4-Pro 与 V4-Flash
这两个模型都可以在 Playground 中使用,选择它们其实很简单。
V4-Pro 适用于较困难的问题。用于研究综合、调试复杂代码、数学证明、分析长文档,或任何需要深度推理的工作。它速度较慢,但思考得更深入。
V4-Flash 适用于其他所有情况。快速事实查询、文本草拟、头脑风暴、翻译、摘要等。它响应更快,处理日常任务的表现与大型模型一样好。如果你在一次会话中要提出很多问题,V4-Flash 能让交流持续顺畅。
一个简单的经验法则:先用 V4-Flash。如果答案显得浅显,或任务明显复杂,再切换到 V4-Pro。Playground 允许你在对话中途切换模型,因此尝试不同模型不会有任何损失。
为什么 Playground 对测试新模型很重要
每当有新模型发布时,总会出现同一个问题:该如何真正试用它?
官方 API 需要注册账号、绑定信用卡、编写代码发起请求、并管理令牌成本。如果你要将模型集成到产品中,这没问题。但如果你只是想随便问几个问题,看看它的思考方式,就太麻烦了。
Felo LLM Playground 消除了整个过程。新模型发布后,你只需打开一个浏览器标签页,就能使用它。无需配置、无需花费、无需承诺。
这件事比听起来更重要。“我应该试试那个新模型”和真正去试之间,通常隔着 20 分钟的账户注册和 API 配置过程。而 Playground(模型试玩台)把这段过程直接减到了零。
它还让模型之间的对比变得切实可行。想知道 DeepSeek V4 在你的使用场景中是否比 Claude 或 GPT 表现更好吗?只需在相邻的标签页中向每个模型提出同一个问题。五分钟的实测体验,比阅读基准测试表能让你学到更多。
为什么值得尝试 DeepSeek V4
除了基准分数之外,V4 还有几个非常值得亲身体验的特点:
三种推理模式。 V4 提供 Non-Think(快速、直接回答)、Think High(逐步分析)和 Think Max(最大推理努力)三种模式。你能感受到差别——在困难的数学问题上,Think Max 模式会比默认模式产出明显更全面的结果。在 Playground 上,这意味着你可以调整模型在回答问题时投入的算力。快速的事实核对不需要 Think Max 模式,而棘手的证明问题则适合使用它。
强大的多语言能力。 V4 的训练重点强化了多语言数据。如果你在多语言环境中工作——英语与中文、日语与韩语,或任意组合——V4 能很好地处理语言切换和跨语言问题。用英语询问一篇中文资料,它依然能流畅应答。
编码能力。 V4-Pro 在 Codeforces 上的评级为 3,206,SWE-bench 得分为 80.6%,是目前你能使用的最强编码模型之一。让它编写函数、审查拉取请求,或解释为什么你的正则表达式没有匹配——它表现始终出色。Playground 是快速验证这一点的好方法:粘贴一段代码,请它审查,并把 V4 的反馈与 Claude 或 GPT 比较。
百万级上下文窗口。 大多数模型的上限是 128K 或 200K tokens,而 V4 可以处理一百万个。这大约相当于 75 万个英文单词——相当于 10 部完整小说,或一家中型公司的全部内部文档。你可以粘贴整个项目的代码库并直接提问,而无需先分块或摘要。之前的模型要求你把内容拆开处理,V4 则能整体接收。
Playground上的实际使用案例
以下是人们已经在Playground上使用DeepSeek V4的一些方式:
开发者会粘贴代码并请求V4-Pro进行审查、提出优化建议或解释不熟悉的模式。百万级上下文令牌意味着你可以放入整个模块——不仅是单个函数——并获得基于整体视角的反馈。一些开发者使用V4-Flash来快速解决语法问题,而使用V4-Pro进行架构级讨论。
学生使用V4-Pro-Max来解决数学和科学题目集。“Think Max”推理模式会逐步演示证明过程,这不仅有助于得到答案,还能帮助理解思路。它还擅长以不同层次解释概念——例如让它向一年级学生和博士生分别解释梯度下降,你将得到真正有区分的回答。
研究人员向V4输入论文摘要或完整章节,并请求进行批判性分析、找出方法论漏洞或关联相关研究。多语言训练在这里也很有用——V4可以处理中文、日文或韩文的资料,并以英文进行讨论而不失细微差别。
作家和市场人员使用V4-Flash进行头脑风暴、撰写和编辑。它速度足够快,适合迭代式工作——撰写草稿、获取反馈、修改、重复——而不会出现大型模型在来回对话中令人沮丧的延迟。
在Playground上比较DeepSeek V4与其他模型
Playground让你可以访问来自多个提供商的模型。以下是V4的定位:
在编程任务上,V4-Pro是目前表现最出色的模型之一。它在Codeforces和SWE-bench上优于Claude Opus 4.6,并且根据具体任务与GPT-5.4不相上下。
在写作和遵循指令方面,Claude 仍然具有优势。如果你需要细腻的文风或严格遵守复杂的格式要求,Claude 模型往往更加可靠。
在通用知识和推理能力上,V4-Pro、GPT-5.4 和 Gemini 3.1 Pro 彼此之间的差距只有几个百分点。在大多数问题上,这种实际差异几乎难以察觉。
在日常任务的响应速度上,V4-Flash 难逢对手。它反应迅速,并且足以应对绝大多数日常问题。
Playground 的真正优势在于,你不必听信他人的说法。自己亲自对比一下吧,这些模型都在这里供你使用。
常见问题
DeepSeek V4 在 Felo Playground 上真的免费吗?
是的。V4-Pro 和 V4-Flash 都可以免费使用。你不需要创建账户或输入支付信息。
我需要安装任何东西吗?
不需要。Felo LLM Playground 完全在浏览器中运行,地址为 playground.felo.ai。在桌面端和移动端都可以使用。
我可以在除英语之外的语言中使用 DeepSeek V4 吗?
可以。V4 在英语、中文、日语、韩语等多种语言中表现出色。它经过了多语言重点训练。
Felo Playground 和 Felo Search 有什么区别?
Felo Search 将人工智能模型与实时网页搜索相结合,为您提供基于最新信息的答案,并附有引用。Playground 是一个直接的聊天界面——没有网页搜索,只有您和模型。需要最新事实时请使用 Search;想要推理、编程、写作或探索想法时请使用 Playground。
是否有使用限制?
Playground 可免费使用。在高流量期间可能会有特定的速率限制,但对于正常使用没有代币预算或每日上限。
立即体验 DeepSeek V4
DeepSeek V4 已在 Felo LLM Playground 上线。打开一个标签,选择模型,看看这个万亿参数的开源模型能为您的工作带来什么。