Claude Opus 4.8 發佈:Anthropic 迄今為止最強大的模型

Anthropic 剛剛發佈了 Claude Opus 4.8 —— 更快、更誠實,並在代理型任務上表現更佳。以下是所有新功能,以及它對開發者的重要性。

Anthropic 本週發佈了 Claude Opus 4.8。這是他們迄今推出的最強大公開模型,在 Opus 4.7 的基礎上,於編碼、推理、代理任務與誠實度等方面全面提升。價格維持不變:每百萬輸入 tokens 為 5 美元,每百萬輸出 tokens 為 25 美元。
以下是這次的更新內容,以及它對開發者的重要意義。
與 Opus 4.7 相比的變化
以下是真正的改進重點:
1. 更佳的判斷與誠實度
Opus 4.8 不太容易做出無根據的主張,或讓程式碼錯誤被忽略。Anthropic 的測試顯示,它比前一代模型少約四倍讓自己的程式碼錯誤通過而未作提醒。當你信任模型能自主運作時,這樣的改進至關重要。
早期的測試者指出,它會提出正確問題、捕捉自身錯誤,並在計畫不合理時提出異議。
2. 更強的代理表現
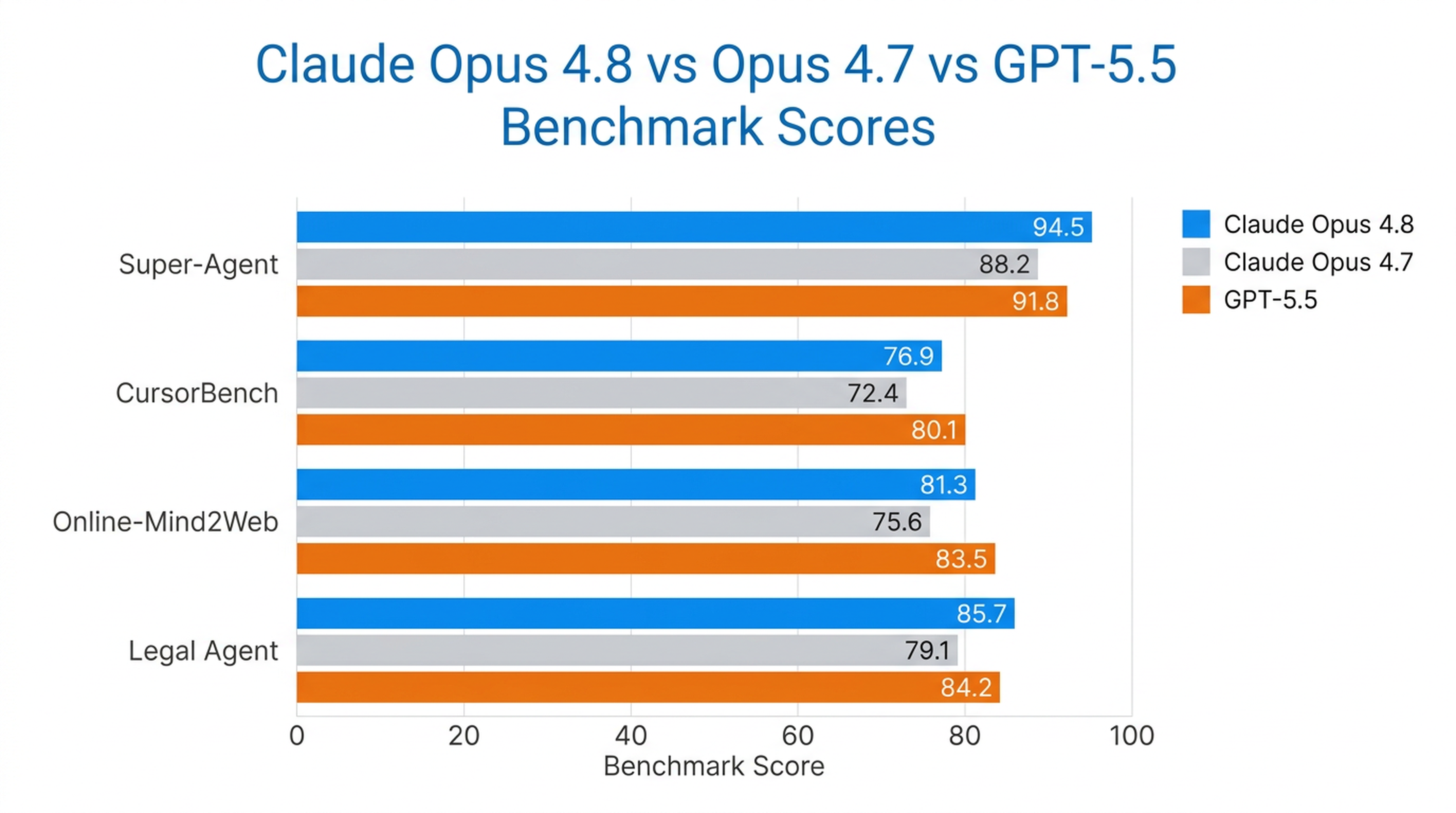
Opus 4.8 是唯一能在 Anthropic 的 Super-Agent 基準測試中完成所有案例端到端的模型,在同等成本下擊敗了先前的 Opus 模型與 GPT-5.5。在 CursorBench 上,它在各種努力層級中都優於過去版本,能用更少的工具調用步驟達到相同智慧水準。
此外,它也是 Anthropic 測試過的最強電腦操作與瀏覽器代理模型,在 Online-Mind2Web 測試中獲得 84% 的高分。
3. 更快、更高效的工具調用
這個模型更不容易略過任務需要的工具調用,這是 Opus 4.7 的已知痛點。更長的代理追蹤在壓縮上下文後也能更穩定地執行,減少偏離任務的情況。
4. 真正能「適應」的自適應思考
啟用自適應思考後,Opus 4.8 會在每回合決定是否需要推理。簡單查詢將直接回答,複雜問題則先進行推理再作答。與 Opus 4.7 相比,減少了浪費的 tokens。
值得注意的新功能
努力控制 —— 現已在所有方案上開放
模型選擇器旁新增一個控制項,讓使用者可選擇 Claude 在回應時投入的努力程度。Opus 4.8 預設為 high,也提供 extra 與 max 選項以應對更困難的任務。Claude Code 的速率限制已提升,以支援更多 token 用量。
快速模式 —— 2.5 倍速度、更低成本
快速模式現已在 Claude API 上以研究預覽形式開放給 Opus 4.8。它能提供高達 2.5 倍的輸出 tokens 每秒,成本則比先前模型低約三倍。
對話中途的系統訊息
Messages API 現在接受在 messages 陣列中插入 role: "system" 條目。你可以在任務進行中更新 Claude 的指令,而不會破壞提示快取——這在代理循環過程中許可權或上下文發生變化時特別有用。
降低提示快取的最小限度
可快取提示的最小長度已降至 1,024 tokens。先前在 Opus 4.7 上過短而無法快取的提示,如今無需修改程式碼即可建立快取項目。
真實世界基準測試
| 基準測試 | Opus 4.8 表現 |
|---|---|
| Super-Agent | 完成所有案例端到端(唯一做到的模型) |
| CursorBench | 在每個努力層級超越以往所有 Opus 模型 |
| Online-Mind2Web | 84%(測試中最強模型) |
| Legal Agent Benchmark | 最高分紀錄;首個整體突破 10% 門檻的模型 |

Opus 4.8 在長期自主運作的任務中表現最強 —— 包括編碼代理、研究代理、法律流程與企業知識工作。
價格 —— 與 Opus 4.7 相同
| 模式 | 輸入 | 輸出 |
|---|---|---|
| 標準 | $5 / 1M tokens | $25 / 1M tokens |
| 快速 | $10 / 1M tokens | $50 / 1M tokens |
與 Opus 4.7 相同的價格,卻擁有更佳效能。API 上的模型 ID 為 claude-opus-4-8。支援 1M token 上下文視窗與最多 128k 輸出 tokens。
下一步:Mythos 級模型
Anthropic 也暗示了一個「智力超越 Opus」的新模型系列。目前已有少數組織透過 Project Glasswing 使用 Claude Mythos Preview 進行網路安全工作。公司計劃在未來幾週內,待安全防護措施就緒後,將 Mythos 級模型開放給所有客戶。
為何模型多樣性很重要
如今幾乎每週都有新 AI 模型發佈。對建構在它們之上的開發者而言,真正的問題不是哪個模型「最好」,而是哪個模型適合哪個任務,以及如何在它們之間無縫切換。
這正是 Felo AI 要解決的問題。除了其利用先進模型進行即時回答的 AI 搜尋功能外,Felo 也提供一個 LLM Playground,讓你可在同一平台上呼叫、測試並比較多款頂尖模型的輸出。無需切換 API 金鑰,也不必在不同儀表板間來回。只要選擇模型、執行提示、即可查看表現。
無論你是在為工作流程評估模型,或只是想了解市面上的選擇,將這些都放在同一介面中,能讓比較過程輕鬆許多。
免費試用 Felo AI → https://felo.ai
本文也提供以下語言版本:English、简体中文、日本語、한국어、हिन्दी、Français、العربية、Русский、اردو、Bahasa Indonesia、Deutsch、Tiếng Việt、Türkçe、Italiano、ไทย、Español、বাংলা、Português。