如何用 OpenClaw 建立知識庫(真正能持久保存的那種)

學習如何用 OpenClaw 和 MemClaw 建立一個會自動累積的知識庫。每次對話都讓 AI 更了解你的專案,不再從零開始。
大多數 OpenClaw 知識庫都是單向的:你把上下文丟進去,AI 用完就沒了,對話結束,一切歸零。下次開啟,又得從頭來過。
問題不在 AI,而在架構。一個只被讀取的知識庫永遠不會進步。真正有效的是讀寫循環——AI 在對話開始時讀取上下文,完成工作後,把決策、進度和產出物存回去。每次對話都累積一點,知識庫就會越來越強。
這篇指南教你如何為 OpenClaw 專案建立這樣的系統——一個跨對話持久保存、隨工作自動更新、且按專案隔離的活知識庫。
為什麼大多數 OpenClaw 設定無法累積
預設的 OpenClaw 設定有個根本問題:它會忘記。
OpenClaw 基於 Claude 運行,Claude 有上下文視窗(context window)——不是持久記憶。你在對話中告訴它的一切都存在那個視窗裡。對話結束,全部消失。下次對話從零開始。
這意味著每次對話都是單向交易。你投入上下文,AI 用完,什麼都不會留下。AI 永遠不會隨著時間對你的專案越來越了解。
常見的替代方案各有代價:
| 替代方案 | 問題 |
|---|---|
| 每次對話開始時貼上下文 | 花 5-10 分鐘,容易遺漏 |
| CLAUDE.md 檔案 | 單一檔案,沒有專案隔離,很快就亂了 |
| 手動筆記 | AI 無法自動讀取 |
| 每次重新解釋 | 浪費時間,容易不一致 |
這些方案都沒有閉合循環。它們是靜態輸入——你手動維護,慢慢過時,AI 永遠不會回饋。你真正需要的是一個系統,讓每次對話都累積:決策被記錄、狀態被更新、產出物被保存。下次對話就比上次更聰明。
正確的思維模型:活的 Wiki,不是靜態檔案
大多數人把 OpenClaw 知識庫想成一個檔案——一個大型 markdown 文件,AI 啟動時讀取。這比什麼都沒有好,但沒抓到重點。
靜態檔案不會累積。你寫一次,慢慢過時,又回到手動維護。還是單向交易。
活的 Wiki 不同:AI 既從中讀取,也向其寫入。每次對話遵循同樣的循環:
- 載入 Wiki(讀取當前狀態)
- 完成工作
- 把發現存回去(記錄決策、更新狀態、保存產出物)
下次對話更聰明。循環閉合了。
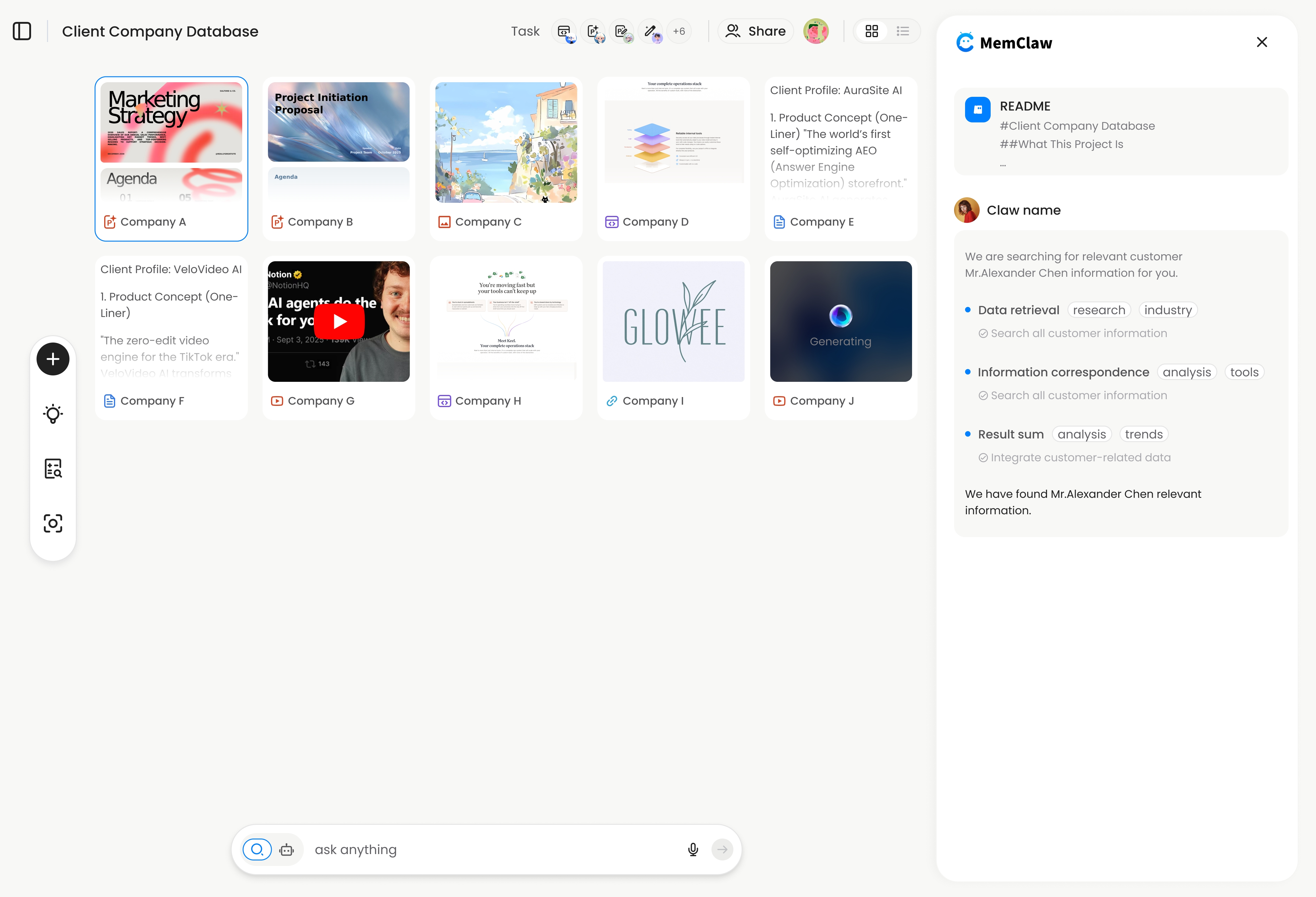
這就是 MemClaw 為 OpenClaw 實現的架構。每個專案有自己的隔離工作區——一個 AI 自動維護的結構化 Wiki:
- 背景上下文 — 專案是什麼、客戶是誰、關鍵限制
- 當前進度 — 進行中、已完成、被阻擋的項目
- 決策 — 架構選擇、已同意的方案、不需要重新討論的事項
- 產出物 — 文件、報告、網址、AI 產生的檔案
- 任務 — AI 工作時自動追蹤
這就是會累積的知識庫和不會累積的知識庫之間的差別:AI 不只是上下文的消費者——它也是貢獻者。每次執行都會回饋到知識庫。
為 OpenClaw 知識庫設定 MemClaw
MemClaw 以 OpenClaw skill 的形式安裝。設定不到兩分鐘。
步驟一:安裝 MemClaw
透過 Claude Code Plugin Marketplace:
/plugin marketplace add Felo-Inc/memclaw
/plugin install memclaw@memclaw
透過 OpenClaw 自然語言:
傳送給 OpenClaw:「請安裝 https://github.com/Felo-Inc/memclaw 並在安裝後使用 MemClaw。」
步驟二:設定 API Key
export FELO_API_KEY="your-api-key-here"
在 felo.ai/settings/api-keys 取得你的金鑰。
步驟三:建立第一個工作區
安裝完成後,直接告訴 OpenClaw:
建立一個叫做 Client Acme 的工作區
就這樣。MemClaw 會為該專案建立一個隔離的工作區。不需要 JSON 設定、不需要檔案路徑、不需要額外設定。
建立知識庫:該存什麼
好的 OpenClaw 知識庫不是資訊的垃圾場。它圍繞 AI 實際需要的內容來組織,讓你能接續上次的進度。
專案背景
這是基礎——專案是什麼、為誰做的、哪些限制重要。你加一次,很少需要改:
加到工作區:這是為 Acme Corp 做的 SaaS 儀表板。
他們 Q2 上線時程很緊。
技術棧是 Next.js + Supabase。
主要聯絡人是 Sarah ([email protected])。
決策
每次做出重要決策,就記錄下來。這能防止 AI 重新討論已經定案的問題:
把這個決策加到工作區:我們使用 JWT httpOnly cookies
做認證,因為 Acme 的資安團隊要求。不可更改。
加到工作區:我們決定不用 Redis 做快取——
對他們的團隊規模來說維運負擔太大。改用 Supabase
內建的快取。
當前狀態
工作時隨時更新。這是 AI 回到專案時最先讀取的內容:
更新工作區狀態:付款整合完成 80%。
Webhook 處理已完成。還需要處理付款重試失敗的邏輯。
產出物
連結 AI 產生的或與專案相關的任何內容:
保存到工作區:API 規格在 /docs/api-spec-v2.md
在新對話中恢復上下文
這就是回報所在。當你回到一個專案——即使隔了好幾週——你不需要重新簡報。只要載入工作區:
載入 Acme 工作區
MemClaw 在大約 8 秒內恢復完整的專案上下文。AI 知道:
- 專案是什麼、為誰做的
- 你上次做到哪裡
- 做了哪些決策
- 還有什麼在進行中
不用貼上。不用重新解釋。不用「等等,我們上次認證怎麼決定的?」
我付款整合做到哪了?
我們上個月認證怎麼決定的?
這些問題能得到準確答案,因為知識庫在整個專案過程中持續維護——不是從記憶中重建的。
管理多個專案而不混淆上下文
這是知識庫最重要的使用場景。
如果你同時跑五個專案,只用一個 CLAUDE.md 檔案或完全沒有記憶系統,上下文就會混淆。客戶 A 的需求出現在客戶 B 的對話裡。AI 在處理一個專案時引用了另一個專案的決策。你花時間糾正它,而不是推進工作。
有了工作區範圍的知識庫,每個專案完全隔離:
載入 Acme 工作區
→ AI 只有 Acme 的上下文
載入 Beta Corp 工作區
→ AI 切換到 Beta Corp 的上下文。Acme 完全不在畫面中。
這就是專案範圍 OpenClaw 知識庫的核心價值:不只是持久保存,更是隔離。
跨 AI 代理相容性
使用 MemClaw 建立 OpenClaw 知識庫有個被低估的好處:同一個工作區可以跨代理使用。
如果你同時使用 OpenClaw 和 Claude Code,它們共享同一個工作區。在 OpenClaw 對話中記錄的決策,在同一專案的 Claude Code 對話中也能取用。你的知識庫不綁定在某個 AI 代理上——它綁定在專案上。
MemClaw 支援 OpenClaw、Claude Code、Gemini CLI 和 Codex——全部讀寫同一個工作區。如果你根據任務切換工具,或者團隊中不同人使用不同的 AI 代理,這一點很重要。
# 在 OpenClaw 中——做研究,保存發現
把那份競品分析保存到工作區
# 之後,在 Claude Code 中——接續上次的進度
載入 Acme 工作區
給我看我們做的競品分析
不用在工具之間複製貼上。沒有資訊孤島。
實際工作流程:自由工作者管理 6 個客戶
以下是同時管理多個客戶專案的實際情況。
舊方式(沒有知識庫):
- 週一:向 OpenClaw 簡報客戶 A 的需求(8 分鐘)
- 週二:切換到客戶 B,從頭簡報(6 分鐘)
- 週三:回到客戶 A——「等等,我們 API 架構怎麼決定的?」
- 週五:客戶 C 要求更新——翻遍聊天記錄重建狀態
有了工作區範圍的知識庫:
# 週一早上
載入客戶 A 工作區
→ AI:「客戶 A 是 Acme 儀表板專案。上次對話你完成了
認證流程。接下來是付款整合——webhook 處理已完成,
重試邏輯還在進行中。」
# 週二
載入客戶 B 工作區
→ AI:「客戶 B 是 Beta Corp 行動應用程式。你正在進行
通知系統的衝刺。Sarah 上週批准了推播通知的設計。」
# 週三,回到客戶 A
我們 API 架構怎麼決定的?
→ AI:「你決定用 REST 而不是 GraphQL,因為 Acme 的後端
團隊不熟悉 GraphQL。記錄於 3 月 15 日。」
知識庫負責記憶。你負責工作。
這就是 MemClaw 的設計場景:不是一個專案的完美記憶,而是五個專案同時運行,上下文隔離就是高效對話和不斷重新簡報之間的差別。
讓知識庫長期保持有用
知識庫的品質取決於你放了什麼進去。幾個習慣能防止它過時:
做決策時就記錄,不要事後補。 當你決定某件事——架構選擇、範圍變更、客戶偏好——立刻加到工作區。一週後試圖從記憶中重建決策是不可靠的。
每次對話結束時更新狀態。 一行就夠:
更新工作區狀態:完成重試邏輯,明天開始做
管理後台
立刻保存產出物。 如果 AI 產生了報告、分析或規格,在對話結束前保存:
把那份定價分析保存到工作區
不要過度設計結構。 MemClaw 處理組織。你只需要告訴它什麼重要。自然語言就夠了——不需要模板、不需要必填欄位。
目標不是完美的知識庫。而是一個夠好的知識庫,讓你永遠不需要重新向 AI 解釋已經討論過的事情。
成熟的 OpenClaw 知識庫長什麼樣
持續使用幾週後,累積效果就會顯現。
第一週:你還在手動添加上下文——專案背景、初始決策、第一批狀態更新。AI 有用但還不能自給自足。
第三週:工作區有 15-20 條記錄的決策、清晰的狀態軌跡、和不斷增長的產出物庫。AI 開始從知識庫回答問題,而不是要求你重新解釋。
第六週以上:新對話開始時 AI 已經就位。它知道專案歷史、限制條件、已經定案不再討論的決策。你花零時間重新簡報,更多時間在實際工作上。
成熟的工作區通常包含:
- 專案 README — 背景、目標、限制、關鍵聯絡人
- 決策日誌 — 15-20+ 條記錄的決策及理由
- 狀態軌跡 — 逐次對話的進度更新
- 產出物 — 規格、報告、分析、關鍵文件
- 任務歷史 — 已完成、待處理、被降低優先級的項目及原因
會累積的知識庫和不會累積的知識庫之間的差別歸結為一個習慣:把答案存回去。每個決策、每次狀態更新、每個產出物——如果存進工作區,就永遠可用。如果留在聊天中,對話結束就消失了。
開始使用
讀寫循環理論上很簡單:載入上下文、完成工作、把發現存回去。困難的部分是有基礎設施讓「存回去」足夠輕鬆,讓你每次對話都真的會做。
這就是 MemClaw 處理的。安裝它,為每個專案建立工作區,循環就自動運行——AI 在對話開始時讀取上下文,工作時保存決策、狀態和產出物。
- 安裝 MemClaw(memclaw.me)
- 為每個進行中的專案建立工作區
- 工作時記錄決策和狀態更新
- 每次對話開始時載入工作區
累積效果立刻開始。到第三、四次對話,你會發現 AI 已經知道你不需要重新解釋的事情。
常見問題
MemClaw 可以搭配自架的 OpenClaw 使用嗎? 可以。MemClaw 連接 Felo 的 API 進行儲存,所以不管你怎麼運行 OpenClaw 都能使用。
可以和團隊共享工作區嗎? 可以。MemClaw 支援團隊共享——邀請隊友加入工作區,他們就能取得相同的上下文。
如果不載入工作區會怎樣? OpenClaw 正常運行,沒有任何工作區上下文。MemClaw 只在你明確載入或引用工作區時才啟動。
我的專案資料是私密的嗎? 工作區資料儲存在 Felo 的基礎設施中。詳情請見 felo.ai。