Claude Code 上下文視窗:如何避免工作階段中途遺失上下文

Claude Code 的上下文視窗限制了它一次能處理的資訊量。了解如何有效管理上下文視窗,以及如何解決跨工作階段遺失上下文的根本問題。
每個 Claude Code 工作階段都有一個上下文視窗——限制模型一次能處理多少資訊。了解它的運作方式,以及如何善加利用,會對 Claude 在複雜開發工作中的實用性產生顯著差異。
什麼是上下文視窗?
上下文視窗是 Claude 在單次工作階段中能處理的文字總量——以 token 為單位計算。這包括:
- 你的訊息
- Claude 的回覆
- 你要求它讀取的檔案
- 系統提示詞和工具輸出
現代 Claude 模型擁有大型上下文視窗——數十萬個 token。對於大多數開發工作階段,你不會達到上限。但對於涉及大型程式碼庫的長時間複雜工作階段,你可能會接近極限。
接近上下文限制的跡象:
- Claude 與它先前在工作階段中說過的內容相矛盾
- 它忘記你在開始時設定的限制條件
- 它重新詢問你已經提供過的資訊
- 回覆變得不太連貫或不夠具體
兩種上下文問題
開發者經常混淆兩個不同的問題。它們相關但需要不同的解決方案。
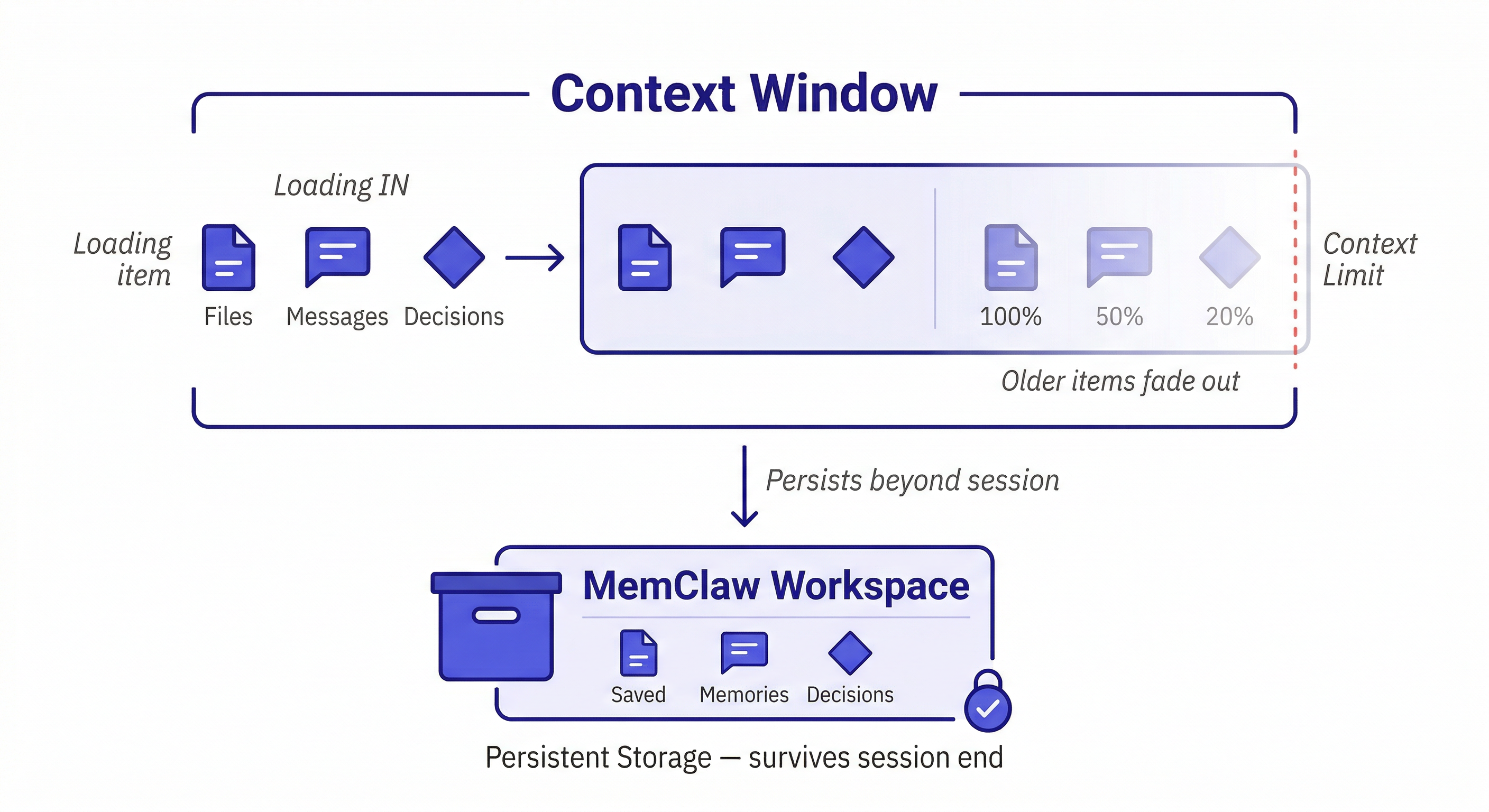
問題一——工作階段內的上下文遺失
對於包含大型檔案的超長工作階段,你可能會接近上下文限制。隨著新內容推入,舊內容被推出,Claude 開始「遺忘」對話中較早的部分。
解決方法:開始新的工作階段並重新載入相關上下文。讓每次工作階段專注於特定任務,而不是試圖在一次長工作階段中完成所有事情。
問題二——跨工作階段的上下文遺失
這是更常見也更痛苦的問題。每次新的工作階段都從空白的上下文視窗開始。之前工作階段的所有內容都消失了——架構決策、除錯歷史、你花了三小時解釋程式碼庫的那些內容。
解決方法:MemClaw 持久化工作區。這是本指南接下來要介紹的內容。
如何有效管理上下文視窗
只載入與當前任務相關的內容。
不要這樣做:
Read all the files in src/
應該這樣做:
Read src/middleware/auth.ts and src/lib/jwt.ts.
I'm working on extracting the JWT validation logic.
精準的上下文載入更快、佔用更少的視窗空間,並給 Claude 更多空間來推理特定問題。
使用 CLAUDE.md 存放穩定的上下文。
把不會隨工作階段改變的內容放在專案根目錄的 CLAUDE.md 檔案中:
# MyApp
Stack: Next.js 14, TypeScript, PostgreSQL
Auth: JWT in httpOnly cookies (security team requirement)
Conventions: Repository Pattern for DB access, React Query for async
Claude 在工作階段開始時會自動讀取這個檔案。這是不需要你每次重新解釋的免費上下文。
使用 MemClaw 存放演進中的上下文。
隨時間累積的決策、對話歷史、狀態更新、產出物——這些是 MemClaw 儲存的內容。這是 CLAUDE.md 無法處理的上下文,因為它會變化。
Load the MyApp workspace
Claude 讀取工作區後就知道目前的狀況——不只是靜態的架構,還有當前狀態、最近的決策,以及已經嘗試過並排除的方案。
上下文視窗 vs. 記憶:關鍵區別
可以這樣理解:
- 上下文視窗 = RAM ——快速、有限、工作階段結束時清除
- MemClaw 工作區 = 硬碟 ——持久化、可搜尋、工作階段結束後仍然存在
你希望重要的東西同時存在於兩者中。但你無法把所有東西都放進 RAM,也不想每次都把整個硬碟載入 RAM。
正確的模式:在工作階段開始時載入工作區上下文的精選子集(活的 README、最近的決策、當前狀態),然後在需要時按需載入特定的產出物。
Load the MyApp workspace
Show me the decisions we made about the payment integration
Claude 先載入工作區摘要,然後在被詢問時檢索特定的付款決策。這是對上下文視窗的高效利用。
實用的上下文管理模式
專注工作階段模式
每次工作階段以明確、狹窄的範圍開始:
Load the MyApp workspace
Today I'm working on the payment webhook handler.
Read src/webhooks/stripe.ts and let's fix the duplicate trigger issue.
範圍越窄 = 需要的上下文越少 = Claude 有更多空間深入推理特定問題。
檢查點模式
對於長時間工作階段,定期總結並重置:
Let's checkpoint. Summarize the key decisions we've made in this session,
then I'll start a fresh session with that summary loaded.
這可以防止超長工作階段中的上下文品質下降,並為你提供一份清晰的決策記錄。
工作階段結束儲存模式
在關閉工作階段之前:
Summarize the key decisions from this session and update the workspace status.
這就是工作區成長的方式。每次工作階段都增加一些內容。下一次工作階段比上一次更聰明。
上下文視窗大小真正重要的時候
對於大多數開發工作,上下文視窗足夠大,你不會達到上限。它在以下情況會成為真正的限制:
- 處理非常大的檔案(10,000 行以上)
- 在單次工作階段中讀取許多檔案
- 大量來回互動的超長工作階段
- 要求 Claude 一次分析整個大型程式碼庫
在這些情況下,解決方案都是一樣的:將工作拆分為專注的工作階段,使用 CLAUDE.md 存放穩定的上下文,使用 MemClaw 存放需要持久化的演進上下文。
開始使用 MemClaw
在 Claude Code 上安裝:
/plugin marketplace add Felo-Inc/memclaw
/plugin install memclaw@memclaw
export FELO_API_KEY="your-api-key-here"
為每個專案建立工作區:
Create a workspace called [Project Name]
每次工作階段開始時載入:
Load the [Project Name] workspace
上下文視窗問題不會消失——這是語言模型運作方式的根本限制。但透過專注的工作階段和持久化的工作區記憶,它不再是瓶頸。