🙆♀️Felo AI突破性成就:SimpleQA基準測試準確率91.2%,引領AI搜尋新標準
· 閱讀時間約 5 分鐘

Felo AI在SimpleQA基準測試中取得的突破性進展,憑藉91.2%的準確率領跑AI搜尋領域。了解跨語言查詢改寫等創新技術如何提升搜尋體驗。
以無與倫比的準確性革新AI搜尋引擎
我們激動地宣布,Felo 在 SimpleQA 基準測試中的最新表現超越了所有的競爭對手。SimpleQA 是OpenAI開發的,用於評估 AI 問答中事實準確性的關鍵測試。憑藉令人印象深刻的 91.2% 準確率,Felo Pro (快速模式) 為AI搜尋引擎樹立了新標杆,顯著超越了Perplexity和Gemini等競爭對手。
SimpleQA基準測試:AI 搜尋引擎的試金石
SimpleQA 基準測試由OpenAI開發,旨在衡量AI系統利用網路數據回答簡潔事實性問題的有效性。與傳統搜尋指標不同,SimpleQA 透過強調事實的精確性和可靠性,專注於減少 AI 系統中的幻覺問題——這是AI領域長期存在的挑戰。Felo 在這一基準測試中的卓越表現,彰顯了我們致力於為AI搜尋引擎提供最先進解決方案的決心。
測試方法:嚴格的評估框架
Felo 對 SimpleQA 基準測試的評估採用了標準化框架,以確保公平性和透明度。該方法包括以下步驟:
- 問題:將SimpleQA數據集中的問題直接提交給Felo。
- 答案生成:利用 Felo Pro (快速模式) 生成答案。
所有測試均使用相同的問題集和評分標準進行,這些標準在原始 SimpleQA 協議中定義,確保所有參與者之間的公平比較。
測試結果: Felo 達到行業領先的準確率
SimpleQA 基準測試的結果凸顯了 Felo 在 AI 智能搜尋領域的領先地位:
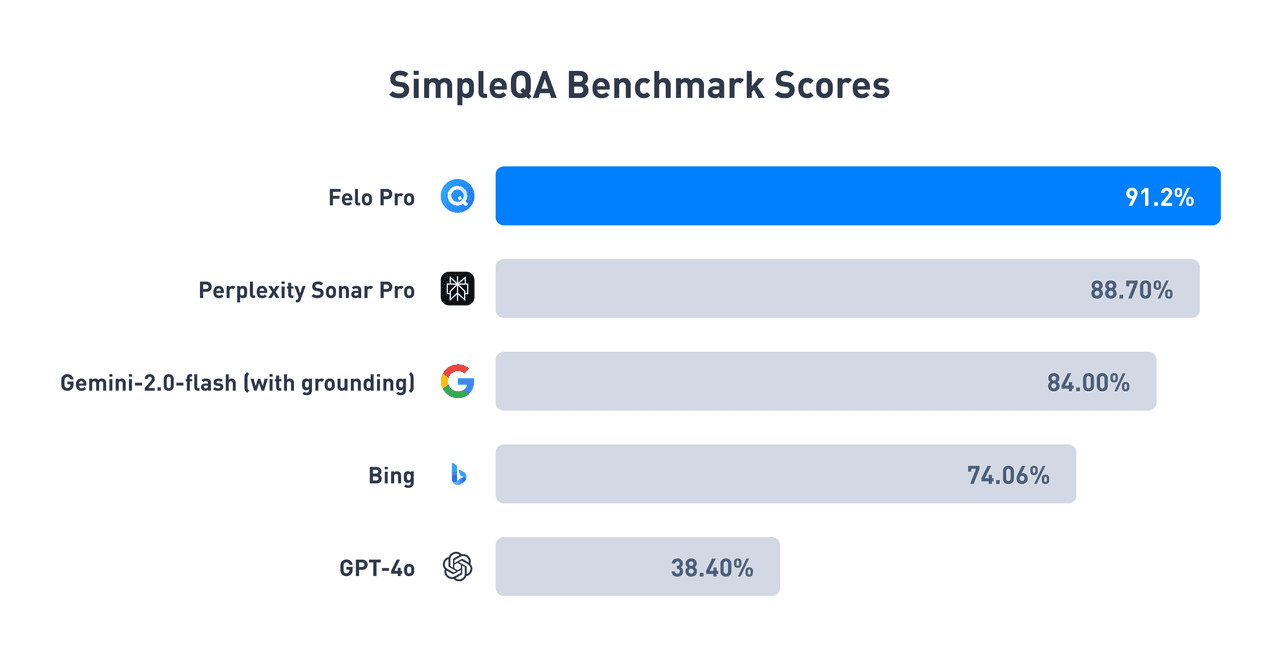
我們已開源 Felo 的測試結果,您可以訪問此處了解更多詳情。
Felo 的獨特之處是什麼?
Felo 在 SimpleQA 基準測試中的卓越表現歸功於其創新的架構和設計,關鍵的不同點包括:
- 先進的跨語言查詢改寫 Felo 能夠智能地將原始查詢分解為更細粒度的子查詢,甚至針對用戶問題選擇最合適的語言環境來進行檢索,這些子查詢針對傳統搜尋引擎和RAG系統的檢索進行了優化。這使得Felo能夠獲取更多相關的網頁。
- 混合索引技術 Felo 採用了關鍵詞和語義混合檢索技術,透過對網頁內容應用模型感知的語義壓縮,Felo 在去除無關噪聲的同時保留了關鍵的事實密度。這確保了LLM(大語言模型)僅接收到最相關和高品質的信息。
- 專注於檢索的訓練 與通用搜尋引擎不同,Felo 專門針對大語言模型處理信息的獨特方式進行排序模型調優,自研了7個LLM,從而提供更精準、結合語境的搜尋結果。